



2022-07-28
阅读量:
4029
去量纲/消除量纲/归一化 怎么理解?
为什么要去量纲?
进行变量重要性排序(选择对因变量影响最大的自变量)或特征筛选(用于提供后续模型精度等)时,不同的变量单位不同,因此数值差异极大。例如1cm和1kg等。
什么是去量纲?
数据分析的本质是数值,去量纲就是去除掉单位对数值的影响。使得所有的变量都在同等的水平上,才能“公平”的参与后续处理。
常见的去量纲化方法:
注:!此处去除掉网上将z-score方法成为标准化,将min-max称为归一化等叫法。直接用名称可以除去翻译的语义导致的误解,也能去除被必要的区分。
(1)初值化:使用序列数据中的初始值作为除数,消除不同变量之间的量级或单位差异。其结果由样本初始值决定,可以消除不同变量间大量级的差异,处理后数据接近1左右。方便简单,但是随机性较高。
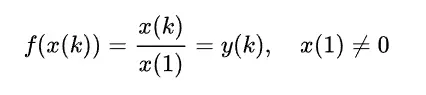
(2)均值化:每个变量除以该变量的均值。可以去除量纲差异,相除后接近1左右。
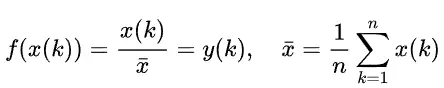
(3)min-max变换:通过线性变换去除量纲影响。映射结果在[0,1]之间,但容易受到异常值的影响。
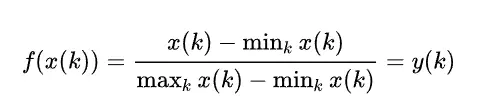
好处1:对于原始变异值不大的数据,用该方法可以放大差异。
如:1.70 1.71 1.72 1.73,min-max处理后为0,0.33.0.67,1。
好处2:可以维持稀疏矩阵中的0.
(4)极差最大值变换:也依赖于最小值和最大值。
(5)Z-score变换:zero mean normalization:减去均值,除以标准差。
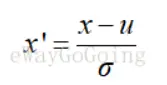
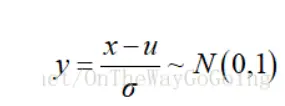
处理后的数据均值为0,方差接近1,分布接近正态分布。
好处:该方法更适用于涉及到距离关系的应用中,通过该处理后,对数据由于量纲引起的差异去除的更为彻底,因此对于精确的变量差异,如距离计算中,使用该方法更好,例如:相似度,PCA,聚类分析等。 而min-max相当于保存了原始数据标准差所能代表的潜在权重关系。
总结:
具体用啥看情况决定。例如在灰色关联度分析中用均值化,PCA用z-score。
后续自己各种处理中用什么会回来填坑。 作者:大专厂妹の奋斗生活 https://www.bilibili.com/read/cv17032876/ 出处:bilibili
 0.0000
0.0000
 0
0
 0
0

 关注作者
关注作者
 收藏
收藏

评论(0)
 发表评论
发表评论
暂无数据







推荐帖子
CDA持证人阿涛哥
2024-10-15
0条评论
CDA持证人阿涛哥
2024-04-17
1条评论
CDA138749
2024-04-01
0条评论