我的大数据研究轨迹
我做了4-5年的移动架构和Java虚拟机,4-5年的众核架构和并行编程系统,最近4-5年也在追时髦,先是投入物联网,最近几年一直在做大数据。我们团队的大数据研究轨迹如下图所示:
2010-2012年,主要关注数据和机器的关系:水平扩展、容错、一致性、软硬件协同设计,同时厘清各种计算模式,从批处理(MapReduce)到流处理、Big SQL/ad hoc query、图计算、机器学习等等。事实上,我们的团队只是英特尔大数据研发力量的一部分,上海的团队是英特尔Hadoop发行版的主力军,现在英特尔成了Cloudera的最大股东,自己不做发行版了,但是平台优化、开源支持和垂直领域的解决方案仍然是英特尔大数据研发的重心。
从2013年开始关注数据与人的关系:对于数据科学家怎么做好分布式机器学习、特征工程与非监督学习,对于领域专家来说怎么做好交互式分析工具,对于终端用户怎么做好交互式可视化工具。英特尔研究院在美国卡内基梅隆大学支持的科研中心做了GraphLab、Stale Synchronous Parallelism,在MIT的科研中心做了交互式可视化和SciDB上的大数据分析,而中国主要做了Spark SQL和MLlib(机器学习库),现在也涉及到深度学习算法和基础设施。
2014年重点分析数据和数据的关系:我们原来的工作重心是开源,后来发现开源只是开放式创新的一个部分,做大数据的开放式创新还要做数据的开放、大数据基础设施的开放以及价值提取能力的开放。
数据的暗黑之海与外部效应
下面是一张非常有意思的图,黄色部分是化石级的,即没有联网、没有数字化的数据,而绝大多数的数据是在这片海里面。只有海平面的这些数据(有人把它称作Surface Web)才是真正大家能访问到的数据,爬虫能爬到、搜索引擎能检索到的数据,而绝大多数的数据是在暗黑之海里面(相应地叫做Dark Web),据说这一部分占数据总量的85%以上,它们在一些孤岛里面,在一些企业、政府里面躺在地板上睡大觉。
数据之于数据社会,就如同水之于城市或者血液之于身体一样。城市因为河流而诞生也受其滋养,血液一旦停滞身体也就危在旦夕。所以,对于号称数据化生存的社会来说,我们一定要让数据流动起来,不然这个社会将会丧失诸多重要功能。
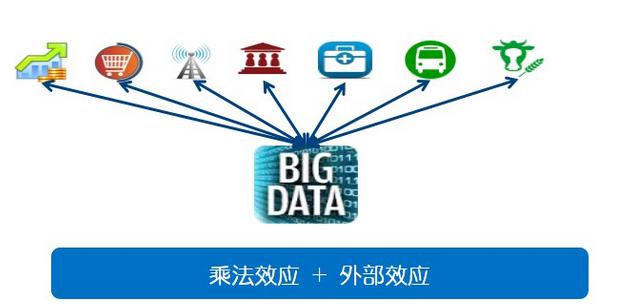
所以,我们希望数据能够像“金风玉露一相逢”那样产生化学作用。马化腾先生提出了一个internet+的概念,英特尔也有一个大数据X,相当于大数据乘以各行各业。如下图所示,乘法效应之外,数据有个非常奇妙的效应叫做外部效应(externality),比如这个数据对我没用但对TA很有用,所谓我之毒药彼之蜜糖。
比如,金融数据和电商数据碰撞在一起,就产生了像小微贷款那样的互联网金融;电信数据和政府数据相遇,可以产生人口统计学方面的价值,帮助城市规划人们居住、工作、娱乐的场所;金融数据和医学数据在一起,麦肯锡列举了很多应用,比如可以发现骗保;物流数据和电商数据凑在一块,可以了解各个经济子领域的运行情况;物流数据和金融数据产生供应链金融,而金融数据和农业数据也能发生一些化学作用。比如Google analytics出来的几个人,利用美国开放气象数据,在每一块农田上建立微气象模型,可以预测灾害,帮助农民保险和理赔。
所以,要走数据开放之路,让不同领域的数据真正流动起来、融合起来,才能释放大数据的价值。
三个关于开放的概念
1、数据开放
首先是狭义的数据开放。数据开放的主体是政府和科研机构,把非涉密的政府数据及科研数据开放出来。现在也有一些企业愿意开放数据,像Netflix和一些电信运营商,来帮助他们的数据价值化,建构生态系统。但是数据开放不等于信息公开。首先,数据不等于信息,信息是从数据里面提炼出来的东西。我们希望,首先要开放原始的数据(raw data),其次,它是一种主动和免费的开放,我们现在经常听说要申请信息公开,那是被动的开放。
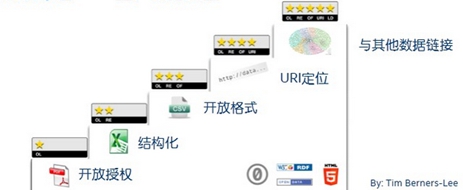
Tim Berners Lee提出了数据开放的五星标准,以保证数据质量:一星是开放授权的格式,比如说PDF;其次是结构化,把数据从文件变成了像excel这样的表;三星是开放格式,如CSV;四星是能够通过URI找到每一个数据项;五星代表能够和其它数据链接,形成一个开放的数据图谱。
现在主流的数据开放门户,像data.dov或data.gov.uk,都是基于开源软件。英特尔在MIT的大数据科研中心也做了一种形态,叫Datahub:吉祥物很有趣,一半是大象,代表数据库技术,一半是章鱼,取自github的吉祥物章鱼猫。它提供更多的功能比如易管理性,提供结构化数据服务和访问控制,对数据共享进行管理,同时可以在原地做可视化和分析。
广义的数据开放还有数据的共享及交易,比如点对点进行数据共享或在多边平台上做数据交易。马克思说生产资料所有制是经济的基础,但是现在大家可以发现,生产资料的租赁制变成了一种主流(参考《Lean Startup》),在数据的场景下,我不一定拥有数据,甚至不用整个数据集,但可以租赁。租赁的过程中要保证数据的权利。
首先,我可以做到数据给你用,但不可以给你看见。姚期智老先生82年提出“millionaires’ dilemma(百万富翁的窘境)”,两个百万富翁比富谁都不愿意说出自己有多少钱,这就是典型的“可用但不可见”场景。在实际生活中的例子很多,比如美国国土安全部有恐怖分子名单(数据1),航空公司有乘客飞行记录(数据2),国土安全部向航空公司要乘客飞行记录,航空公司不给,因为涉及隐私,他反过来向国土安全部要恐怖分子名单,也不行,因为是国家机密。双方都有发现恐怖分子的意愿,但都不愿给出数据,有没有办法让数据1和数据2放一起扫一下,但又保障数据安全呢?
其次,在数据使用过程中要有审计,万一那个扫描程序偷偷把数据藏起来送回去怎么办?再者,需要数据定价机制,双方数据的价值一定不对等,产生的洞察对各方的用途也不一样,因此要有个定价机制,比大锅饭式的数据共享更有激励性。
从点对点的共享,走到多边的数据交易,从一对多的数据服务到多对多的数据市场,再到数据交易所。如果说现在的数据市场更多是对数据集进行买卖的话,那么数据交易所就是一个基于市场进行价值发现和定价的,像股票交易所那样的、小批量、高频率的数据交易。
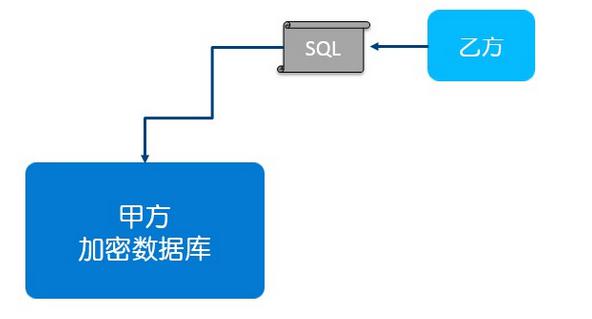
我们支持了不少研究来实现刚才所说的这些功能,比如说可用而不可见。案例一是通过加密数据库CryptDB/Monomi实现,在数据拥有方甲方这边的数据库是完全加密的,这事实上也防止了现在出现的很多数据泄露问题,大家已经听到,比如说某互联网服务提供商的员工偷偷把数据拿出来卖,你的数据一旦加密了他拿出来也没用。其次,这个加密数据库可以运行乙方的普通SQL程序,因为它采用了同态加密技术和洋葱加密法,SQL的一些语义在密文上也可以执行。
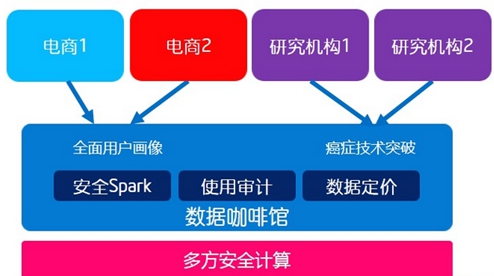
针对“百万富翁的窘境”,我们做了另一种可用但不可见的技术,叫做数据咖啡馆。大家知道咖啡馆是让人和人进行思想碰撞的地方,这个数据咖啡馆就是让数据和数据能够碰撞而产生新的价值。
比如两个电商,一个是卖衣服的,一个是卖化妆品的,他们对于客户的洞察都是相对有限的,如果两边的数据放在一起做一次分析,那么就能够获得全面的用户画像。再如,癌症是一类长尾病症,有太多的基因突变,每个研究机构的基因组样本都相对有限,这在某种程度上解释了为什么过去50年癌症的治愈率仅仅提升了8%。那么,多个研究机构的数据在咖啡馆碰一碰,也能够加速癌症的研究。
在咖啡馆的底层是多方安全计算的技术,基于英特尔和伯克利的一个联合研究。在上面是安全、可信的Spark,基于“data lineage”的使用审计,根据各方数据对结果的贡献进行定价。
2、大数据基础设施的开放
现在有的是有大数据思维的人,但他们很捉急,玩不起、玩不会大数据,他不懂怎么存储、怎么处理这些大数据,这就需要云计算。基础设施的开放还是传统的Platform as a Service,比如Amazon AWS里有MapReduce,Google有Big Query。这些大数据的基础处理和分析平台可以降低数据思维者的门槛,释放他们的创造力。
比如decide.com,每天爬几十万的数据,对价格信息(结构化的和非结构化的)进行分析,然后告诉你买什么牌子、什么时候买最好。只有四个PhD搞算法,其他的靠AWS。另一家公司Prismatic,也利用了AWS,这是一家做个性化阅读推荐的,我专门研究过它的计算图、存储和高性能库,用LISP的一个变种Clojure写的非常漂亮,真正做技术的只有三个学生。
所以当这些基础设施社会化以后,大数据思维者的春天很快就要到来。
3、价值提取能力的开放
现在的模式一般是一大一小或一对多。比如Tesco和Dunnhumby,后者刚开始是很小的公司,找到Tesco给它做客户忠诚度计划,一做就做了几十年,这样的长期战略合作优于短期的数据分析服务,决策更注重长期性。当然,Dunnhumby现在已经不是小公司了,也为其他大公司提供数据分析服务。再如沃尔玛和另外一家小公司合作,做数据分析,最后他把这家小公司买下来了,成了它的Walmart Labs。
一对多的模式,典型的是Palantir——Peter Thiel和斯坦福的几个教授成立的公司,目前还是私有的,但估值近百亿了,它很擅长给各类政府和金融机构提供数据价值提取服务。真正把这种能力开放的是Kaggle,它的双边,一边是10多万的分析师,另一边是需求方企业,企业在Kaggle上发标,分析师竞标,获得业务。这可能是真正解决长尾公司价值提取能力的办法。当然,如果能和我们的数据咖啡馆结合,就更好了。