小编今天给大家分享的文章又是关于OpenCV的。OpenCV是目前最有名的一款计算机视觉软件库了,将OpenCV吃透对于我们计算机视觉以及机器学习甚至是AI人工智能方面都有很大帮助。下面,就跟小编一起来看如何使用OpenCV实现图像增强吧。
以下文章来源: 小白学视觉
作者:努比
本期将介绍如何通过图像处理从低分辨率/模糊/低对比度的图像中提取有用信息。
下面让我们一起来探究这个过程:
首先我们获取了一个LPG气瓶图像,该图像取自在传送带上运行的仓库。我们的目标是找出LPG气瓶的批号,以便更新已检测的LPG气瓶数量。
步骤1:导入必要的库
import cv2
import numpy as np
import matplotlib.pyplot as plt
步骤2:加载图像并显示示例图像。
img= cv2.imread('cylinder1.png')
img1=cv2.imread('cylinder.png')
images=np.concatenate(img(img,img1),axis=1)
cv2.imshow("Images",images)
cv2.waitKey(0)
cv2.destroyAllWindows()
LPG气瓶图片(a)批次-D26(b)批次C27
该图像的对比度非常差。我们几乎看不到批号。这是在灯光条件不足的仓库中的常见问题。接下来我们将讨论对比度受限的自适应直方图均衡化,并尝试对数据集使用不同的算法进行实验。
步骤3:将图像转换为灰度图像
gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray_img1=cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
步骤4:找到灰度图像的直方图后,寻找强度的分布。
hist=cv2.calcHist(gray_img,[0],None,[256],[0,256])hist1=cv2.calcHist(gray_img1,[0],None,[256],[0,256])plt.subplot(121)plt.title("Image1")plt.xlabel('bins')plt.ylabel("No of pixels")plt.plot(hist)plt.subplot(122)plt.title("Image2")plt.xlabel('bins')plt.ylabel("No of pixels")plt.plot(hist1)plt.show()
步骤5:现在,使用cv2.equalizeHist()函数来均衡给定灰度图像的对比度。cv2.equalizeHist()函数可标准化亮度并增加对比度。
gray_img_eqhist=cv2.equalizeHist(gray_img)gray_img1_eqhist=cv2.equalizeHist(gray_img1)hist=cv2.calcHist(gray_img_eqhist,[0],None,[256],[0,256])hist1=cv2.calcHist(gray_img1_eqhist,[0],None,[256],[0,256])plt.subplot(121)plt.plot(hist)plt.subplot(122)plt.plot(hist1)plt.show()
步骤6:显示灰度直方图均衡图像
eqhist_images=np.concatenate((gray_img_eqhist,gray_img1_eqhist),axis=1)
cv2.imshow("Images",eqhist_images)
cv2.waitKey(0)
cv2.destroyAllWindows()
灰度直方图均衡
让我们进一步深入了解CLAHE
步骤7:
对比度有限的自适应直方图均衡
该算法可以用于改善图像的对比度。该算法通过创建图像的多个直方图来工作,并使用所有这些直方图重新分配图像的亮度。CLAHE可以应用于灰度图像和彩色图像。有2个参数需要调整。
1. 限幅设置了对比度限制的阈值。默认值为40
2. tileGridsize设置行和列中标题的数量。在应用CLAHE时,为了执行计算,图像被分为称为图块(8 * 8)的小块。
clahe=cv2.createCLAHE(clipLimit=40)
gray_img_clahe=clahe.apply(gray_img_eqhist)
gray_img1_clahe=clahe.apply(gray_img1_eqhist)
images=np.concatenate((gray_img_clahe,gray_img1_clahe),axis=1)
cv2.imshow("Images",images)
cv2.waitKey(0)
cv2.destroyAllWindows()
步骤8:
门槛技术
阈值处理是一种将图像划分为前景和背景的简单但有效的方法。如果像素强度小于某个预定义常数(阈值),则最简单的阈值化方法将源图像中的每个像素替换为黑色像素;如果像素强度大于阈值,则使用白色像素替换源像素。阈值的不同类型是:
cv2.THRESH_BINARY
cv2.THRESH_BINARY_INV
cv2.THRESH_TRUNC
cv2.THRESH_TOZERO
cv2.THRESH_TOZERO_INV
cv2.THRESH_OTSU
cv2.THRESH_TRIANGLE
尝试更改阈值和max_val以获得不同的结果。
th=80
max_val=255
ret, o1 = cv2.threshold(gray_img_clahe, th, max_val, cv2.THRESH_BINARY)
cv2.putText(o1,"Thresh_Binary",(40,100),cv2.FONT_HERSHEY_SIMPLEX,2,(255,255,255),3,cv2.LINE_AA)
ret, o2 = cv2.threshold(gray_img_clahe, th, max_val, cv2.THRESH_BINARY_INV)
cv2.putText(o2,"Thresh_Binary_inv",(40,100),cv2.FONT_HERSHEY_SIMPLEX,2,(255,255,255),3,cv2.LINE_AA)
ret, o3 = cv2.threshold(gray_img_clahe, th, max_val, cv2.THRESH_TOZERO)
cv2.putText(o3,"Thresh_Tozero",(40,100),cv2.FONT_HERSHEY_SIMPLEX,2,(255,255,255),3,cv2.LINE_AA)
ret, o4 = cv2.threshold(gray_img_clahe, th, max_val, cv2.THRESH_TOZERO_INV)
cv2.putText(o4,"Thresh_Tozero_inv",(40,100),cv2.FONT_HERSHEY_SIMPLEX,2,(255,255,255),3,cv2.LINE_AA)
ret, o5 = cv2.threshold(gray_img_clahe, th, max_val, cv2.THRESH_TRUNC)
cv2.putText(o5,"Thresh_trunc",(40,100),cv2.FONT_HERSHEY_SIMPLEX,2,(255,255,255),3,cv2.LINE_AA)
ret ,o6= cv2.threshold(gray_img_clahe, th, max_val, cv2.THRESH_OTSU)
cv2.putText(o6,"Thresh_OSTU",(40,100),cv2.FONT_HERSHEY_SIMPLEX,2,(255,255,255),3,cv2.LINE_AA)
final=np.concatenate((o1,o2,o3),axis=1)
final1=np.concatenate((o4,o5,o6),axis=1)
cv2.imwrite("Image1.jpg",final)
cv2.imwrite("Image2.jpg",final1)
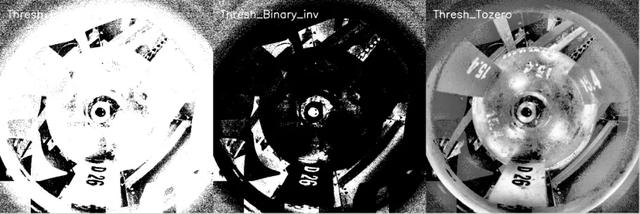
Thresh_Binary_inv,Thresh_Binary_inv,Thresh_Tozero
Thresh_Tozero_inv,Thresh_trunc,Thresh_OSTU
步骤9:自适应阈值
在上一节中,我们使用了全局阈值来应用cv2.threshold()。如我们所见,由于图像不同区域的照明条件不同,因此获得的结果不是很好。在这些情况下,您可以尝试自适应阈值化。在OpenCV中,自适应阈值处理由cv2.adapativeThreshold()函数执行
此功能将自适应阈值应用于src阵列(8位单通道图像)。maxValue参数设置dst图像中满足条件的像素的值。adaptiveMethod参数设置要使用的自适应阈值算法。
cv2.ADAPTIVE_THRESH_MEAN_C:将T(x,y)阈值计算为(x,y)的blockSize x blockSize邻域的平均值减去C参数。
cv2.ADAPTIVE_THRESH_GAUSSIAN_C:将T(x,y)阈值计算为(x,y)的blockSize x blockSize邻域的加权总和减去C参数。
blockSize参数设置用于计算像素阈值的邻域的大小,它可以取值3、5、7等。
C参数只是从均值或加权均值中减去的常数(取决于adaptiveMethod参数设置的自适应方法)。通常,此值为正,但可以为零或负。
gray_image = cv2.imread('cylinder1.png',0)
gray_image1 = cv2.imread('cylinder.png',0)
thresh1 = cv2.adaptiveThreshold(gray_image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
thresh2 = cv2.adaptiveThreshold(gray_image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 31, 3)
thresh3 = cv2.adaptiveThreshold(gray_image, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 13, 5)
thresh4 = cv2.adaptiveThreshold(gray_image, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 31, 4)
thresh11 = cv2.adaptiveThreshold(gray_image1, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
thresh21 = cv2.adaptiveThreshold(gray_image1, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 31, 5)
thresh31 = cv2.adaptiveThreshold(gray_image1, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21,5 )
thresh41 = cv2.adaptiveThreshold(gray_image1, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 31, 5)
final=np.concatenate((thresh1,thresh2,thresh3,thresh4),axis=1)
final1=np.concatenate((thresh11,thresh21,thresh31,thresh41),axis=1)
cv2.imwrite('rect.jpg',final)
cv2.imwrite('rect1.jpg',final1)

自适应阈值
自适应阈值
步骤10:OTSU二值化
Otsu的二值化算法,在处理双峰图像时是一种很好的方法。双峰图像可以通过其包含两个峰的直方图来表征。Otsu的算法通过最大化两类像素之间的方差来自动计算将两个峰分开的最佳阈值。等效地,最佳阈值使组内差异最小化。Otsu的二值化算法是一种统计方法,因为它依赖于从直方图得出的统计信息(例如,均值,方差或熵)
gray_image = cv2.imread('cylinder1.png',0)
gray_image1 = cv2.imread('cylinder.png',0)
ret,thresh1 = cv2.threshold(gray_image,0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
ret,thresh2 = cv2.threshold(gray_image1,0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
cv2.imwrite('rect.jpeg',np.concatenate((thresh1,thresh2),axis=1))
OTSU二值化
现在,我们已经从低对比度的图像中清楚地识别出批号。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330