


2023-10-26
阅读量:
4187
一文详解多模态大模型发展及高频因子计算加速GPU算力 | 英伟达显卡被限,华为如何力挽狂澜?
★深度学习、机器学习、多模态大模型、深度神经网络、高频因子计算、GPT-4、预训练语言模型、Transformer、ChatGPT、GenAI、L40S、A100、H100、A800、H800、华为、GPU、CPU、英伟达、NVIDIA、卷积神经网络、Stable Diffusion、Midjourney、Faster R-CNN、CNN
随着人工智能技术的快速发展,多模态大模型在各个领域中的应用越来越广泛。多模态大模型是指能够处理多种不同类型的数据,如文本、图像、音频和视频等大型神经网络模型。随着互联网和物联网的普及,多模态大模型在许多领域中都得到了广泛的应用。例如,在医疗领域中,可以通过分析医学图像和病历等数据,辅助医生进行疾病诊断和治疗方案制定;在智能交通领域中,可以通过分析交通图像和交通流量等数据,辅助交通管理部门进行交通规划和调度。
在大规模计算中,高频因子计算是一个非常耗时的过程。GPU作为一种专门用于大规模并行计算的芯片,具有高效的计算能力和高速的内存带宽,因此被广泛应用于高频因子计算中。通过将计算任务分配给多个GPU,可以显著提高计算速度和效率。
近年来,全球范围内的芯片禁令不断升级,给许多企业和科研机构带来了很大的困扰,需要在技术层面进行创新和突破。一方面,可以探索使用国产芯片和其他不受限制的芯片来替代被禁用的芯片;另一方面,可以通过优化算法和架构等方法来降低对特定芯片的依赖程度。
为了更好地推进多模态大模型的研究和应用,蓝海大脑大模型训练平台基于自主研发的分布式计算框架和算法库,可以高效地进行大规模训练和推断。同时,该平台还提供了丰富的数据处理、模型调试和可视化工具,可以帮助用户快速构建、训练和部署多模态大模型。
本文将介绍多模态大模型的综述,并探讨高频因子计算的GPU加速方法,以及探讨在当前芯片禁令升级的情况下,如何继续推进大模型训练平台的发展。
多模态大模型综述
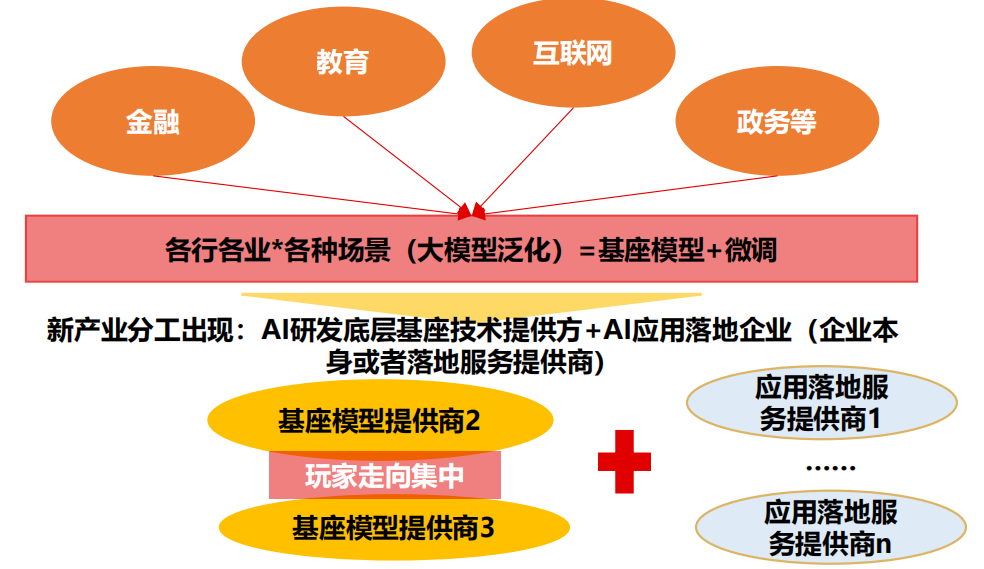
一、多模态模型重塑 AI 技术范式
多模态模型融合了语言和图像模态,将文本理解和思维链能力投射到图像模态上,赋予模型图像理解和生成功能。通过预训练和调参的方式,颠覆了传统机器视觉小模型的定制化业务模式,大幅提高了模型的泛用性。多模态模型旨在模拟人类大脑处理信息的方式,从大语言模型到图像-文本模型,再泛化到其他模态的细分场景模型。与大语言模型相比,多模态模型扩大了信息输入规模,提高了信息流密度,突破了语言模态的限制;与传统机器学习模型相比,多模态模型具有更高的可迁移性,并能进行内容生成和逻辑推理。
1、多模态模型通过高技术供给重塑 AI 技术范式
多模态模型目前主要是文本-图像模型。模态是指表达或感知事物的方式,每一种信息的来源或形式都可以称为一种模态。例如,人类有触觉、听觉和视觉等感官,信息的媒介有语音、视频、文字等,每一种都可以称为一种模态。目前已经推出几十种基础模型,如Clip、ViT和GPT-4等,并且已经出现诸如Stable Diffusion和Midjourney这样的应用。因此,多模态大模型领域目前以文本-图像大模型为主,未来随着AI技术的发展,包含更多模态的模型有望陆续推出。

LDM 通过文本描述生成简短视频
多模态模型融合语言和图像模态,将文本理解和思维链能力应用于图像模态,为模型赋予图像理解和生成功能。多模态技术通过预训练和调参颠覆了传统机器视觉小模型的定制化业务模式,大幅提高了模型的泛用性。从商业模式来看,产业话语权逐渐从应用端转向研发端,改变了由客户主导市场的项目制,转向由技术定义市场。
多模态模型有望颠覆 AI 视觉的商业模式
多模态模型的核心目标是以人类大脑处理信息的方式进行模拟。语言和图像模态本质上是信息的载体,可类比为接受不同传感器的感知方式。人类通过整合来自不同感官的信息从而理解世界,同样,多模态模型将各种感知模态结合,以更全面、综合的方式理解和生成信息,并实现更丰富的任务和应用。
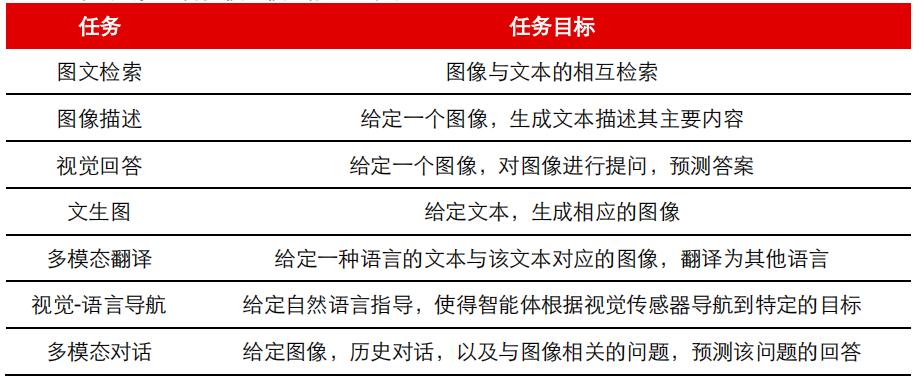
当前图像-语言多模态模型的典型任务
多模态模型的技术路径是从图像-语言模态融合扩展到三种以上模态的融合。
语言模态训练为模型提供逻辑思维能力与信息生成能力,这两种能力是处理信息的基础。视觉模态具有高信息流密度且更贴近现实世界,因此成为多模态技术的首选信息载体。具备视觉能力的模型具有更高的实用性,可广泛应用于现实世界的各个方面。在此基础上,模型可以继续发展动作、声音、触觉等不同模态,以应对更为复杂的场景。

多模态模型技术发展路径
2、与大语言模型对比:抬升模型能力天花板
多模态大模型通过预训练+调参,大幅提升信息输入规模和信息流密度,打破语言模态的限制。大模型能力的提升得益于对信息的压缩与二次处理,多模态模型在处理图片和文本数据时,能够提高模型能力的上限。视觉模态是直接从现实世界获取的初级模态,数据源丰富且成本低廉,相比语言模态更直观易于理解。多模态模型不仅提高信息流密度,还突破语言模态不同语种的限制。在数据资源方面,国外科技巨头具有优势,如ChatGPT等大模型的数据训练集以英文语料为主,英文文本在互联网和自然科学论文索引中的数量具有优势。相比之下,图像模态是可以直接获取的一级模态,因此多模态的数据突破了语言种类限制。

图像模态是初级模态,可以直接从现实世界获得
多模态模型提高信息交互效率,降低应用门槛。大语言模型需要输入文本Prompt来触发模型文本回答,但编写准确的Prompt需要一定技能和思考。纯文本交互方式有时受限于文本表达能力,难以传达复杂概念或需求。相比之下,多模态模型图像交互方式使用门槛更低,更加直观。用户可直接提供图像或视觉信息,提高信息交互效率。多模态模型不同模态信息可以相互印证,从而提高模型推理过程的鲁棒性。
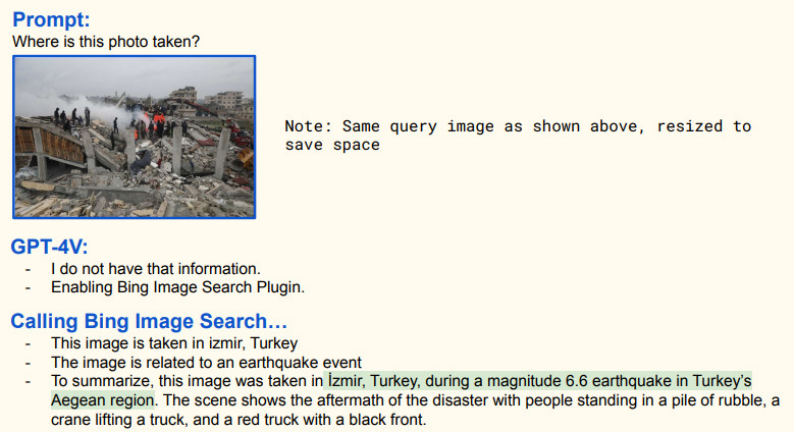
直接上传图片至 GPT-4 比文字描述简单快捷
3、与传统机器视觉模型对比:拓宽应用边界,提升价值量
在预训练大模型出现之前,机器视觉技术(CV)是深度学习领域的一个重要分支,深度学习算法以卷积神经网络(CNN)为主。CNN 在图像上应用卷积操作,从局部区域提取特征。具体而言,CNN 算法会把一张图像切割成若干个小方块(如 3X3),将每一个小方块转化成单独的向量,先对全图像在 3X3 的 9 个方块范围计算卷积得到特征值(CNN 算法),这些特征映射捕捉不同的局部信息。然后对全图像在 2X2 的 4 个小方块范围内取最大值或平均值(池化算法)。最后经过多轮特征值提取与池化后,会将矩阵投喂给神经网络,用于最终的物体识别、图像分割等任务。
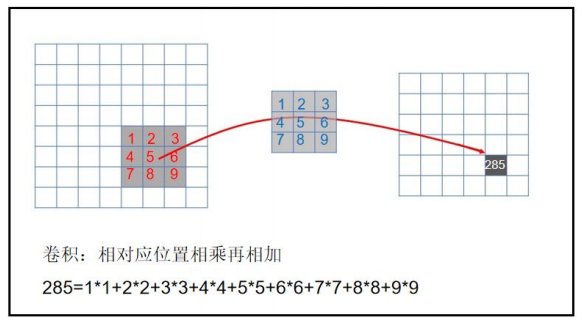
CNN 算法提取图像的特征值
传统机器视觉模型只能处理图像数据,无法处理文本信息,也不具备逻辑推理能力。由于这些模型仅对图像数据进行表征编码,通过提取视觉特征如颜色、纹理和形状等来识别图像,没有涉及语言模态。
多模态模型具有更高的可迁移性和更广泛的应用范围。尽管CNN在机器视觉领域被广泛使用,但它们大多是针对特定任务设计的,因此在处理不同任务或数据集时,其可迁移性受到限制。多模态大模型通过联合训练各种感知模态如图像、文本和声音等,能够学习到更通用和抽象的特征表示。这种预训练使得多模态模型在各种应用中都具备强大的基础性能,因此具有更高的泛化能力。
多模态模型还具有图像生成和逻辑推理的能力,进一步提高了应用的价值。传统的CNN模型只能对图像内容进行识别和分类,无法实现图像层面的生成与逻辑推理。而多模态模型由于采用自编码的训练模式,可以通过给定文字生成图片或根据图片生成描述。文本模态赋予了模型逻辑推理能力,与图像模态实现思维链的共振。
二、多模态模型技术综述
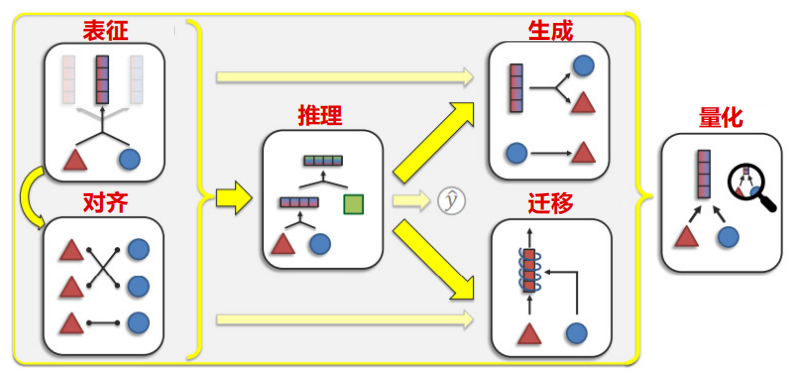
图像-语言多模态模型有六大任务:表征、对齐、推理、生成、迁移和量化。其中,对齐最为关键,也是当前多模态模型训练的主要难点。
表征研究如何表示和总结多模态数据,反映各模态元素之间的异质性和相互联系;对齐旨在识别所有元素之间的连接和交互;
推理从多模态证据中合成知识,通常涉及多个推理步骤;
生成涵盖学习生成过程,以生成反映跨模态交互的结构;
迁移旨在将具有高泛化性的模型通过调参适应各种垂直领域;
量化则通过研究模型的结构和工程化落地方式,更好地理解异质性、模态互联和多模态学习过程。
多模态模型的 6 大任务
1、表征:当前已有成熟方案
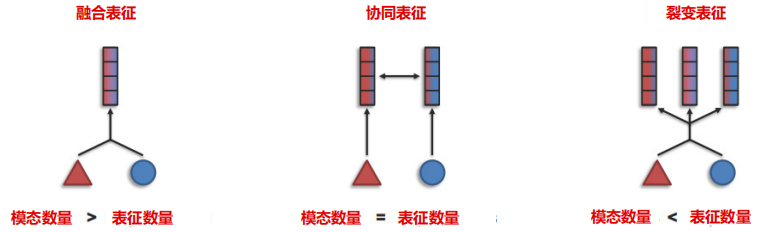
表征的主要目标是把不同类型的数据转化为模型能理解的形式。单模态的表征负责将信息表示为数值向量或更高级的特征向量,而多模态表征则是利用不同模态之间的互补性,去除冗余性,从而学习到更好的特征表示。目前,多模态模型的训练大多采用融合表征法,整合多个模态的信息,以寻找不同模态的互补性。此外,还有协同表征和裂变表征两种方法。协同表征将多模态中的每个模态映射到各自的表示空间,并保持映射后的向量之间具有相关性约束;裂变表征则创建一个新的不相交的表征集,输出集通常比输入集大,反映了同场景模态内部结构的知识,如数据聚类或因子分解。
多模态表征可以分为三种类型
目前文本表征和图像表征都有较为成熟的方案。文本表征的目的是将单词转化为向量 tokens,可以直接采用BERT等大语言模型成熟的方案。图像表征则生成图片候选区域并提取特征,将其转化为矩阵,可沿用机器视觉的CNN、Faster R-CNN等模型方案。
2、对齐:多模态技术的最大瓶颈
对齐是多模态模型训练最难且最重要的任务,对模型性能和颗粒度有直接决定作用。对齐的目的是识别多模态元素之间的跨模态连接和相互作用,例如将特定手势与口语或话语对齐。模态之间的对齐具有技术挑战性,因为不同模态之间可能存在长距离的依赖关系,涉及模糊的分割,并可能是一对一、多对多的关联性。经过对齐的模型图像的时间、空间逻辑更加细腻,不同模态的信息匹配度更高,信息损耗更小。
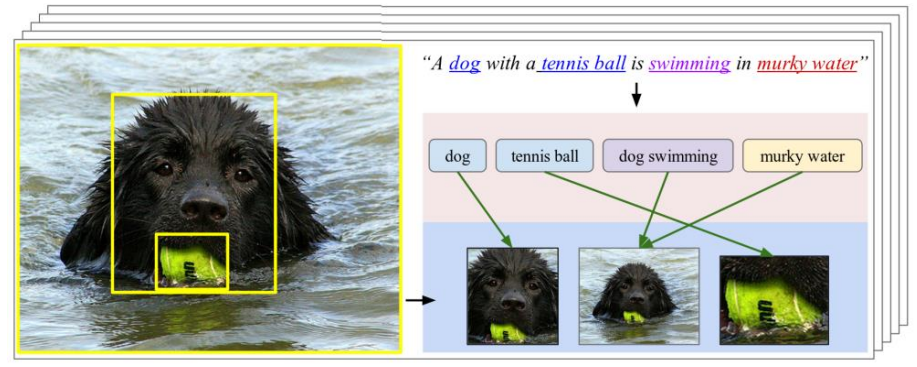
不同模态的对齐存在多对多的相互关系
数据对齐时会对文本和图像表征进行融合处理,根据词嵌入与信息融合方式的顺序不同,可分为双流(Cross-Stream)与单流(Single-Stream)。多模态大模型主要采用Encoder编码方式实现文本信息与图像信息的匹配融合。双流模型首先使用两个对立的单模态Encoder分别学习图像和句子表示的高级抽象,然后通过Cross Transformer实现不同模态信息的融合,典型模型有ViLBERT、Visual Parsing等。双流模型需要同时对两种模态进行Encoder编码,因此训练时算力消耗更大,但其优点在于模态之间的相关性更简洁明了,可解释性更具优势。
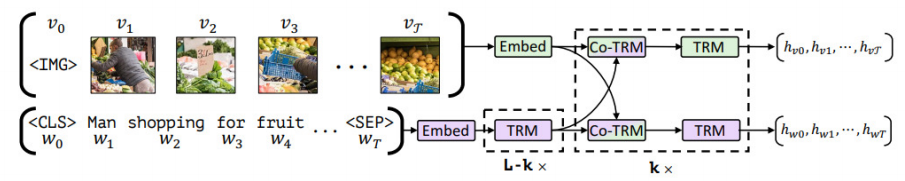
双流方案,以 ViLBERT 模型为例
单流模型假设图像和文本的底层语义简单明了,因此将图像区域特征和文本特征直接连接起来,将两种模态一起输入一个Encoder进行融合。采用单流形式的典型模型有VL-BERT、ViLT等。单流模型只需对混合的模态进行编码,因此算力需求更低。但信息传递和融合可能会受到限制,某些信息可能会丢失。此外,过早混合两种模态使得相关性和可解释性较差。
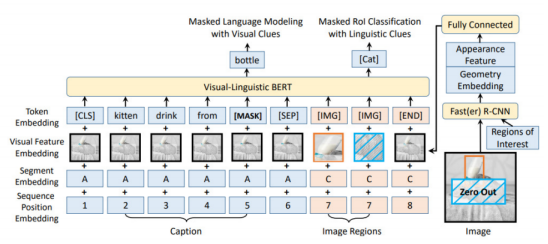
单流方案,以 VL-BERT 模型为例
3、推理与生成:沿用大语言模型方案
推理与生成是多模态模型结合知识并决策的过程。多模态中的视觉推理受到文本模态的影响,文本的时间序列为图像推理提供更强的逻辑性。随着训练的推进和参数量增长,多模态模型展现出思维链能力,将复杂任务分解为多个简单步骤。多模态模型的推理与生成算法搭建和大语言模型类似,可沿用其方案。模型推理与生成的速度主要由算力基础设施决定。
多模态模型生成任务包括总结、翻译和创建三个任务。总结是通过计算缩短一组数据以创建摘要,摘要包含原始内容中最重要或最相关的信息,信息规模下降。翻译涉及从一种模态到另一种模态的映射,信息规模保持不变。创建旨在从小的初始示例或潜在的条件变量中生成新的高维多模态数据,信息规模上升。
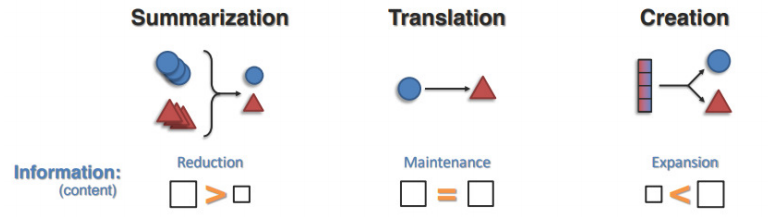
生成包含总结、翻译与创建三个任务
4、迁移:难度与下游应用场景关联度较大
多模态大模型的迁移是指将预训练好的多模态模型经过调参后,用于解决不同任务或领域的过程。经过预训练的大模型具备基本的多模态生成、图像理解与逻辑推理能力,但由于缺少行业数据的训练,在细分场景的适配性较低。经过调参的多模态大模型会增强图文检索、图像描述、视觉回答等功能,与医疗、教育、工业场景的匹配性更高。迁移任务的难度技术上不高,主要难点在于工程化调试,且难度与下游应用场景关联度较大。
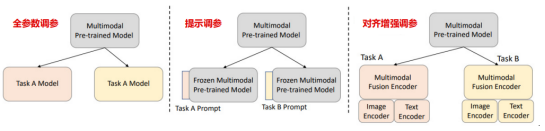
多模态模型调参的三种方法
多模态模型调参可分为三种类型:全参数调参、提示调参和对齐增强调参。全参数调参需要微调所有参数以适应下游任务;提示调参只需微调每个下游任务的少量参数;对齐增强调参在多模态预训练模型外添加了对齐感知图像Encoder和对齐感知文本Encoder,并一起训练所有参数以增强对齐。
5、量化:模型的迭代与改良
量化旨在通过深入研究多模态模型以提高实际应用中的鲁棒性、可解释性和可靠性。在量化过程中,开发者会总结模型构建经验,量化不同模态之间的关联交互方式,寻求更好的结合方法。因此,量化会引导开发者重新审视模型对齐与训练过程,不断迭代优化模型,寻找最佳通用性与场景专用性的平衡点。量化是一个长期且模糊的过程,没有标准答案,只能通过模型迭代尝试寻找更优解法。
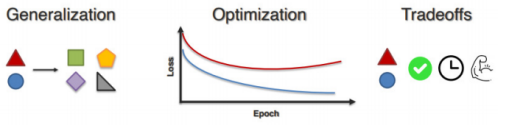
量化会协助模型迭代到通用性与场景专用型的平衡点
三、多模态模型的应用落地与产业趋势
1、产品陆续发布,应用落地加速
9月25日,OpenAI发布GPT-4多模态能力,包括图像理解能力,基于GPT-4 Vision模型,可以理解和解释图像内容,同时具备上下文回溯能力。GPT-4的多模态能力基于GPT-4V模型,经过2022年训练后,使用RLHF完成一系列微调,从有害信息、伦理问题、隐私问题、网络安全、防越狱能力五个角度完善模型,大幅度降低了模型安全风险。
在长期打磨后,OpenAI开放了GPT-4的多模态能力,意味着应用落地的门槛不是技术限制,而是在于模型打磨和场景挖掘。长期打磨的GPT-4多模态能力具备较高的鲁棒性,安全性已达到商用标准,产品成熟度较高。因此,可以推断GPT-4多模态模型的应用落地可能更加乐观。同时,9月21日OpenAI发布DALL-E3文生图模型,相比DALL-E2,DALL-E3理解图像细微差别和细节的能力大幅度提高,生成的图像包含更多细节,更符合prompt描述。DALLE-3深度整合ChatGPT模型,用户可以直接通过自然语言与DALL-E3交互。文生图应用门槛大幅度降低。
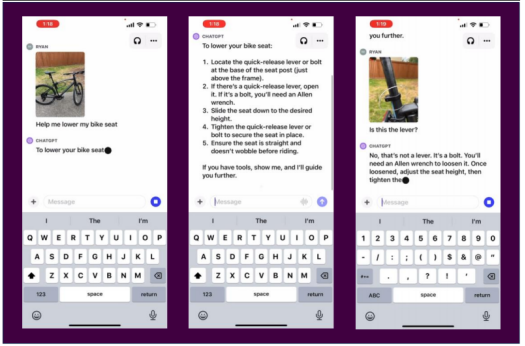
GPT-4 多模态模型有较强的逻辑思维能力
测评显示,DALL-E3模型在相同prompt输入下的性能已经达到Midjourney V5水平。DALL-E3已于10月首先向ChatGPT Plus和企业客户提供。

DALL-E2(左)与 DALL-E3(右)生成图像对比
DALL-E3 深度结合 ChatGPT,使用户可以直接以自然语言与模型交互,降低文生图应用的使用门槛。DALL-E3 具备上下文理解和记忆能力,可回溯上文信息,进一步简化交互流程。相比 Midjourney,DALL-E3 用户无需花费大量时间编写和优化 prompt,通过 ChatGPT 打磨好 prompt 后再输入应用即可。
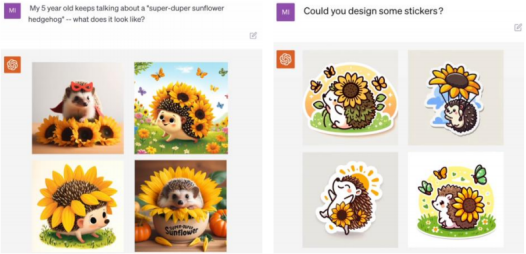
DALL-E3 整合 ChatGPT
2、场景匹配度提升,核心赛道有望快速渗透
大语言模型只能用于文本相关的场景,而多模态模型可以覆盖所有视觉场景,因此应用范围得到极大的提升。可以类比计算机发展早期从文本操作系统向图形操作系统的跃升,图像模态更贴近现实世界,信息密度更高,使用门槛更低,更适合人机交互。随着GPT-4多模态能力的开放,多模态模型的应用有望快速实现。这将带来新的技术发展和应用机会。
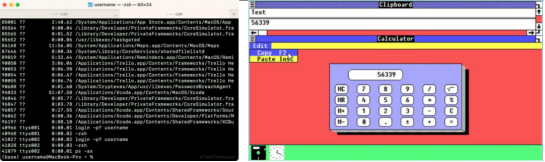
与文本操作系统(Terminal)相比,图形操作系统(Windows 1.0x)更符合人机交流习惯
多模态模型在提高场景匹配度方面具有显著优势。自2023年初以来,大模型应用在落地过程中取得广泛的关注,但其在渗透速度上的进展相对缓慢。核心原因在于大语言模型在场景匹配度方面存在不足,难以彻底改变特定细分领域的应用场景。相比之下,多模态模型能够显著提高应用的场景匹配度,实用性较高,预计将在医疗、教育、办公等场景中快速渗透。这种高实用性的特点可能催生大批爆款应用,建议密切关注核心场景中多模态应用的落地节奏。

GPT-4 Vision 在工业界的应用
多模态模型将引发新的算力竞赛。由于图像数据规模庞大,多模态模型对算力的需求更高。当前,算力仍是AI模型训练和推理的主要瓶颈。随着多模态模型的普及,AI公司将开启新一轮的算力竞赛。因此,建议关注英伟达、华为、蓝海大脑等算力产业链上的厂商。
此外,多模态大模型有望实现人形机器人的“端到端”方案。传统的机器人算法系统由感知、决策规划和控制三个模块组成,需要两个接口进行信息传递。而多模态模型将感知和决策合并为一个模块,只需一个接口,减少了信息传递的环节,提高系统的性能和鲁棒性。
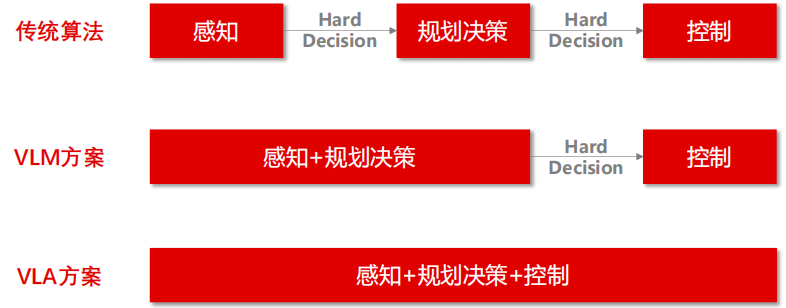
多模态模型将感知与决策模块合并
高频因子计算的GPU加速
近年来,AI技术显著提高因子挖掘和合成效率,但因子计算环节尚未充分受益于技术进步。传统因子计算通常使用CPU,但高频数据的普及,CPU性能面临限制。随着NVIDIA引领GPU软硬件生态日益成熟,使得高频因子计算的GPU加速成为可能。
RAPIDS是NVIDIA为数据科学与机器学习推出的GPU加速平台。以CUDA-X AI为基础,由一系列开源软件库和API组成,支持完全在GPU上执行从数据加载和预处理到机器学习、图形分析和可视化的端到端数据科学工作流程。据NVIDIA官网,RAPIDS能够将数据科学领域效率提升50倍。
在量化投资的因子计算场景下,RAPIDS使用CuPy、cuDF库替代NumPy、Pandas库,实现高频因子计算的GPU加速。在NVIDIA GeForce RTX 3090和Intel Core i9-10980XE测试环境下,使用CuPy和cuDF替换库函数的GPU提速效果约为6倍,如果同时将for循环替换为矩阵运算,最终提速超过100倍。
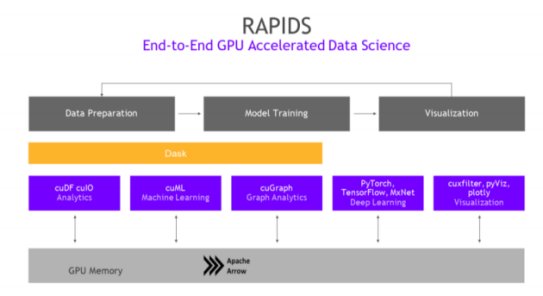
RAPIDS:数据科学的 GPU 加速
一、NVIDIA RAPIDS 实践
1、RAPIDS 安装
RAPIDS 官网提供详细的安装方法,可参考:https://docs.rapids.ai/install。在安装过程中可能会遇到一些问题,参考以下经验。
1)RAPIDS 安装
推荐操作系统Ubuntu 20.04 和 CentOS 7。如果使用的是 Windows 系统,需要通过 Windows 子系统 Linux 2(WSL2)来安装。具体的安装方法可以在微软官网找到:https://learn.microsoft.com/en-us/windows/wsl/install。
在安装 WSL 时,可能会遇到一些问题。需要注意的是:
- 推荐使用 Windows 11 系统
- 在任务管理器中确认 CPU 虚拟化已启用
- 在 Windows 功能中勾选“适用于 Linux 的 Windows 系统”和“虚拟机平台”
- 以管理员身份运行 Power Shell,执行 bcdedit /set hypervisorlaunchtype auto
- 设置网络和 Internet 属性中的 DNS 服务器分配为手动,并设置 IPv4 DNS 服务器为首选,DNS 设为 114.114.114.114,备用 DNS 设为 8.8.8.8。不执行此步骤可能会导致安装 WSL 时报错
- 以管理员身份运行 CMD,执行 wsl –update 来更新 WSL。不执行此步骤可能会导致启动 Ubuntu 时报错
- 继续执行 wsl --install -d Ubuntu 来安装 Ubuntu 子系统
- 启动“适用于 Linux 的 Window 子系统”(WSL),设置账户和密码,完成 WSL 安装
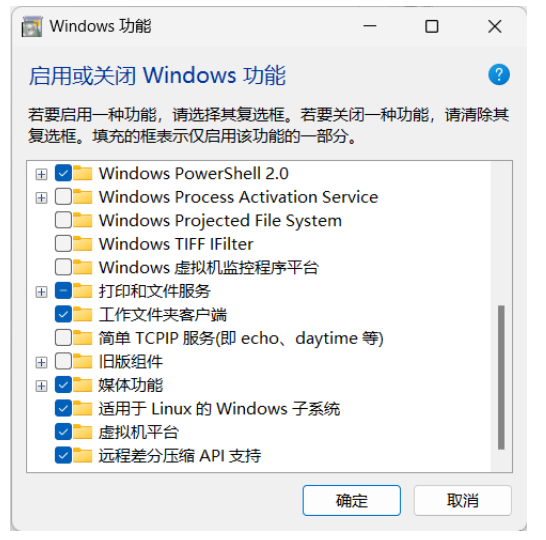
WSL 安装:启动或关闭 Windows 功能
2)WSL Conda 和 RAPIDS 安装
RAPIDS 官网提供在 WSL 中安装 Conda 和 RAPIDS 的方法,参考文档:https://docs.rapids.ai/install#wsl2。
以下是在 WSL 中安装 Conda 和 RAPIDS 的要点:
- 启动 WSL,登录 Ubuntu 系统
- 运行指令下载并安装 Miniconda:wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash Miniconda3-latest-Linux-x86_64.sh
- 运行 export PATH=/home/username/miniconda3/bin:$PATH,设置环境变量
- 在 RAPIDS 官网(https://docs.rapids.ai/install)选择需要安装的版本、方式、CUDA 版本、Python 版本、RAPIDS 库种类、附加扩展库,生成相应代码,在 WSL 中运行
以仅安装 cuDF 和 cuML 为例,运行代码 conda create --solver=libmamba -n rapids-23.08 -c rapidsai -c conda-forge -c nvidia cudf=23.08 cuml=23.08 python=3.10 cuda-version=11.2。该指令将自动创建名为 rapids-23.08 的 conda 环境。

RAPIDS 安装:选择版本
- 激活名为 rapids-23.08 的 Conda 环境
- 进入 Python 环境,运行以下代码以验证安装是否成功:import cudf print(cudf.Series([1, 2, 3]))
- Miniconda 环境仅提供了少数库,可以通过 Conda install 命令来安装 Pandas 等常用库
- 在代码中调用 Windows 系统文件时,请使用路径“/mnt/盘符/路径”,例如“/mnt/d/data”
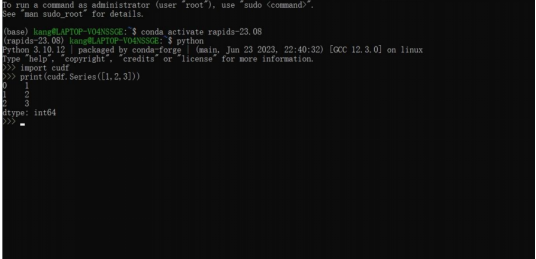
RAPIDS 安装:在 WSL 中运行
2、高频因子代码优化
测试环境:CPU - Intel Core i9-10980XE,GPU - NVIDIA GeForce RTX 3090。以2023年4月24日单日全A股分钟线数据为例,测试时间开销。在将CPU计算代码改造为GPU版本时,有两种优化方式:使用CuPy和cuDF替换NumPy和Pandas函数(针对全部50个因子);使用矩阵运算替换for循环(针对50个因子中的22个因子)。
结果表明:
- 单独使用第一种优化方式反而增加时间开销
- 同时使用两种优化方式,时间开销总体缩短约117倍,其中第一种优化方式贡献约18.4倍,第二种优化方式贡献约6.4倍
- GPU性能表现主要取决于数据量,单次运算涉及的数据量越大,GPU加速效果越显著。如果数据量过小,反而不如CPU计算效率
1)简单替换库函数
RAPIDS的CuPy和cuDF与原始CPU代码的NumPy和Pandas具有相似的接口,因此可以通过简单地替换库名称来简化工作量。以计算下行收益率方差return_downward_var的代码为例,只需将numpy.var替换为cupy.var即可。cuDF的具体指令集可参考官方文档:https://docs.rapids.ai/api/cudf/stable/

计算下行收益率方差 return_downward_var 代码:for 循环+CPU
实证发现,CPU版代码的单日高频因子计算时间开销为12.34秒,但简单替换为GPU版代码后,时间开销反而超过100秒。问题在于,代码在因子计算中大量使用for循环,而RAPIDS的接口只实现接口内部的并行计算,并未对for循环进行优化。此外,由于数据需要在CPU和GPU之间进行拷贝传递,这也带来额外耗时。GPU更适合进行批量运算,如果只是简单替换库函数,而for循环逐轮调用GPU处理小数据量,反而会拖累性能。因此,在进行GPU加速时,需要考虑代码的整体结构和优化方法。
2)矩阵运算代替 for 循环,同时替换库函数
下面将重新调整for循环的逻辑,将其改为矩阵运算,并使用CuPy接口进行批量处理。以下是一个计算下行收益率方差return_downward_var的代码示例。

计算下行收益率方差 return_downward_var 代码:矩阵运算+CPU
- 对于50个替换库函数的因子,GPU相比CPU总时间开销从0.91秒缩短至0.16秒,性能提升约5.9倍
- 对于22个使用矩阵运算代替for循环的因子,CPU总时间开销从12.34秒缩短至0.67秒,性能提升约18倍。GPU相比CPU总时间开销从0.67秒缩短至0.11秒,性能提升约6.4倍。两项改进总时间开销从12.34秒缩短至0.11秒,性能提升约117倍
总的来说,使用GPU(NVIDIA 3090)相比使用CPU(Intel i9-10980XE)计算因子带来的性能提升在5.9~6.4倍之间。这个约6倍的加速效果并不是上限,实际加速效果受到显卡性能和数据量等多种因素的影响。根据NVIDIA官网的数据,RAPIDS的提速可达50倍。(https://www.nvidia.cn/deep-learning-ai/software/rapids/)
同时观察到一些没有GPU加速效果的因子,例如return_intraday、return_improved、return_last_30min等,这些因子仅使用日内两个时间点的数据,因此数据量过少。另外,对于intraday_maxdrawdown这个因子,CuPy尚未实现numpy.minimum.accumulate接口,导致调用GPU反而耗时增加。

因子计算环节 CPU、GPU 性能对比(汇总)
除了因子计算,还使用cudf库替换pandas库,对数据读取和预处理环节进行优化。然而,测试发现数据读取和预处理部分性能不佳的主要原因是数据量不足。单日分钟K线数据的维度约为5000×242×11(全A股分钟字段)。尝试构建虚拟数据集,发现当数据量扩大4倍后,GPU性能超过CPU。此外,发现cudf库仅有数据导出环节的to_csv函数性能更优(约5倍加速)。

数据读取、预处理及导出环节 CPU、GPU 性能对比
芯片禁令升级后
我们该何去何从?
前几天,美国正式发布“新规”,全面收紧尖端AI芯片对华出口,禁令将在30天内生效。
一、新一轮禁令有哪些新变化?
只要满足以下任一条件,GPU芯片就会受到出口限制:总算力低于300 TFLOPS,或每平方毫米的算力低于370 GFLOPS。此次新规的主要变化在于降低门槛,并取消“带宽参数”,转而采用“性能密度”作为衡量标准。此举旨在堵住一个漏洞,即通过Chiplet技术将多个小芯片组装成一个大芯片。
根据这一新规,英伟达的A100、A800、H100、H800、L40和L40S等产品将无法向中国出售。甚至定位于发烧级游戏显卡的RTX 4090也需要报批,因为在老美的逻辑中,RTX 4090也可以用于AI训练,尽管其优势并不在此。
二、当前AI大模型一般用什么卡在训练?
自年初以来,业界各家都在积极开发自家的大模型,这些模型通常都以GPT-4模型为标杆,GPT-4的参数量高达1.76万亿,已经达到现有算力的极限。实际上,OpenAI需要使用约2.5万个A100 GPU训练GPT-4,耗时约100天。而对于下一代大模型GPT-5,根据马斯克的说法,可能需要3-5万块H100 GPU进行训练,但具体的训练时间并未提及。

目前,国内第一批大模型厂商主要使用英伟达芯片,今年的主力芯片预计仍是A100、A800。而H800近期才逐渐在国内交付。英伟达构建完备的CUDA生态,使得用户在更换生态时面临较高的学习成本、试错成本和调试成本。一位客户表示:“如果不是情非得已,绝大部分用户不敢贸然更换生态,因为那意味着学习、试错和调试成本都会增加。”这表明,采用国产GPU可能会导致用户在某些方面落后于同行,尽管金钱成本可能不是主要考虑因素,但速度和效率却是关键。
根据华为公布的数据,昇腾910B基本上可以与英伟达的A800相媲美。然而,由于高端显存方面的不足,其实际性能可能会打些折扣,约为A800的90%。如果采用大型服务集群,折扣可能会更大。当然,真正的难点并不在于技术参数,而在于应用生态和AI模型底层算法的差距。CUDA的优势恰恰在于此,这也是最难以突破的地方。
三、面对新一轮禁令,该何去何从?
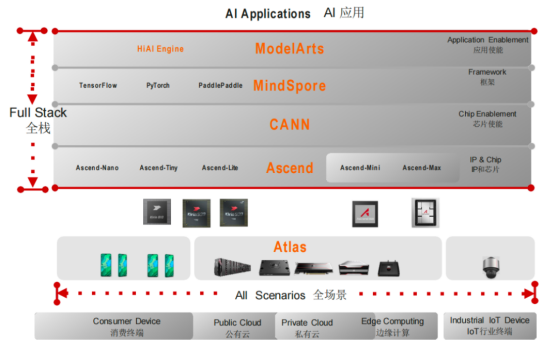
关于CUDA生态的解决方案,可以从鸿蒙操作系统得到启示。虽然鸿蒙生态短期内还无法与iOS和安卓系统抗衡,但其中包含兼容Google生态的代码,使得能够兼容基于安卓开发的APP。这是短期内的解决方案,但长远来看,建立自己的软件生态是摆脱制约的关键。至于何时能够实现这一“脱钩”,华为官方表示,下一个鸿蒙版本可能会是一个转折点。
在GPU领域,也可以采取类似的策略。首先,可以为国产GPU增加一个虚拟化层,实现与基于CUDA开发的应用软件的兼容。这可以作为过渡期的解决方案。然而,长远来看,国产GPU必须构建自己的软件生态。例如,华为的CANN被视为对标CUDA的解决方案,兼容PyTorch、TensorFlow等主流AI框架。最近有消息称,华为成为了PyTorch基金会的最高级别会员,这是中国首个加入该基金会的会员,也是全球第10个。这意味着CANN将能够跟上PyTorch的发展。
在大模型时代,头部客户的需求逐渐收敛,使用的算子库也相应减少。据报道,目前主流AI框架的兼容性已经超过50%。同时,华为也在推广自己的AI框架MindSpore(昇思),据称在国内已经与百度的PaddlePaddle(飞桨)并列第三,市场份额达到11%。一些基于华为原生态体系孵化的大模型已经在使用“昇腾GPU+CANN+MindSpore”整套国产体系,例如“讯飞星火认知”、盘古NLP、鹏城盘古、盘古CV等。而通过“昇腾GPU+CANN”适配的大模型则更多,包括GPT、ChatGLM、LLaMA、BLOOM等主流基础大模型。
蓝海大脑大模型训练平台
蓝海大脑大模型训练平台提供强大的算力支持,包括基于开放加速模组高速互联的AI加速器。配置高速内存且支持全互联拓扑,满足大模型训练中张量并行的通信需求。支持高性能I/O扩展,同时可以扩展至万卡AI集群,满足大模型流水线和数据并行的通信需求。强大的液冷系统热插拔及智能电源管理技术,当BMC收到PSU故障或错误警告(如断电、电涌,过热),自动强制系统的CPU进入ULFM(超低频模式,以实现最低功耗)。致力于通过“低碳节能”为客户提供环保绿色的高性能计算解决方案。主要应用于深度学习、学术教育、生物医药、地球勘探、气象海洋、超算中心、AI及大数据等领域。
在最底层,构建基于英伟达GPU的全场景AI基础设施方案,适用于“端、边、云”等各种应用环境。帮助开发者更快速、更高效地构建和部署AI应用。


一、为什么需要大模型?
1、模型效果更优
大模型在各场景上的效果均优于普通模型。
2、创造能力更强
大模型能够进行内容生成(AIGC),助力内容规模化生产。
3、灵活定制场景
通过举例子的方式,定制大模型海量的应用场景。
4、标注数据更少
通过学习少量行业数据,大模型就能够应对特定业务场景的需求。
二、平台特点
1、异构计算资源调度
一种基于通用服务器和专用硬件的综合解决方案,用于调度和管理多种异构计算资源,包括CPU、GPU等。通过强大的虚拟化管理功能,能够轻松部署底层计算资源,并高效运行各种模型。同时充分发挥不同异构资源的硬件加速能力,以加快模型的运行速度和生成速度。
2、稳定可靠的数据存储
支持多存储类型协议,包括块、文件和对象存储服务。将存储资源池化实现模型和生成数据的自由流通,提高数据的利用率。同时采用多副本、多级故障域和故障自恢复等数据保护机制,确保模型和数据的安全稳定运行。
3、高性能分布式网络
提供算力资源的网络和存储,并通过分布式网络机制进行转发,透传物理网络性能,显著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用严格的权限管理机制,确保模型仓库的安全性。在数据存储方面,提供私有化部署和数据磁盘加密等措施,保证数据的安全可控性。同时,在模型分发和运行过程中,提供全面的账号认证和日志审计功能,全方位保障模型和数据的安全性。
三、常用配置
1、CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC™ 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC™ 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、GPU:
NVIDIA L40S GPU 48GB
NVIDIA NVLink-A100-SXM640GB
NVIDIA HGX A800 80GB
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW×8
 0.0000
0.0000
 1
1
 0
0

 关注作者
关注作者
 收藏
收藏

评论(0)
 发表评论
发表评论
暂无数据







推荐帖子
ly168168
2025-09-02
0条评论

天下无欺诈
2025-08-06
0条评论
小小杰杰
2025-04-28
0条评论