Python聚类算法之基本K均值实例详解
本文实例讲述了Python聚类算法之基本K均值运算技巧。分享给大家供大家参考,具体如下:
基本K均值 :选择 K 个初始质心,其中 K 是用户指定的参数,即所期望的簇的个数。每次循环中,每个点被指派到最近的质心,指派到同一个质心的点集构成一个。然后,根据指派到簇的点,更新每个簇的质心。重复指派和更新操作,直到质心不发生明显的变化。
# scoding=utf-8
import pylab as pl
points = [[int(eachpoint.split("#")[0]), int(eachpoint.split("#")[1])] for eachpoint in open("points","r")]
# 指定三个初始质心
currentCenter1 = [20,190]; currentCenter2 = [120,90]; currentCenter3 = [170,140]
pl.plot([currentCenter1[0]], [currentCenter1[1]],'ok')
pl.plot([currentCenter2[0]], [currentCenter2[1]],'ok')
pl.plot([currentCenter3[0]], [currentCenter3[1]],'ok')
# 记录每次迭代后每个簇的质心的更新轨迹
center1 = [currentCenter1]; center2 = [currentCenter2]; center3 = [currentCenter3]
# 三个簇
group1 = []; group2 = []; group3 = []
for runtime in range(50):
group1 = []; group2 = []; group3 = []
for eachpoint in points:
# 计算每个点到三个质心的距离
distance1 = pow(abs(eachpoint[0]-currentCenter1[0]),2) + pow(abs(eachpoint[1]-currentCenter1[1]),2)
distance2 = pow(abs(eachpoint[0]-currentCenter2[0]),2) + pow(abs(eachpoint[1]-currentCenter2[1]),2)
distance3 = pow(abs(eachpoint[0]-currentCenter3[0]),2) + pow(abs(eachpoint[1]-currentCenter3[1]),2)
# 将该点指派到离它最近的质心所在的簇
mindis = min(distance1,distance2,distance3)
if(mindis == distance1):
group1.append(eachpoint)
elif(mindis == distance2):
group2.append(eachpoint)
else:
group3.append(eachpoint)
# 指派完所有的点后,更新每个簇的质心
currentCenter1 = [sum([eachpoint[0] for eachpoint in group1])/len(group1),sum([eachpoint[1] for eachpoint in group1])/len(group1)]
currentCenter2 = [sum([eachpoint[0] for eachpoint in group2])/len(group2),sum([eachpoint[1] for eachpoint in group2])/len(group2)]
currentCenter3 = [sum([eachpoint[0] for eachpoint in group3])/len(group3),sum([eachpoint[1] for eachpoint in group3])/len(group3)]
# 记录该次对质心的更新
center1.append(currentCenter1)
center2.append(currentCenter2)
center3.append(currentCenter3)
# 打印所有的点,用颜色标识该点所属的簇
pl.plot([eachpoint[0] for eachpoint in group1], [eachpoint[1] for eachpoint in group1], 'or')
pl.plot([eachpoint[0] for eachpoint in group2], [eachpoint[1] for eachpoint in group2], 'oy')
pl.plot([eachpoint[0] for eachpoint in group3], [eachpoint[1] for eachpoint in group3], 'og')
# 打印每个簇的质心的更新轨迹
for center in [center1,center2,center3]:
pl.plot([eachcenter[0] for eachcenter in center], [eachcenter[1] for eachcenter in center],'k')
pl.show()
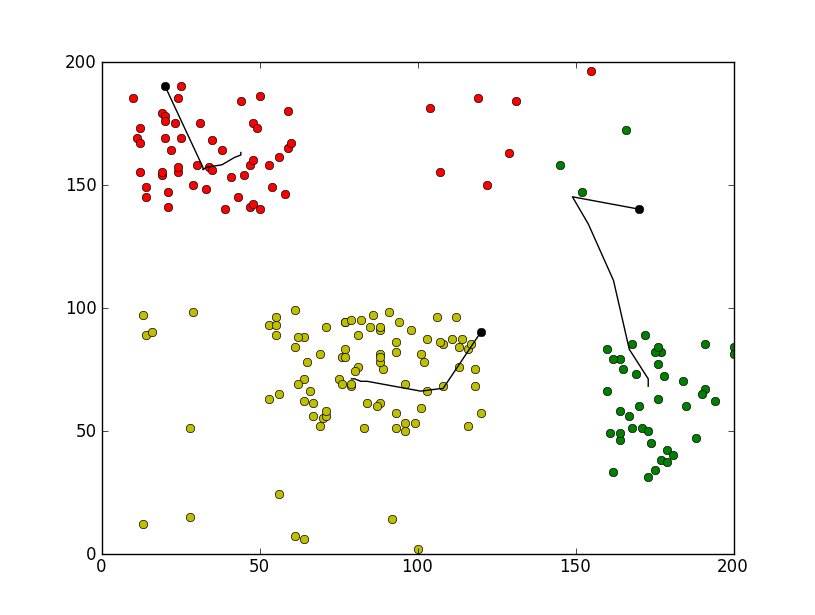
运行效果截图如下:

希望本文所述对大家Python程序设计有所帮助。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330