数据挖掘问答精选收藏
1. 现在有大数据、精准挖掘、人工智能等这么多概念及技术,它们之间的关系以及企业大数据实施的路线图应该是怎样的?
来自用户 SmartMining 的回答:
大数据、数据挖掘、人工智能三者的关系可以简单的理解为:大数据是原材料,数据挖掘是加工厂,而人工智能是数据产品尤其是基于数据挖掘技术建立的专家系统的设计理念。
通过使用数据挖掘技术对大数据进行价值提取、加工,进而设计成可以服务于用户的数据产品,并基于人工智能的思想对该产品做自动优化和人机交互学习,让产品越用越好,最终达到具有生产力的目的。
企业要想开展大数据的实践主要完成以下几件事情:
第一,进行数据采集。除了传统的ETL之外,还可以从互联网采集可用的数据,甚至增加采集数据的设备。进而丰富数据的来源;
第二,对这些数据进行清洗、转换并融合到一起,建立大数据管理平台,即PAAS平台。实现数据资源、计算资源等的共享;
第三,大数据价值探索,基于业务痛点设计可行方案,使用数据挖掘的技术对挖掘数据的价值,并生产出有助于解决企业实际的问题的信息。
以上三者其实互为补充、不可分割又可同步进行。原因如下:
1、数据的应用可以更好的知道大数据平台的建设,知道数据用来干什么、怎么用才能更好的设计管理平台,才能知道哪些数据有用、知道采集哪些数据;
2、大数据管理平台建设周期比较长,因此可以先选择一个主题先做数据挖掘,培养团队的同时也做了技术验证;
3、做数据挖掘应用,也可以反过来验证平台是建设完善,验证大数据管理平台是否可以支撑应用。
2. 决策树树算法目前的应用场景有哪些?像 C4.5,CART,SLIQ,SPRINT,PUBLIC,RainForest 等这些算法,目前都用在哪些行业领域里?来自用户 Philbert 的回答:
楼主的这个问题感觉范围比较广,个人的一点看法如下:
1. 就决策树的这个算法而言,在非常多的行业都会有应用,是不是使用决策树进行挖掘分析个人认为还是要看具体的应用分析目标,广义点说任何一个行业都可能出现适合决策树的应用分析目标,比如:在用决策树进行用户分级评估的时候,凡是积累了一定量的客户资源和数据,涉及对自己行业客户进行深入分析的企业和分析者都可能具备使用决策树的条件。
2 一般来说决策树的应用用往往都是和某一应用分析目标和场景相关的,比如:金融行业可以用决策树做贷款风险评估,保险行业可以用决策树做险种推广预测,医疗行业可以用决策树生成辅助诊断处置模型等等,当一个决策树的应用分析目标和场景确定,那该应用分析目标和场景所处的行业也就自然成为了决策树的应用领域。
注:决策树作为一种数据分析挖掘的方法,可以为任何适合其分析思路和处理方式的应用分析目标和数据服务,所以关注其应用领域的同时,可以考虑更重点的关注适合其使用的应用分析目标和场景。
3. 想学习数据挖掘,该如何构建学习路径呢? 因为学校里好像没有老师比较擅长这方面。该如何自学呢?来自用户 Elationquy 的回答:
数据挖掘的重点是“从大量数据中,提取有价值的信息”,这就说明了数据挖掘需要两个方面的知识。
第一、处理数据,建立数据挖掘模型的能力,称之为“技术能力”;
第二、在所有的数据中,哪些可以展示出有价值的信息,这就需要结合业务,只有结合业务,才能发现有价值的东西。第一个好学,也是大部分人眼中的数据挖掘;第二个才是难点,学生的话,接触的业务不多,可能体会不深刻,这个只能在生活中,多想想如果有什么数据、可以得到什么有价值的东西,训练自己的这方面的思维能力。
关于技术与业务能力,这个回答很不错,可以参考:http://www.flybi.net/question/14511
数据挖掘分成两个方面,一是数据挖掘技术的掌握,在学校教的比较多的也是这个方面,另一个是数据挖掘的应用,这个方面主要是结合业务,发现数据的价值,只有能够有效的利用好数据,才能成为一个合格的数据挖掘方面的专家。
4. 数据挖掘专业编程能力要到什么水平才算及格?来自用户 SmartMining 的回答:
只要你能够熟练掌握一款数据挖掘工具,能够使用工具实现数据处理和挖掘算法,懂得挖掘的用途和价值,这就算及格了。但是要变得优秀就难了,学习数据挖掘真正的核心是帮助企业解决实际的业务问题。简单的讲,就是面对企业的痛点,你有解决的想法,然后使用工具实现你的想法或者验证你的想法。
补充:做数据挖掘不一定要会编程,这个并不是最重要的技能,核心技能是应用数据的能力。只要你能实现,不管是使用会编程的工具还是无需编程的工具还是两者混用都可以。
5. 如何理解 SPSS 方差分析中的残差图
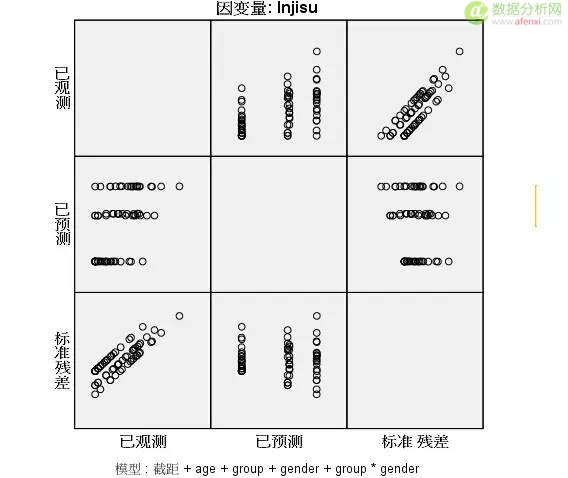
来自用户 卢育峰 的回答:
首先你要了解怎么看这个图,这个是残差图哦,要理解横轴纵轴的含义。
以第二行第一列来看,横坐标是已观测值,纵坐标是已预测值 很明显观测值与预测值是成分类展示。
以第三行第一列来看,横坐标是已观测值,纵坐标是标准差,残差分布规律太明显了。看起来像散点分布接近一条直线说明是满足齐方差性但并不一定,做好是做齐方差检验。
从上图来看,有几个原因可能导致这种情况:
1、缺少自变量,导致模型的解释变量被放在误差里面。
2、输入值未做处理,age、group、gender有可能需要做归一化。
3、是否模型过度拟合。
总的来说,你用的方法不对,或者缺少因子,多了解一下理论吧。
来自用户 卢育峰 的回答:
简单说一下,目前的算法都有各种应用,只是行业不同而已哦。
按照机器学习的分法,最常见的分类就是有监督学习、无监督学习、半监督学习、强化学习。
有监督学习主要有:逻辑回归(Logistic Regression)、BP神经网络(Back Propagation Neural Network)
半监督学习主要是分类和回归,有:推理算法(Graph Inference)、拉普拉斯支持向量机(Laplacian SVM)
强化学习有:Q-learning、时间差学习(Tempral difference learning)
如果按照数据挖掘来分:
分类与回归:决策树、贝叶斯、人工神经网络、K-近邻、支持向量机、逻辑回归等。
关联:Apriori、FP-树频集等
聚类:k-means、k-medoids等
简单就这么看看吧,功能这一块不好说,不同算法的应用真的不一样,回头我整理一下写到博客里面。
7. 数据挖掘 分类 和 回归 是不是一回事?哪一部分 机器学习和神经网络应用的比较多? 拜求大神赐教来自用户 Philbert 的回答:
楼主这个问题涉及的方面比较多,我简单说两句,供参考:
1 分类和回归本质上都是通过对已有数据的训练结果形成决策知识为预测型的应用目标服务的。
2 回归往往面对的是连续型数据的趋势预测,比如企业根据历史销售数据预测下一个月的销售额,这种情况下训练出的决策知识往往以一个函数的形式来存在。
3 分类往往面对的是离散性数据的预测分析,比如企业同样根据历史销售数据预测下一个月的销售额是上升?持平?下降?,这种情况下训练出的决策知识往往以一些规则的集合形式存在,我们常称之为模型。
4 机器学习和神经网络的应用方面这个问题比较大,因为任何行业都可能出现合适这两种技术的应用方向,主要在于面向的数据类型和应用目标是不是适合这两种技术 的分析方式,只要适合就可以去使用它们,而且建议不要把它们分割开来看,很多应用目标的达成是综合使用它们的结果,很火的阿尔法狗!就是目前综合使用他们的最典型的案例。
来自用户 SmartMining 的回答:
两者区别主要在于建设成本和安全性上。
私有云更安全,因为建设在企业内部的局域网内,不会把数据放到别人的平台上,企业自己更可控更安全。但是相对建设成本比公有云高一些。但是毕竟数据的安全更重要。而使用公有云的话,需要把数据放到别人的公有云平台上,自然不安全。因此,选择公有云还是私有云,关键点就在于您对数据安全性的重视程度以及数据的重要性。
如果您公司的数据量不大,单一机器就可以搞定,这样不需要考虑使用公有云;
如果数据量比较大,但是不重要,比如都是从互联网采集的数据,这样的话可以使用公有云;
如果您的数据量比较大,且比较重要。暂且建议使用私有云的解决方案。
来自用户 Philbert 的回答:
个人感觉这个问题的需要明确几个细节才能考虑如何实现:
1 你说的自动化变量筛选是指建模前的数据预处理过程?
2 一般情况下这种类型的建模要涉及训练,评估,应用三个方面的工作,你说的自动化过程是指哪个方面?
3 一般确定一个风险预测模型后确实需要根据应用的实际效果不断对该模型进行调整,但这个调整周期都是需要一定时间和新的应用数据积累的,每日的地自动化如果是指模型调整而言好像不是很合适。
4 建议明确该风险模型的应用场景和目标,不同的应用场景和目标对于训练出的模型准确度的具体要求是不同的,进而也会影响模型的评估标准。
来自用户 SmartMining 的回答:
其实,可以简单的理解,多维分析是数据的多维度视图,是数据的一种探索分析手段,和图形化可视化探索数据异曲同工,你可以把多维分析作为数据挖掘可视化探索的一部分。
数据挖掘除了也可以使用图形或多维表做数据探索分析外,核心是通过一些手段(算法)总结数据中的规律,这是对潜在规律的量化实现(规则、数学公式等),如您可以根据历史的销售信息建立预测模型,得到数学公式后,只要输入影响因素的值就可以预测销量,这一类属于分类预测问题,还可以使用用户的信息对用户进行分群,把相似的人归为一类,把不相似的人归到不同的类中,这是使用聚类模型量化用户相似性的问题,又比如,可以使用时间序列算法预测未来每个月的用户增量、客运量等。您可以发现,这些都是一种推断,基于历史的数据推断出来的结果,并不是完全真实的事情,只是在推断未来会这样发生发展。
而多维分析是为了更好的展示历史数据,而没有这种基于历史数据的推断和预测能力。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
CDA持证人简介 刘伟,美国 NAU 大学计算机信息技术硕士, CDA数据分析师三级持证人,现任职于江苏宝应农商银行数据治理岗。 学 ...
2025-04-21持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28






