编者按:9月11日—9月12日,由经管之家(原人大经济论坛)主办的“2015中国数据分析师行业峰会(CDA•Summit)”在北京举行。本文是英特尔中国研究院院长兼首席工程师吴甘沙在峰会上的演讲全文,吴甘沙演讲的主题是“大数据分析师的卓越之道”。他讲道,基础设施已经改朝换代了,我们分析师也应该与时俱进,体现在三个:一个使思维方式要改变,我们技术要提升,第三,我们分析的能力要丰富起来。以下为吴甘沙演讲全文:

亲爱的各位同仁,各位同学,早上好。大家可能还有些纳闷,本来是吴恩达老师讲人工智能,怎么换吴甘沙讲。几个月前我刚刚跟吴老师在硅谷聊了一两个小时,早知道今天这样我多向他请教一下人工智能,现在还是讲一下我擅长的大数据。讲到大数据,就要问数据分析师应该做什么?所以我今天的标题是大数据分析师的卓越之道。这里不一定讲的对,讲的对的我也不一定懂,所以请大家以批评式的方式去理解。
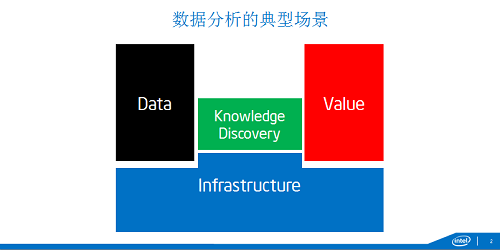
这是一个典型的数据分析的场景,下面是基础设施,数据采集、存储到处理,左边是数据处理,右边价值输出。连接数据和价值之间的就是这知识发现,用专业词汇讲,知识就是模型,知识发现就是建模和学习的过程。问题来了,进入到大数据的时代,这有什么变化呢?首先对数据变的非常大,大家就开始说了,数据是新的原材料,是资产,是石油,是货币,所以大家的希望值也非常高,这个价值也希望抬的非常高。但是一旦大数据洪流过来,我们原有基础设施都被冲的七零八落。所以过去十几年事实上业界都在做大数据基础设施,我怎么做大规模水平扩展,数据密集了怎么提高分布式操作性能,怎么把磁盘山村化,我们就有闪存内存化,我们最近从密集型又到计算密集型。所有这些都是基础设施。
现在大家想基础设施升级了,我只是知识发现的过程是不是能自然升级?我跟大家说天下没有免费的午餐。所以我想今天的主题是基础设施已经改朝换代了,我们分析师也应该与时俱进,体现在三个:一个使思维方式要改变,我们技术要提升,第三,我们分析的能力要丰富起来。
首先,说一下思维方式。说改变思维方式最重要的就是改变世界观,这个就是牛顿机械论世界。我们曾经听说过一个叫拉夫拉丝恶魔的说法。也就是说,我如果在这个时刻与宇宙当中所有的原子的状态都是可确定的话,就可以推知过去任何一个时刻和未来任何一个时刻,这就是牛顿的机械论。所谓爱因斯坦发展了这个物理学,但是还是确定论,决定论,上帝不掷色子。但是今天的世界事实上是什么样的?我们这个是说牛顿世界观,就是确定论。事实上今天是不确定的,基于概率的世界观。大家都看过所谓的(薛定论)的猫的思维的实验。这个猫在盒子里到底是死还是活的,其实它可能同时是死的,也同时是活的。但是一旦打开这个盒子,它就变成确定了,它要么就是真的变成死的,要么就是真的变成活的。也就是由我们现在所谓的好奇心害死猫,就是你打开盒子有一半的概率把这个猫杀死。
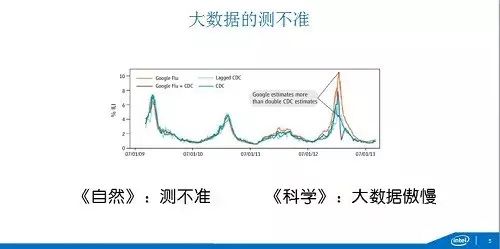
这个理念事实上反映的就是海森堡的不确定主义,就是你的行为会改变被观测的现象,在大数据事实上也有测不准的,像Google流感的预测,这是大家经常作为数据分析的经典案例,具体细节不跟大家讲了,大家可以看在2013年1月份的阶段,橙色的线,Google预计高于疾控中心它实际测到的流感的概率。所以科学和自然就发话了,自然是科学测不准,科学说这是大数据的傲慢。在这个案例来,即使Google也拿不到全量的数据,你虽然有疾控中心的数据和当中调整模型等等的,但是还是不精确,你以为这种相关性就能解决问题,但是健康的问题就是要究其原因,要有因果性。大家看这个预测的过量就导致了预感疫苗准备的过量。

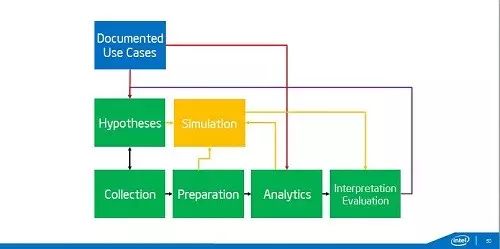
所以我们看数据的方法论我们需要升级。这是一个典型的数据分析的流程,可以先由假设采集数据,也可以先采集了数据,然后从中发现假设。有了数据以后下一步就要做数据的准备,数据准备往往是最花时间的。然后分析,分析完了要考虑怎么解释这个结果,大家知道做机器学习有两种:一种是给机器看的,比如说我精准营销;还有一种机器学习是给人看的,是要有可解释性。有时候为了可解释性甚至愿意牺牲精确性。大家知道Ficle,它就是理论参数,非常简单,可解释性非常强。另外一个就是要验证,从我们传统说的随机对照实验到现在AB测试,我们要去验证。但是到了大数据时代这个方法论要怎么改变呢,首先我们说测不准,还有不要相信看到的任何事,所以需要加一个反馈循环,我们不停的反复做这个。这里虽然有很多噪声,但是这个是可以处理的,还有一些是系统噪声,可能因为污染的数据源,这个就要特别处理。我们要数据分析需要实时、交互、要快,这样才能赶得及世界的变化,所以这里需要很多很多的东西。
我现在一个一个跟大家分析一下。首先看假设。我们现在说大数据思维是说我们先有很多数据,然后通过机械的方法发现其中的相关性,之后再找到假设。有时候相关性确实太多了,弱水三千只取一瓢饮,这里面就需要我们的直觉。所谓的直觉就是不直觉,但是在潜意识里在发生推理。所以我一直强调要怎么训练直觉?就是读,像悬疑小说,你经历这么一个推理的过程。如果说这样的推理过程只是模型,也还需要数据,需要很多先验的知识。这个知识怎么来呢?就是广泛的阅读。第二个,跨界思想的碰撞,跟很多人聊。这两个是背景知识,还有一个前景知识,就是在这么上下游里融入到业务部门。现在我们企业的数据分析的组织,我们希望把数据分析师放到业务部门,和它们融入到一起,这才能防止数据和分析脱钩,这样才能防止数据分析和业务应用的脱节。
第二个,数据采集,这里我非常夸张的是数据!数据!数据!为什么?因为大数据碰到的第一个问题就是数据饥渴症。我们有一次跟阿里聊,它们说也缺数据,因为它们只有网上的销售记录,而缺乏无线的数据。所以我们强调全量数据,我们尽量不采样。
同时现在我们企业已经从小数据到大数据,有人说数据改变太困难了,太贵了。其实它强调的是问题还没存在的时候,你一开始就把数据定了。传统的数据仓库是,我先有一个问题,然后你这个数据根据这个问题做好组织,然后进来。从现在的大数据来说,你先把数据送进来,然后再不断的提问题,这就是一种新的思维。我们需要大量外部的数据源来查,你要买数据拿来用。而且你要从传统的结构化数据到半结构化、非结构化数据。传统结构化数据是什么,交易数据。但是现在我们企业里面马上就有两个非结构化数据出现。
说完感叹号,我开始要说问号。是不是前面说的这些都是合理的?比如说英特尔事实上是不可能采集到数据,而有时候你采集不到全体数据,你也不需要。
比如说我给大家举个例子,是不是数据更多就越好呢?未必。我们拿英特尔作为一个例子,青海、西藏、内蒙古占的面积是我们国土面积的一半,我们采集这四个省的面积,是不是都代表中国呢?未必,所以采集更多的数据有时候更重要。第二个是“原始数据”是不是一个矛盾的概念,因为原始数据可能并不原始,它受采集人的影响。所以原始数据也未必是原始的,数据里面当然有很多的信号。但是大数据里面的噪声很多,但是有时候在数据里面信号就是以噪声的方式变成的。比如说现在我们这个世界要倾听每一个个体的声音,有一些个体的声音是非常少的,在数据里面非常少,但是你不能忽略它。采样本身是有偏差的,有一个经典的故事,二战的时候他们分析,飞回来的时候有很多弹孔,到底是加固哪个地方好呢?很多人说是机翼,很多人没有想到你要加固座舱,因为采样是有偏差的。尤其是大数据,有一些子数据集,每一个数据是按照不同的抽样规范来获得的,这样就有采样偏差。
这里面是不是可以做,你还要考虑数据权利的问题,这些数据是属于谁的?有没有隐私问题?许可是不是有范围?我是不是按照许可的范围做了?我能不能审计?这些都是数据的权利。未来数据交易的话还要解决数据的定价问题,这是非常困难的。
当我有了数据以后,需要生命周期的管理,大数据生命周期管理非常重要。一是出处或者是来源,即是大数据的家族谱系,它最早是哪里来的,它又移动到什么地方,经过什么样的处理,又产生了什么样新的子后代。现在我们强调数据采集,是不是有这个必要?我们发现其实很多数据没用以后,你就应该删除。
有一个案例,互联网公司采集了很多鼠标移动的数据。大家知道用Cookies来采集鼠标在什么地方,可以了解用户的浏览行为。但是过一段时间网页都变化了,这些数据还有什么用呢?所以就删除掉。并不是说数据越多越好,并不是说数据永远都要保存,这是数据的采集。
下面讲数据的准备,刚才说大数据有很多噪声,大数据的质量非常重要。刚才我们说的它的混杂性,它的精确性有问题。一个非常著名的研究机构做了统计,说你们这些大数据分析师,一方面数据大,是不是你的问题,另外一方面数据质量是不是你的问题,选择后者是前者的两倍。大数据本身它就是一个有噪声的,有偏差的,也是有污染的数据源。你的目标定在建立一个模型,要对噪声建模,同时还要是信号不能太复杂,模型不能太复杂的。
一般处理的是数据清洗和数据验证,还有一种说法是有,前者关注数据是错的,数据有些是丢失的或者有些数据是相互矛盾的。我通过清洗、验证的方式把它做出来。大数据非常大怎么办,有没有从一小部分数据开始做清洗,有没有可能把整个过程自动化,这是研究的前沿。另外一个前沿就是数据的清洗能不能跟可视化结合起来,通过可视化一下子发现了这些不正常的地方。通过机器学习的方式来推理这些不正常的地方是因为什么地方。
我觉得现在最热的研究课题是,你怎么能够通过学习的方式来发现非结构化数据当中的结构。你怎么能够把哪些看似不同的数据挑出来,比如说有些地方叫国际商业机器公司,有些地方叫蓝色巨人,你最终能够把这些数据的表示使得它马上就可以分析。我首先考虑怎么能够降低计算通讯的代价。
大家看我们大数据经常是稀疏的,大数据太大了我们有没有可能压缩。大家知道我们原来的数据仓库,最大的问题,最麻烦的问题就是我要给这个表增加列,增加列特别痛苦。现在我发现通过增加列的方式变得非常简单,我通过数据压缩树立的话更有局部性。
另外就是近似的数据,它就是一种通过降低它的时空复杂性,使得它误差稍微增加几个百分点,但是它的计算量下降几个数量级。大家也应该听说过很多方式都是做这个的。
怎么能够降低统计的复杂性,其实大家知道大数据就是高纬,怎么办?降下来,我通过降纬的方式能够降低它的复杂性。我们还是需要采样的,大家知道要么是随机性采样,并不代表用一个均衡的概率采样,我用不同的组采样。比如说有些人你不知道他属于哪个组,比如说他是吸毒的,他不会说或者说他有特殊的技能,他也没有类似的标签,你可能需要一种新的采样的方式,比如说雪球采样,你先找一个种子然后再慢慢的扩大。即使你压缩了很多,但是你还是可以恢复原始数据的。
我想请大家注意,数据分析师并不是考虑数据表象的问题,并不是考虑数据模型的问题。最终还是要考虑计算是怎么做的,所以我们要选择最好的表示。比如说数据并行的计算就用表或者是矩阵,如果是图并行,我就要选择网络的格式。
最后,我想请大家注意UIMN,这个能够帮助你来保存各种各样数据表示,以及跟数据分析落对接。这个东西大家没听说过的话,大家一定听过Worse在人机竞赛中的电脑,它就是用这个表示的。
最后,查询。很早数据就是查询,慢慢说要统计学,慢慢又要机器学习了,所以我们说数据挖掘是对三个学科的交叉,而这些学习又是从人工智能脱胎出来。慢慢的从这儿又包了一层ABB,现在又有最新的内脑计算,分布学习。所有这些大家不能忘记,这些工具都要跟相关的计算的模型给对接起来。所以这是非常困难的东西。
我们数据分析师还是有些装备的,这个是现在最流行的四种分析的语言,Saas,R,SQL,还有python。有人说我不是这里的,那可能还需要学习JAVA这样的语言。这个可能还不够,还需要JAVASrcit,所以需要来更新我们的装备。但是有人说了这些装备都是为传统的数据分析师准备的,大家不要担心,因为在这些语言下面都已经有了大数据的基础设施,比如SQL,可以使你以前的语言平滑的迁移到大数据基础上。这些解决了大问题,因为原来的程序,数据量大一些就可以放在这个大数据的基础设施上。更方便的是现在所有做基础设施的人都在考虑一个词,ML Pipeliine,而且现在更多的东西都可以放到云里做了。大家看到现在所有这些大数据的基础设施我们都叫做动物园了,因为很多都是以动物的图标来展示的,现在都可以放到云里去,所以这给我们带来了很多方便。
这里要强调的是,这是一个统计学的大师说的,就是所有模型都是错的,但是有些是有用的,关键是选择什么样的模型。有一种人是一招鲜吃遍天,还有一种是一把钥匙开一把锁,我是开放的,我根据我的问题来进行选择。模型的复杂度必须与问题匹配的。这里就是有各种各样模型都能解决的时候,就选择最简单的一个。
我们现在做数据分析碰到两个问题:一个是过载,还有一个是数据量大了以后,模型没办法提升。这里就有一个很著名的人,叫彼特,他是写《人工智能现代方法》的作者,他说,简单模型加上大数据,比复杂模型加小数据更好,这个对不对,这个在很多情况下是对的,但是并不完全对。而且有时候模型简单参数很多,场景不同参数不同,假设场景是文本处理,可能每个单词就是一个特征,这个模型就会非常复杂,所以大数据是有用的。还有一种解决数据过多的方式,就是通过另外一种方式。现在线性模型针对小数据,我现在代参模型针对小数据,我甚至可以混合起来用,这样又能够提升分析的效率,又能够解决数据的计算量的问题。
我刚才讲到长尾信号非常非常重要,我们现在不能忽略长尾信号,那怎么办?我们传统的分析很多都是基于指数的假设,这个就是割尾巴,到后面就是没尾巴,这样就把长尾信号都过滤掉了,我可能是需要一些基于神经网络的方式。分析要快,第一,我们一直强调传统的是送进去的,我60秒完成跟6分钟完成是不是一样的呢?或者说它们的效率差一点点或者差几倍?未必,等待时间拉长,分析师的耐心会降低。像针对时空的数据,现在机器学习强调的在线学习、增量的学习、流逝的学习,一边进来一边学习、一边更改模型,这个就很重要。最后当你的数据又大,又需要快的时候,你不懂系统是不行的,你必须懂系统,你必须懂数据并行,任务并行,必须做系统调优的东西。
我前两天跟一个朋友聊,他说现在要做到所有分析数据的调优做到随机的访问都在CPU缓存里,到磁盘上的访问都是串行的访问,这样才能做到系统调优做到最佳。从语音识别,到图像理解,到自然语言理解。上面都是人们做的认知任务,深度学习下一步会进入非认知任务,像百度用来做搜索广告,包括做要务的发现,我现在也在做机器人,机器人很多需要深度学习,我们现在把深度学习放进去也非常好。大家的福音就在于现在深度学习很多的代码都是开源的,去年花了很多力气去做各种各样的模型,现在所有模型全部都开源,所以下一步大家注意,我们的科学是开放的。你有大量的开源的软件,而且现在不但你论文放在ICup上,你的数据代码可能放在Dcup上,所有都是开放的。

大家还没有学Sparse coding的话大家可以看一下,还有在标注下的学习,这张PPT是吴恩达的,大家看,橙色的都是标注数据,你要有大象和犀牛的数据,就是左面的是标出的,我可以结合一些非标注的东西学习,然后可以引入其他的标注数据,像羚羊的数据也可以帮助我们学习,最后到拿一些完全不相关的数据跟它们进行学习。
人类角色在变化,前一段时间有人提出来,人的角色,因为数据分析师要懂机器,懂工具,我们要跟工具更好的配合,因为我们的角色一直在跟机器替代它们。机器学习最重要的就是特征学习,现在无监督的,它可以帮助你学习特征,而且很多工具开始自动化了,那么你怎么跟它工作搭配,能够获得最好呢,就是你一边在利用工具获得一些数据,然后提出问题是一个循环的过程。现在就是大规模的人跟人,人跟机器协同配合,因为很多机器可以外包,你可以众包,你大量数据通过众标方式进行标注。包括协作,现在开放数据,光开放还不行,还要在这个数据上进行多人协作分析,你要对数据进行版本的管理,还有现在所谓的人类计算,像大家都在上面学习英语,在学习英语的过程是对互联网进行翻译的过程。
最后,就是解释和验证。今天的大会标题是要懂技术,懂艺术。这里一个很重要的就是讲故事,你有了分析之后怎么讲出来。比如说啤酒加尿布,它就符合了讲故事的3D:戏剧性、细节、参与这个对话的过程。啤酒加尿布,这个案例我给大家说这是编出来的,但是它符合了这个过程,所以它就马上传播出去了,变成大家都愿意去支持数据分析的这么一个案例。包括魔球(电影Money ball)也是这样,非常强调数据分析怎么来改变棒球运动的,但是事实上它也没有说出来的是,这里很多工作是通过裁判去做的,有些人非客观的因素,像意志力,像抗压力。还有像Facebook做控制情绪的实验,还有Uber分析一夜情。我还是想强调好的讲故事能够使分析事半功倍。

我们希望现在能够把大量的运力能document,这样可以进行学习,还有就是通过模拟预测未来。所以这就是最后的总结,现在我们的大数据的基础设施已经改朝换代了,我们的数据分析师,我们怎么来改变我们的思维方式,怎么来提高我们的技术,怎么来丰富我们的分析能力?谢谢大家。
主持人:谢谢吴院长。我们说了这么多专业的东西,其实我想跟院长聊聊其他的,我记得院长是一个非常平易近人,和蔼的人,包括他在之前回答记者的问题的时候,调侃说自己是跑龙套的。所以我今天听院长演讲也是非常的激动,为什么院长当时会这么说呢?
吴甘沙:我想每个人都是从跑龙套开始的。但是我想还是学习能力,你有学习能力的话很快就会蜕变。
主持人:这个转变也是意料之中的,因为吴院长一直这么努力。
吴甘沙:这块不是不确定,这块是确定的。
主持人:好,掌声再次送给吴院长。
PPT下载链接:http://bbs.pinggu.org/a-1874950.html
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330