大数据进入企业 应如何继承传统的数据处理方式-CDA数据分析师
当Hadoop进入企业,必须面对一个问题,那就是怎样解决和应对传统并成熟的IT信息架构。业内部,如何处理原有的结构化数据是企业进入大数据领域所面对的难题。
当Hadoop进入企业,必须面对一个问题,那就是怎样解决和应对传统并成熟的IT信息架构。以往MapReduce主要用来解决日志文件分析、互联网点击流、互联网索引、机器学习、金融分析、科学模拟、影像存储、矩阵计算等非结构化数据。但在企业内部,如何处理原有的结构化数据是企业进入大数据领域所面对的难题。企业需要既能处理非结构化数据,又能处理结构化数据的大数据技术。
在大数据时代,Hadoop主要用来处理非结构化数据,而如何处理传统IOE架构的结构化数据则成为企业面临的一个难题。在此背景下,既能处理结构化数据又能处理非结构化数据的SQL on Hadoop应运而生。
SQL on Hadoop是2013年最热门的话题,它由Cloudera Impala的发布版推到热议。目前,SQL on Hadoop正处于起步阶段,其技术实践方式很多样。而企业由于已经适应了在小数据上的灵活处理方式,转到Hadoop一下子变得无所适从,所以对SQL on Hadoop的呼声越来越大。SQL on Hadoop既要保证Hadoop性能,又要保证SQL的灵活性。关于SQL on Hadoop,业界有不同的看法,业内专业大数据公司也在积极的研究。
1.传统方式的DB on TOP
一些北美厂商采用传统方式的DB on TOP来解决SQL on Hadoop,即组合利用不同的计算框架面向不同的数据操作。其中以EMC Greenplum、Hadapt、Citus Data为代表。Hadapt以PostgreSQL架接在Hadoop上,来完成对结构化数据的查询。它提供了统一的数据处理环境,利用Hadoop的高扩展性和关系数据库的高速性,分开执行Hadoop和关系数据库之间的查询。Citus Data通过把多种数据类型转化成数据库的原生类型,运用分布式处理技术来完成查询。
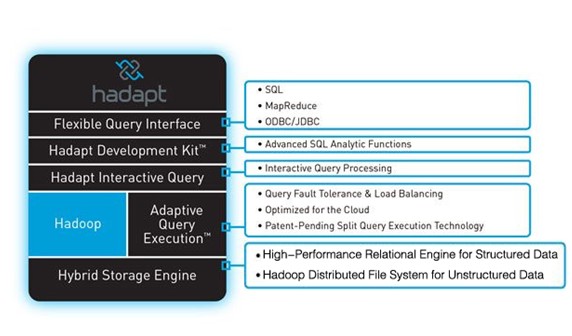
图1、Hadapt
DB on Top 方式是业内同事解决结构化与非结构化数据的最初尝试,最早由Hadapt公司在2010年提出,也就绪了能够跑在Amazon EMR上的社区版。但是,其本质是数据在两种计算框架中分别存放,如图1所示,结构化数据存储于高性能关系型数据引擎(High-Performance Relational Engine for Structured Data),非结构化数据存储于Hadoop分布文件系统(Hadoop Distributed File System for Unstructured Data),对两种类型的数据交互依靠查询的切片执行,元数据的组织控制必然是系统扩展演变中的过度技术。
2.原生态Hive的优化
在开源社区方面,以Hortonworks的Stinger、Apache Drill为例。Hortonworks的Stinger通过对原生态Hive做改造,优化SQL查询速度,使其达到5-30秒,完成对SQL查询。Apache Drill通过对原生态的Hive做优化,完成对SQL的查询。
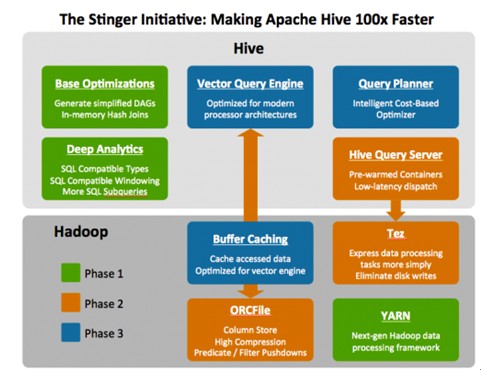
图2、Hortonworks Stinger
开源社区原生态的改造,目标是建立共同的计算框架和接口,目前各个开源项目虽然还只是孵化阶段,也还是获得了业内的支持,例如Apache的Drill项目,因开放的数据格式和查询语言,就获得了专业的Hadoop商业发行版供应商MapR的支持。
开源社区的发展和贡献,将成为推动SQL on Hadoop大规模落地行业的主要力量。
3.人机流程交互
在国内,对于SQL on Hadoop,主要是从SQL的数据处理流程和即席分析两方面来进行。在SQL的数据处理流程方面,很多操作是可以通过对数据处理流程进行预定义,然后对MapReduce作业进行批处理。例如ETL流程处理。ETL流程处理是对数据进行抽取、清洗、转换、加载的阶段。在此阶段,通过对数据流程进行预定义,在一个人机交互的友好界面上把MapReduce作业预先组装好,进行拖拽等操作形成工作流,来解决传统的SQL。
4.多级索引结构的即席查询
大数据的即席查询是大数据所面临的一个难题。在PB级别的数据,其查询效率和查询性能都不尽如意。在传统DW环境下,企业多采用OLAP cube。OLAP cube通过对数据进行预处理,将数据根据维度进行最大限度的聚类运算,通过对维度的配置,可以完成对小数据即席分析。但是对于PB级别的大数据环境,如何建立大数据的cube来兼顾前端应用的灵活性和查询效率呢? HBase自带的哈希快速定位功能可以实现即席查询的毫秒级响应和高并发。天云大数据通过在HBase上构建多级索引以及引用MPP方式基于统计分析的分区设计,不仅解决了HBase查询不灵活的特点,还能满足对PB级别大数据的即席查询。
对于操作型Hadoop,其对SQL on Hadoop 数据查询、响应等已经由存储磁盘级转移到内存上。由于其分布内存一致性要求,使得其发展比较缓慢,目前还不能达到企业应用级别。目前,分布式内存计算已渐趋繁荣,比较有代表的技术先锋如Splice Machine、SQLstream等。目前对于操作型Hadoop,业界正在积极探索中。
面对企业多年运营所积累的大量结构化数据,SQL on Hadoop无疑成为了分布式计算框架进入企业传统计算市场的敲门砖,但我们更清楚的认识到,Hadoop等主流分布式计算的舞台远不如此,它为企业计算定义了一个更为广阔的零消费市场(White Space)解决SQL之外的计算。
纷繁复杂的世界不可能简单地由平面展开的表结构来描述,SQL能够胜任查询和数值计算工作。但大量碎片的文字信息、影像图片如何计算?“买入”+“大涨”等于什么?“女性”+“Dior”等于“优雅”还是“性感”?能否用Sum、Group By、Join SQL来做非结构化信息的主题缩略、分类、聚类,我们将在后续文章中探讨这些话题。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27






