主成分分析与因子分析及SPSS实现
一、主成分分析
(1)问题提出
在问题研究中,为了不遗漏和准确起见,往往会面面俱到,取得大量的指标来进行分析。比如为了研究某种疾病的影响因素,我们可能会收集患者的人口学资料、病史、体征、化验检查等等数十项指标。如果将这些指标直接纳入多元
统计分析,不仅会使模型变得复杂不稳定,而且还有可能因为变量之间的多重共线性引起较大的误差。有没有一种办法能对信息进行浓缩,减少变量的个数,同时消除多重共线性?
这时,主成分分析隆重登场。
(2)主成分分析的原理
主成分分析的本质是坐标的旋转变换,将原始的n个变量进行重新的线性组合,生成n个新的变量,他们之间互不相关,称为n个“成分”。同时按照
方差最大化的原则,保证第一个成分的
方差最大,然后依次递减。这n个成分是按照
方差从大到小排列的,其中前m个成分可能就包含了原始变量的大部分
方差(及变异信息)。那么这m个成分就成为原始变量的“主成分”,他们包含了原始变量的大部分信息。
注意得到的主成分不是原始变量筛选后的剩余变量,而是原始变量经过重新组合后的“综合变量”。
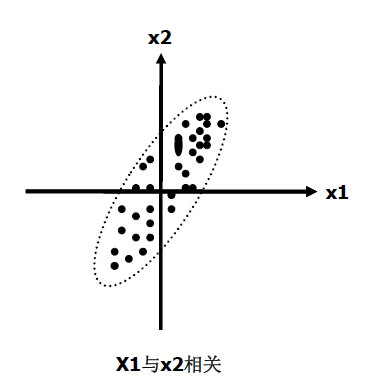
我们以最简单的二维数据来直观的解释主成分分析的原理。假设现在有两个变量X1、X2,在坐标上画出
散点图如下:
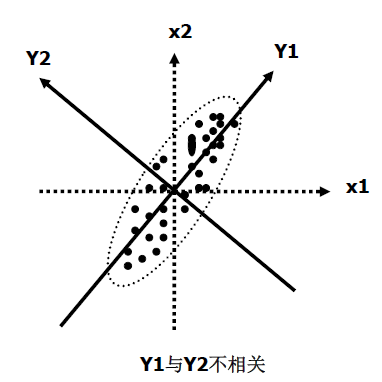
可见,他们之间存在相关关系,如果我们将坐标轴整体逆时针旋转45°,变成新的坐标系Y1、Y2,如下图:
根据坐标变化的原理,我们可以算出:
Y1 = sqrt(2)/2 * X1 + sqrt(2)/2 * X2
Y2 = sqrt(2)/2 * X1 – sqrt(2)/2 * X2
其中sqrt(x)为x的平方根。
通过对X1、X2的重新进行线性组合,得到了两个新的变量Y1、Y2。
此时,Y1、Y2变得不再相关,而且Y1方向变异(
方差)较大,Y2方向的变异(
方差)较小,这时我们可以提取Y1作为X1、X2的主成分,参与后续的
统计分析,因为它携带了原始变量的大部分信息。
对于二维以上的数据,就不能用上面的几何图形直观的表示了,只能通过矩阵变换求解,但是本质思想是一样的。
(一)原理和方法:
在主成分分析过程中,新变量是原始变量的线性组合,即将多个原始变量经过线性(坐标)变换得到新的变量。
因子分析中,是对原始变量间的内在相关结构进行分组,相关性强的分在一组,组间相关性较弱,这样各组变量代表一个基本要素(公共因子)。通过原始变量之间的复杂关系对原始变量进行分解,得到公共因子和特殊因子。将原始变量表示成公共因子的线性组合。其中公共因子是所有原始变量中所共同具有的
特征,而特殊因子则是原始变量所特有的部分。
因子分析强调对新变量(因子)的实际意义的解释。
举个例子:
比如在
市场调查中我们收集了食品的五项指标(x1-x5):味道、价格、风味、是否快餐、能量,经过
因子分析,我们发现了:
x1 = 0.02 * z1 + 0.99 * z2 + e1
x2 = 0.94 * z1 – 0.01 * z2 + e2
x3 = 0.13* z1 + 0.98 * z2 + e3
x4 = 0.84 * z1 + 0.42 * z2 + e4
x5 = 0.97 * z1 – 0.02 * z2 + e1
(以上的数字代表实际为变量间的
相关系数,值越大,相关性越大)
第一个公因子z1主要与价格、是否快餐、能量有关,代表“价格与营养”
第二个公因子z2主要与味道、风味有关,代表“口味”
e1-5是特殊因子,是公因子中无法解释的,在分析中一般略去。
同时,我们也可以将公因子z1、z2表示成原始变量的线性组合,用于后续分析。
(二)使用条件:
(1)样本量足够大。通常要求样本量是变量数目的5倍以上,且大于100例。
(2)原始变量之间具有相关性。如果变量之间彼此独立,无法使用
因子分析。在SPSS中可用KMO检验和Bartlett球形检验来判断。
(3)生成的公因子要有实际的意义,必要时可通过因子旋转(坐标变化)来达到。
联系:两者都是
降维和信息浓缩的方法。生成的新变量均代表了原始变量的大部分信息且互相独立,都可以用于后续的
回归分析、
判别分析、
聚类分析等等。
区别:
(1)主成分分析是按照
方差最大化的方法生成的新变量,强调新变量贡献了多大比例的
方差,不关心新变量是否有明确的实际意义。
(2)
因子分析着重要求新变量具有实际的意义,能解释原始变量间的内在结构。
SPSS没有提供单独的主成分分析方法,而是混在
因子分析当中,下面通过一个例子来讨论主成分分析与
因子分析的实现方法及相关问题。
一、问题提出
男子十项全能比赛包含100米跑、跳远、跳高、撑杆跳、铅球、铁饼、标枪、400米跑、1500米跑、110米跨栏十个项目,总分为各个项目得分之和。为了分析十项全能主要考察哪些方面的能力,以便有针对性的进行训练,研究者收集了134个顶级运动员的十项全能成绩单,将通过
因子分析来达到分析目的。
二、分析过程
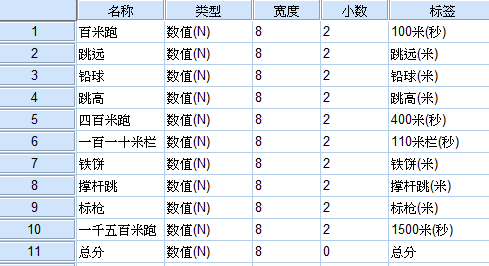
变量视图:
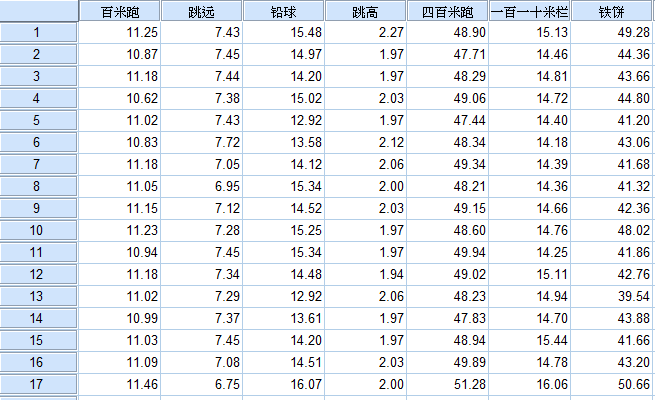
数据视图(部分):
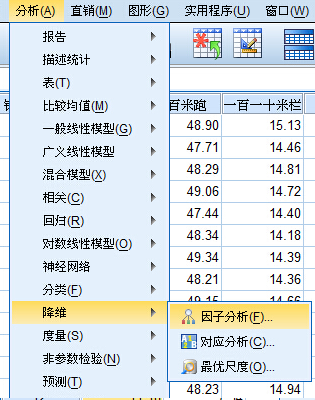
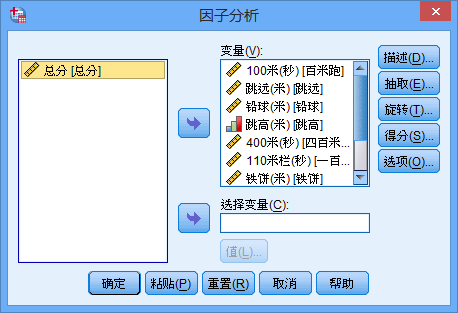
打开
因子分析的主界面,将十项成绩选入”变量“框中(不要包含总分),如下:
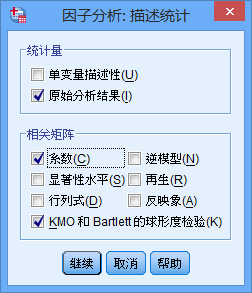
点击”描述“按钮,打开对话框,选中”系数“和”KMO和Bartlett球形度检验“:
上图相关解释:
”系数“:为变量之间的
相关系数阵列,可以直观的分析相关性。
”KMO和Bartlett球形度检验“:用于定量的检验变量之间是否具有相关性。
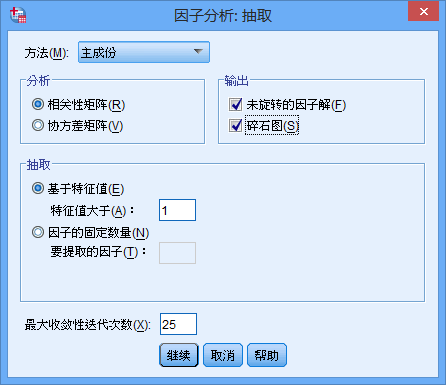
点击”继续“,回到主界面,点击”抽取“,打开对话框。
”方法“ =>”主成分“,”输出“=>”未旋转的因子解“和”碎石图“,”抽取“=>”基于
特征值“,其余选择默认。
解释:
①因子抽取的方法:选取默认的主成分法即可,其余方法的计算结果可能有所差异。
②输出:”未旋转的因子解”极为主成分分析结果。碎石图有助于我们判断因子的重要性(详细介绍见后面)。
③抽取:为抽取主成分(因子)的方法,一般是基于
特征值大于1,默认即可。
点击”继续“,回到主界面,点击”确定“,进入分析。
输出的主要表格如下:
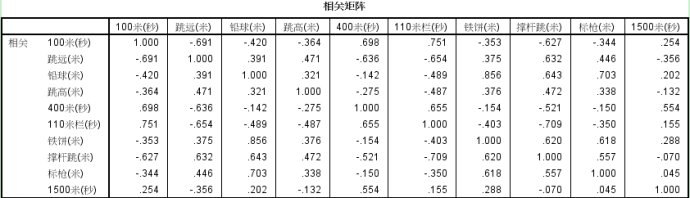
(1)相关性检验
因子分析要求变量之间有相关性,所以首先要进行相关性检验。首先输出的是变量之间的
相关系数矩阵:
可以直观的看到,变量之间有相关性。但需要检验,接着输出的是相关性检验:
上图有两个指标:第一个是KMO值,一般大于0.7就说明不了之间有相关性了。第二个是Bartlett球形度检验,P值<0.001。综合两个指标,说明变量之间存在相关性,可以进行
因子分析。否则,不能进行
因子分析。
(2)提取主成分和公因子
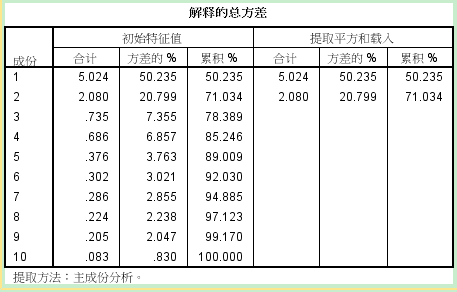
接下来输出主成分结果:
这就是主成分分析的结果,表中第一列为10个成分;第二列为对应的”
特征值“,表示所解释的
方差的大小;第三列为对应的成分所包含的
方差占总
方差的百分比;第四列为累计的百分比。一般来说,选择”
特征值“大于1的成分作为主成分,这也是SPSS默认的选择。
在本例中,成分1和2的
特征值大于1,他们合计能解释71.034%的
方差,还算不错。所以我们可以提取1和2作为主成分,抓住了主要矛盾,其余成分包含的信息较少,故弃去。
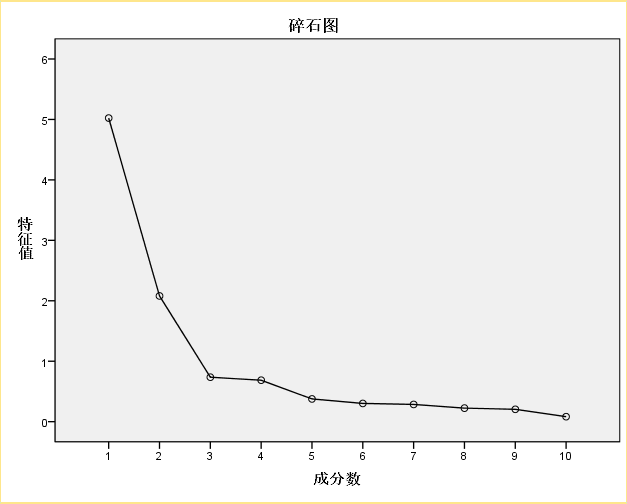
下面,输出碎石图,如下:
碎石图来源于地质学的概念。在岩层斜坡下方往往有很多小的碎石,其地质学意义不大。碎石图以
特征值为纵轴,成分为横轴。前面陡峭的部分
特征值大,包含的信息多,后面平坦的部分
特征值小,包含的信息也小。
由图直观的看出,成分1和2包含了大部分信息,从3开始就进入平台了。
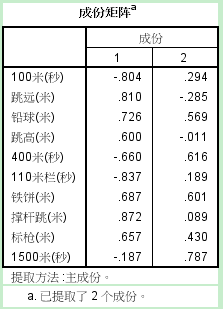
接下来,输出提取的成分矩阵:
上表中的数值为公因子与原始变量之间的
相关系数,绝对值越大,说明关系越密切。公因子1和9个运动项目都正相关(注意跑步运动运动的计分方式,时间越短,分数越高),看来只能称为“综合运动”因子了。公因子2与铁饼、铅球正相关,与1500米跑、400米跑负相关,这究竟代表什么意思呢?看来只能成为“不知所云”因子了。
(三)因子旋转
前面提取的两个公因子一个是大而全的“综合因子”,一个不知所云,得到这样的结果,无疑是分析的失败。不过,不要灰心,我们可以通过因子的旋转来获得更好的解释。在主界面中点击“旋转”按钮,打开对话框,“方法”=>“最大
方差法”,“输出”=>“旋转解”。
点击“继续”,回到主界面点击“确认”进行分析。输出结果如下:
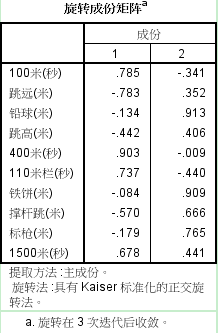
这是选择后的成分矩阵。经过旋转,可以看出:
公因子1得分越高,所有的跑步和跨栏成绩越差,而跳远、撑杆跳等需要助跑类项目的成绩也越差,所以公因子1代表的是奔跑能力的反向指标,可称为“奔跑能力”。
公因子2与铁饼和铅球的正相关性很高,与标枪、撑杆跳等需要上肢力量的项目也正相关,所以该因子可以成为“上肢力量”。
经过旋转,可以看出公因子有了更合理的解释。
(四)结果的保存
在最后,我们还要将公因子储存下来供后续使用。点击“得分”按钮,打开对话框,选中“保存为变量”,方法采用默认的“回归”方法,同时选中“显示因子得分系数矩阵”。
SPSS会自动生成2个新变量,分别为公因子的取值,放在数据的最后。同时会输出一个因子系数表格:
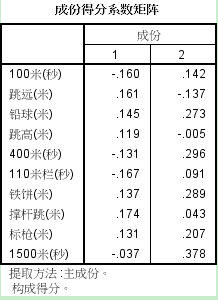
由上图,我们可以写出公因子的表达式(用F1、F2代表两个公因子,Z1~Z10分别代表原始变量):
F1 = -0.16*Z1+0.161*Z2+0.145*Z3+0.199*Z4-0.131*Z5-0.167*Z6+0.137*Z7+0.174*Z8+0.131*Z9-0.037*Z10
F2同理,略去。
注意,这里的变量Z1~Z10,F1、F2不再是原始变量,而是标准正态变换后的变量。
推荐学习书籍
《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~

免费加入阅读:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试详情;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试详情;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;