数据挖掘算法与生活中的应用案例
如何分辨出垃圾邮件”、“如何判断一笔交易是否属于欺诈”、“如何判断红酒的品质和档次”、“扫描王是如何做到文字识别的”、“如何判断佚名的著作是否出自某位名家之手”、“如何判断一个细胞是否属于肿瘤细胞”等等,这些问题似乎都很专业,都不太好回答。但是,如果了解一点点数据挖掘的知识,你,或许会有柳暗花明的感觉。
本文,主要想简单介绍下数据挖掘中的算法,以及它包含的类型。然后,通过现实中触手可及的、活生生的案例,去诠释它的真实存在。
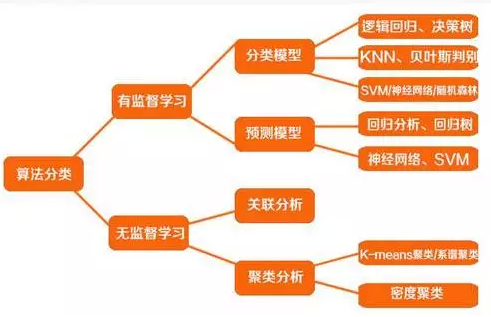
一般来说,数据挖掘的算法包含四种类型,即分类、预测、聚类、关联。前两种属于有监督学习,后两种属于无监督学习,属于描述性的模式识别和发现。
有监督的学习,即存在目标变量,需要探索特征变量和目标变量之间的关系,在目标变量的监督下学习和优化算法。例如,信用评分模型就是典型的有监督学习,目标变量为“是否违约”。算法的目的在于研究特征变量(人口统计、资产属性等)和目标变量之间的关系。
分类算法
分类算法和预测算法的最大区别在于,前者的目标变量是分类离散型(例如,是否逾期、是否肿瘤细胞、是否垃圾邮件等),后者的目标变量是连续型。一般而言,具体的分类算法包括,逻辑回归、决策树、KNN、贝叶斯判别、SVM、随机森林、神经网络等。
预测算法
无监督学习,即不存在目标变量,基于数据本身,去识别变量之间内在的模式和特征。例如关联分析,通过数据发现项目A和项目B之间的关联性。例如聚类分析,通过距离,将所有样本划分为几个稳定可区分的群体。这些都是在没有目标变量监督下的模式识别和分析。
聚类分析
聚类的目的就是实现对样本的细分,使得同组内的样本特征较为相似,不同组的样本特征差异较大。常见的聚类算法包括kmeans、系谱聚类、密度聚类等。
关联分析
关联分析的目的在于,找出项目(item)之间内在的联系。常常是指购物篮分析,即消费者常常会同时购买哪些产品(例如游泳裤、防晒霜),从而有助于商家的捆绑销售。
上文所提到的四种算法类型(分类、预测、聚类、关联),是比较传统和常见的。还有其他一些比较有趣的算法分类和应用场景,例如协同过滤、异常值分析、社会网络、文本分析等。下面,想针对不同的算法类型,具体的介绍下数据挖掘在日常生活中真实的存在。下面是能想到的、几个比较有趣的、和生活紧密关联的例子。
基于分类模型的案例
这里面主要想介绍两个案例,一个是垃圾邮件的分类和判断,另外一个是在生物医药领域的应用,即肿瘤细胞的判断和分辨。
垃圾邮件的判别
邮箱系统如何分辨一封Email是否属于垃圾邮件?这应该属于文本挖掘的范畴,通常会采用朴素贝叶斯的方法进行判别。它的主要原理是,根据邮件正文中的单词,是否经常出现在垃圾邮件中,进行判断。例如,如果一份邮件的正文中包含“报销”、“发票”、“促销”等词汇时,该邮件被判定为垃圾邮件的概率将会比较大。
一般来说,判断邮件是否属于垃圾邮件,应该包含以下几个步骤。
第一,把邮件正文拆解成单词组合,假设某篇邮件包含100个单词。
第二,根据贝叶斯条件概率,计算一封已经出现了这100个单词的邮件,属于垃圾邮件的概率和正常邮件的概率。如果结果表明,属于垃圾邮件的概率大于正常邮件的概率。那么该邮件就会被划为垃圾邮件。
医学上的肿瘤判断
如何判断细胞是否属于肿瘤细胞呢?肿瘤细胞和普通细胞,有差别。但是,需要非常有经验的医生,通过病理切片才能判断。如果通过机器学习的方式,使得系统自动识别出肿瘤细胞。此时的效率,将会得到飞速的提升。并且,通过主观(医生)+客观(模型)的方式识别肿瘤细胞,结果交叉验证,结论可能更加靠谱。
如何操作?通过分类模型识别。简言之,包含两个步骤。首先,通过一系列指标刻画细胞特征,例如细胞的半径、质地、周长、面积、光滑度、对称性、凹凸性等等,构成细胞特征的数据。其次,在细胞特征宽表的基础上,通过搭建分类模型进行肿瘤细胞的判断。
基于预测模型的案例
这里面主要想介绍两个案例。即通过化学特性判断和预测红酒的品质。另外一个是,通过搜索引擎来预测和判断股价的波动和趋势。
红酒品质的判断
如何评鉴红酒?有经验的人会说,红酒最重要的是口感。而口感的好坏,受很多因素的影响,例如年份、产地、气候、酿造的工艺等等。但是,统计学家并没有时间去品尝各种各样的红酒,他们觉得通过一些化学属性特征就能够很好地判断红酒的品质了。并且,现在很多酿酒企业其实也都这么干了,通过监测红酒中化学成分的含量,从而控制红酒的品质和口感。
那么,如何判断鉴红酒的品质呢?
第一步,收集很多红酒样本,整理检测他们的化学特性,例如酸性、含糖量、氯化物含量、硫含量、酒精度、PH值、密度等等。
第二步,通过分类回归树模型进行预测和判断红酒的品质和等级。
搜索引擎的搜索量和股价波动
一只南美洲热带雨林中的蝴蝶,偶尔扇动了几下翅膀,可以在两周以后,引起美国德克萨斯州的一场龙卷风。你在互联网上的搜索是否会影响公司股价的波动?
很早之前,就已经有文献证明,互联网关键词的搜索量(例如流感)会比疾控中心提前1到2周预测出某地区流感的爆发。
同样,现在也有些学者发现了这样一种现象,即公司在互联网中搜索量的变化,会显著影响公司股价的波动和趋势,即所谓的投资者注意力理论。该理论认为,公司在搜索引擎中的搜索量,代表了该股票被投资者关注的程度。因此,当一只股票的搜索频数增加时,说明投资者对该股票的关注度提升,从而使得该股票更容易被个人投资者购买,进一步地导致股票价格上升,带来正向的股票收益。这是已经得到无数论文验证了的。
基于关联分析的案例:沃尔玛的啤酒尿布
啤酒尿布是一个非常非常古老陈旧的故事。故事是这样的,沃尔玛发现一个非常有趣的现象,即把尿布与啤酒这两种风马牛不相及的商品摆在一起,能够大幅增加两者的销量。原因在于,美国的妇女通常在家照顾孩子,所以,她们常常会嘱咐丈夫在下班回家的路上为孩子买尿布,而丈夫在买尿布的同时又会顺手购买自己爱喝的啤酒。沃尔玛从数据中发现了这种关联性,因此,将这两种商品并置,从而大大提高了关联销售。
啤酒尿布主要讲的是产品之间的关联性,如果大量的数据表明,消费者购买A商品的同时,也会顺带着购买B产品。那么A和B之间存在关联性。在超市中,常常会看到两个商品的捆绑销售,很有可能就是关联分析的结果。
对客户的细分,还是比较常见的。细分的功能,在于能够有效的划分出客户群体,使得群体内部成员具有相似性,但是群体之间存在差异性。其目的在于识别不同的客户群体,然后针对不同的客户群体,精准地进行产品设计和推送,从而节约营销成本,提高营销效率。
例如,针对商业银行中的零售客户进行细分,基于零售客户的特征变量(人口特征、资产特征、负债特征、结算特征),计算客户之间的距离。然后,按照距离的远近,把相似的客户聚集为一类,从而有效的细分客户。将全体客户划分为诸如,理财偏好者、基金偏好者、活期偏好者、国债偏好者、风险均衡者、渠道偏好者等。
基于异常值分析的案例:支付中的交易欺诈侦测
采用支付宝支付时,或者刷信用卡支付时,系统会实时判断这笔刷卡行为是否属于盗刷。通过判断刷卡的时间、地点、商户名称、金额、频率等要素进行判断。这里面基本的原理就是寻找异常值。如果您的刷卡被判定为异常,这笔交易可能会被终止。
异常值的判断,应该是基于一个欺诈规则库的。可能包含两类规则,即事件类规则和模型类规则。第一,事件类规则,例如刷卡的时间是否异常(凌晨刷卡)、刷卡的地点是否异常(非经常所在地刷卡)、刷卡的商户是否异常(被列入黑名单的套现商户)、刷卡金额是否异常(是否偏离正常均值的三倍标准差)、刷卡频次是否异常(高频密集刷卡)。第二,模型类规则,则是通过算法判定交易是否属于欺诈。一般通过支付数据、卖家数据、结算数据,构建模型进行分类问题的判断。
电商中的猜你喜欢,应该是大家最为熟悉的。在京东商城或者亚马逊购物,总会有“猜你喜欢”、“根据您的浏览历史记录精心为您推荐”、“购买此商品的顾客同时也购买了商品”、“浏览了该商品的顾客最终购买了商品”,这些都是推荐引擎运算的结果。
这里面,确实很喜欢亚马逊的推荐,通过“购买该商品的人同时购买了**商品”,常常会发现一些质量比较高、较为受认可的书。
一般来说,电商的“猜你喜欢”(即推荐引擎)都是在协同过滤算法(Collaborative Filter)的基础上,搭建一套符合自身特点的规则库。即该算法会同时考虑其他顾客的选择和行为,在此基础上搭建产品相似性矩阵和用户相似性矩阵。基于此,找出最相似的顾客或最关联的产品,从而完成产品的推荐。
基于社会网络分析的案例:电信中的种子客户
种子客户和社会网络,最早出现在电信领域的研究。即,通过人们的通话记录,就可以勾勒出人们的关系网络。电信领域的网络,一般会分析客户的影响力和客户流失、产品扩散的关系。
基于通话记录,可以构建客户影响力指标体系。采用的指标,大概包括如下,一度人脉、二度人脉、三度人脉、平均通话频次、平均通话量等。基于社会影响力,分析的结果表明,高影响力客户的流失会导致关联客户的流失。其次,在产品的扩散上,选择高影响力客户作为传播的起点,很容易推动新套餐的扩散和渗透。
此外,社会网络在银行(担保网络)、保险(团伙欺诈)、互联网(社交互动)中也都有很多的应用和案例。
基于文本分析的案例
这里面主要想介绍两个案例。一个是类似“扫描王”的APP,直接把纸质文档扫描成电子文档。相信很多人都用过,这里准备简单介绍下原理。另外一个是,江湖上总是传言红楼梦的前八十回和后四十回,好像并非都是出自曹雪芹之手,这里面准备从统计的角度聊聊。
字符识别:扫描王APP
手机拍照时会自动识别人脸,还有一些APP,例如扫描王,可以扫描书本,然后把扫描的内容自动转化为word。这些属于图像识别和字符识别(Optical Character Recognition)。图像识别比较复杂,字符识别理解起来比较容易些。
查找了一些资料,字符识别的大概原理如下,以字符S为例。
第一,把字符图像缩小到标准像素尺寸,例如12*16。注意,图像是由像素构成,字符图像主要包括黑、白两种像素。
第二,提取字符的特征向量。如何提取字符的特征,采用二维直方图投影。就是把字符(12*16的像素图)往水平方向和垂直方向上投影。水平方向有12个维度,垂直方向有16个维度。这样分别计算水平方向上各个像素行中黑色像素的累计数量、垂直方向各个像素列上的黑色像素的累计数量。从而得到水平方向12个维度的特征向量取值,垂直方向上16个维度的特征向量取值。这样就构成了包含28个维度的字符特征向量。
第三,基于前面的字符特征向量,通过神经网络学习,从而识别字符和有效分类。
文学著作与统计:红楼梦归属
这是非常著名的一个争论,悬而未决。对于红楼梦的作者,通常认为前80回合是曹雪芹所著,后四十回合为高鹗所写。其实主要问题,就是想确定,前80回合和后40回合是否在遣词造句方面存在显著差异。
这事让一群统计学家比较兴奋了。有些学者通过统计名词、动词、形容词、副词、虚词出现的频次,以及不同词性之间的相关系做判断。有些学者通过虚词(例如之、其、或、亦、了、的、不、把、别、好),判断前后文风的差异。有些学者通过场景(花卉、树木、饮食、医药与诗词)频次的差异,来做统计判断。总而言之,主要通过一些指标量化,然后比较指标之间是否存在显著差异,藉此进行写作风格的判断。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试详情;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试详情;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;