基于用户行为分析建立用户偏好模型
我们经常将个性化推荐的思想简单地抽象为:通过用户的行为推测出用户的兴趣,从而给用户推荐满足他们兴趣的物品。那我们其实就是要通过用户行为分析建立一个用户偏好(偏好即兴趣)模型,模型中包含各个用户的一个或更多个偏好。
插叙一段
像「用户行为」,「用户兴趣」这样的词,大多数人都有一个默认的感知,甚至对于这种词的理解可能已固化为常识,所以我很少见到有文章使用这些词时解释它们。我感觉涉及到算法模型时,对这些词的不加限定的宽泛认知就容易影响对算法模型的深入理解,会导致感知模糊却不自知。因为不同人对这些词的基本理解可能一致,但是拓展理解各不相同。本文会作出限定解释,且本文所谈用户行为都是指网络(可以是电信网络,互联网)上的行为。
概念解释
实体域
当我们想基于用户行为分析来建立用户偏好模型时,我们必须把用户行为和兴趣主题限定在一个实体域上。个性化推荐落实在具体的推荐中都是在某个实体域的推荐。比如对于阅读网站,实体域包括所有的图书,我们可以称之为图书域。其他还有,个性化音乐推荐,个性化电影推荐,个性化资讯推荐等。
用户行为
用户在门户网站点击资讯,评论资讯,在社交网站发布状态,评论状态,在电商网站浏览商品,购买商品,点评商品,以及在其他类型网站的种种行为都可是用户行为。本文所指的用户行为都是指用户在某实体域上的行为。比如用户在图书域产生的行为有阅读,购买,评分,评论等。
兴趣主题
用户的兴趣维度,同样是限定在某实体域的兴趣,通常可以以标签的形式来表示。比如,对于图书阅读,兴趣主题可以是「悬疑」,「科技」,「情感」等等分类标签。值得一提的是,兴趣主题,只是从用户行为中抽象出来的兴趣维度,并无统一标准。比如qq阅读和豆瓣阅读的图书分类标签大不一样。而兴趣维度的粒度也不固定,就像门户网站有「新闻」,「体育」,「娱乐」等一级分类,而新闻下有「国内」,「社会」,「国际」二级分类,娱乐下有「明星」,「星座」,「八卦」二级分类。我们选取什么粒度的兴趣空间取决于我们对用户偏好模型的要求。
兴趣空间
在同一层次上兴趣维度的集合,比如豆瓣阅读中,可以用「新上架」,「热门」,「特价」,「免费」来构成一个兴趣空间(当然,如果使用这个兴趣空间来表征用户的兴趣,就太粗了,这里只是假设),也可以用「小说」,「幻想」,「计算机」,「科技」,「历史」·····「美食」构成一个兴趣空间。这是两种不同的分类维度。如果将「新上架」也加入到后者集合里,就显然有些莫名其妙。值得一提是,这也并非不可能,这取决于一个如何看待这个集合的问题,如果不把它看作基于内容的分类,而是图书标签库,那么也是可行的,甚至利于建立更好地模型。本文后面我有提到。
用户行为数据
项亮在他的《推荐系统实践》的2.1节有详细介绍。通常在经过对行为日志的汇总处理后生成的比较容易理解的数据就是一份描述用户行为的会话日志。这种日志记录了用户的各种行为,比如在图书阅读app中这些行为主要包括点击,试读,购买,阅读(在本地app中,阅读行为有可能追踪不到),评分,评论。
建立用户偏好模型
基于用户行为分析建立用户偏好模型的核心工作就是:将用户的行为转换为用户的偏好。
我们采用矩阵运算的思维方式,以图书阅读为例说明。
下图表示用户(user)集合:
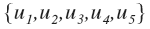
下图表示图书(item)集合:

那么用户的行为矩阵可以表达为:
行表示用户,列表示图书,我们暂只考虑图书的购买行为,1表示用户看过该图书,0表示用户没有看过该图书。
如何将上述用户行为矩阵转化为用户兴趣矩阵(即行代表用户,列代表兴趣维度),一种显著的方法是我们先确定图书与兴趣维度的对应关系矩阵。而这个的前提是我们确定了使用何种兴趣空间。一种常见的方式是专家给出一些样本的分类结果,也就是一般意义的训练数据,然后通过分类算法,得到分类模型,然后应用到其余数据的分类问题当中,解决其余大量数据的分类问题。这种分类的特点是一本图书只被标记为一种类别,假如有3个类别,
那么图书-兴趣矩阵为:
那么用户行为矩阵转换为用户兴趣矩阵的运算公式即可表示为下图,行表示用户,列表示兴趣,算出的矩阵再经过归一化后,每个值就代表某个用户在某个兴趣的偏好权重。
选择这样的兴趣空间的局限显而易见:一本图书只能属于一个兴趣维度。实际情况中,一本图书通常不只属于某个分类,并且当图书的数据巨大时,寄希望于编辑分类可能会越来越难以维持,所以通常是由用户主动给图书添加标签,或者机器基于内容,提取关键词。但是这种形式得到的标签集会存在同义,生僻,维度过多等情况,需要经过标签清洗的重要工作。前面已经看到兴趣空间的选择真的是非常重要,直接影响所得到用户的兴趣矩阵。所以同样的方法都得到了用户偏好,但是好不好用,就跟这部分工作有关了。
用户行为加权
上面展示的用户行为矩阵示例是一个非常简单的,直接可以从数据库里提取的例子。而实际中在数据能够支撑的情况下,我们不可能只考虑一种行为。为了获得更合理的行为矩阵,我们就需要进行行为加权。比如,A1表示用户点击的行为矩阵,A2表示购买的行为矩阵,A3表示评分的行为矩阵,那么加权矩阵就是:
至于各矩阵的权重跟我们建立用户偏好模型的目的有关,如果我们更希望找准用户的品味偏好,那么权重可能是:a1 < a2 < a3;如果我们更希望用户购买,那么权重可能是:a1 < a3 < a2。
其他用户行为分析方法
上面介绍的方法也算是一种主流的方法。但是从上面介绍的「兴趣主题」,「兴趣空间」也可以看出作出好的分类并不容易,分类粒度,分类维度等都不好控制,用户打标签也需要复杂的标签清洗工作。在图书,电影这样的实体域,我们还可以通过类别给用户推荐喜欢的物品,而在个性化资讯推荐领域(这里仅举个例子,资讯推荐应该有其特殊之处),我们不见得能通过类别推荐用户喜欢的资讯,甚至用户本身也不在意类别。我们并不需要显式地构建物品-兴趣对应关系矩阵,也可以将用户和所喜欢类别的物品关联起来。这就涉及到隐含语义分析技术。这个部分会日后在此文补充。
小总结
以上可以看出基于用户行为分析的用户偏好建模的常规方法非常简单明了。事实上也的确如此,在使用这些方法或者思想编写程序计算都不是什么难事。而实际上,我们遇到的问题却并非是方法本身,而是数据本身。数据方面的两大问题是稀疏和长尾分布。通常有行为数据用户很少,而用户的行为对象也集中在不多的物品上。方法易学,而数据问题只能在实战中才能深刻体会,才会发现主要的精力和难点都在解决数据的稀疏和长尾上。希望日后能结合实际问题写写解决数据问题的文章。
此外,上面虽然是用矩阵运算的思想讲述,但我在实际项目中发现其运算的本质其实是对用户行为的统计。所以在实战中,不一定要先建矩阵,再做计算,直接在数据库里使用sql计算非常方便。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330