从大数据到小数据,数据之坑与美
美国著名科技历史学家梅尔文?克兰兹伯格(Melvin Kranzberg),曾提出过大名鼎鼎的科技六定律,其中第三条定律是这样的[1]:“技术是总是配“套”而来的,但这个“套”有大有小(Technology comes in packages, big and small)”。
这个定律用在当下,是非常应景的。因为,我们正步入一个“大数据(big data)”时代,但对于以往的“小数据(small data)”,我们能做到“事了拂衣去,深藏身与名”吗?答案显然不是。目前,大数据的前途似乎“星光灿烂”,但小数据的价值依然“风采无限”。克兰兹伯格的第三定律是告诉我们,新技术和老技术的自我革新演变,是交织在一起的。大数据和小数据,他们“配套而来”,共同勾画数据技术(Data Technology,DT)时代的未来。
对大数据的“溢美之词”,已被舍恩伯格教授、涂子沛先生等先行者及其追随者夸得泛滥成灾。但正如您所知,任何事情都有两面性。在众人都赞大数据很好的时候,我们也需说道说道大数据可能面临的陷阱,只是为了让大数据能走得更稳。在大数据的光晕下,当渐行渐远渐无小数据时,我们也聊聊小数据之美,为的是“大小并行,不可偏废”。大有大的好,小有小的妙,如同一桌菜,哪道才是你的爱?思量三番再下筷。
下文部分就是供读者“思量”的材料,主要分为4个部分:(1)哪个V才是大数据最重要的特征?在这一部分里,我们聊聊大数据的4V特征中,哪个V才是大数据最贴切的特征,这是整个文章的行文基础。(2)大数据的力量与陷阱。在这一部分,我们聊聊大数据整体的力量之美及可能面临的3个陷阱。(3)今日王谢堂前燕,暂未飞入百姓家,在这一部分,我们要说明,大数据虽然很火,但我们用数据发声,用事实说话,大数据真的没有那么普及,小数据目前还是主流。(4)你若安好,便是晴天。在这一部分,我们说说的小数据之美,如果用“n=all”来代表大数据,那么就可以用“n=me”来说明小数据(这里n表示数据大小),我们将会看到,小数据更是关系到我们的切身利益。
1.哪个V才是大数据最重要的特征?
在谈及大数据时,人们通常用4V来描述其特征,即4个以V为首字母的英文:Volume(大量)、Variety(多样)、Velocity(速快)及Value(价值)。如果 “闲来无事”,我们非要对这4个V在“兵器谱”上排排名,哪个才是大数据的贴切的特征呢?下面我们简要地说道说道,力图说出点新意,分析的结果或许会出乎您的意料之外。
1.1 “大”有不同——Volume(大量)
首先我们来说说大数据的第一个V——Volume(大量)。虽然数据规模巨大且持续保持高速增长,通常作为大数据的第一个特征。但事实上,早在20年前,在当时的IT环境下,天文、气象、高能物理、基因工程等领域的科研数据量,已是这些领域无法承受的“体积”之痛,当时实时计算的难度不比现在小,因为那时的存储计算能力差,亦没有成熟的云计算架构和充分的计算资源。
况且,“大”本身就是一个相对的概念,数据的大与小,通常都打着很强的时代烙印。为了说明这个观点,让我们先回顾一下比尔?盖茨的经典“错误”预测。

图1 比尔·盖茨于1981年对内存大小的预测
早在1981年,作为当时的IT精英,比尔?盖茨曾预测说,“640KB的内存对每个人都应该足够了(640KB ought to be enough for anybody)”。但30多年后的今天,很多人都会笑话盖茨,这么聪明的人,怎么会预测地如此不靠谱,现在随便一个智能手机(或笔记本电脑)的内存的大小都是4GB、8GB的。
但是,需要注意的事实是,在1981年,当时的个人计算机(PC)是基于英特尔CPU 8088芯片的,这种CPU是基于8/16位(bit)混合构架的处理器,因此,640KB已经是这类CPU所能支持的寻址空间的理论极限(64KB)的10倍[2],换句话说,640K在当时是非常非常地庞大了!再回到现在,当前PC机的CPU基本都是64bit的,其理论支持的寻址空间是2^64,而现在的4G内存,仅仅是理论极限的(2^32)/(2^64)= 1/(2^32)而已!。
在这里,讲这个小故事的原因在于,衡量数据大小,不能脱离时代背景,不能脱离行业特征。此外,大数据布道者舍恩伯格教授在其著作《大数据时代》中指出[3],大数据在某种程度上,可理解为“全数据(即n=all)”。有时,一个所谓的“全”数据库,并不需要有以TB/PB计的数据。在有些案例中,某个“全”数据库大小,可能还不如一张普通的仅有几个兆字节(MB)数码照片大,但相对于以前的“部分”数据,这个只有几个兆字节(MB)大小的“全”数据,就是大数据。故此,大数据之“大”,取义为相对意义,而非绝对意义。
这样看来,互联网巨头的PB级数据,可算是大数据,几个MB的全数据也可算是大数据,如此一来, 大数据之“大”——“大”有不同,可大可小,如此不“靠谱”,反而不能算作大数据最贴切的特征。
1.2 数据共征——“Velocity(快速)”与“Value(价值)”
英特尔中国研究院院长吴甘沙先生曾指出,大数据的特征“Velocity(快速)”,犹如“天下武功,唯快不破”一样,要讲究个“快”字。为什么要“快”?因为时间就是金钱。如果说价值是分子,那么时间就是分母,分母越小,单位价值就越大。面临同样大的数据“矿山”,“挖矿”效率是竞争优势。
不过,青年学者周涛教授却认为[4],1秒钟算出来根本就不是大数据的特征,因为“算得越快越好”,人类自打有计算这件事情以来,这个诉求就没有变化过,而现在,却把它作为一个新时代的主要特征,完全是无稽之谈。 笔者也更倾向于这个说法,把一个计算上的“通识”要求,算作一个新生事物的特征,确实欠妥。
类似不妥的还有大数据的另外一个特征——Value(价值)。事实上,“数据即价值”的价值观古来有之。例如,在《孙子兵法?始计篇》中,早就有这样的论断“多算胜,少算不胜,而况于无算乎?”此处 “算”,乃算筹也,也就是计数用的筹码,它讲得就是,如何利用数字,来估计各种因素,从而做出决策。
在马陵之战中,孙膑通过编造“齐军入魏地为十万灶,明日为五万灶,又明日为三万灶(史记·孙子吴起列传)”的数据,利用庞涓的数据分析习惯,反其道而用之,对庞涓实施诱杀。
话说还有一个关于林彪将军的段子(真假不可考),在辽沈战役中,林大将军通过分析缴获的短枪与长枪比例、缴获和击毁小车与大车比例,以及俘虏和击毙的军官与士兵的比例“异常”,因此得出结论,敌人的指挥所就在附近!果不其然,通过追击从胡家窝棚逃走的那部分敌人,活捉国民党主帅新六军军长廖耀湘。
在战场上,数据的价值——就是辅助决策来获胜。还有一点值得注意的是,在上面的案例中,战场上的数据,神机妙算的军师们,都能“掐指一算”——这显然属于十足的小数据!但网上却流传有很多诸如“林彪也玩大数据”、“跟着林彪学习大数据”等类似的文章,这就纯属扯淡了。如果凡是有点数据分析思维的案例,都归属于大数据的话,那大数据的案例,古往今来,可真是数不胜数了。
因此,Value(价值)实在不能算是大数据专享的特征,“小数据”也是有价值的。在下文第4节的分析中,我们可以看到,小数据对个人而言,“价值”更是不容小觑。这样一来,如果大、小数据都有价值,何以“价值”成为大数据的特征呢? 事实上,睿智的IBM,在对大数据的特征概括中,压根就没有“Value”这个V(如图2所示)。
图2 IBM公司给出的大数据3V特征(图片来源:disquscdn.com)
我们知道,所谓“特征”者,乃事物异于它物之特点”。打个比方,如果我们说“有鼻子有眼是男人的特征”,您可能就会觉得不妥:“难道女人就没有鼻子没有眼睛吗?”是的,“有鼻子有眼”是男人和女人的“共征”,而非“特征”。同样的道理,Velocity 和Value这两个V字头词汇,是大、小数据都能有的“共征”, 实在也不算不上是大数据最贴切的特征。
1.3五彩缤“纷”——Variety(多样)
通常认为,大数据的多样性(Variety),是指数据种类多样。其最简单的种类划分,莫过于分为两大类:结构化的数据和非结构化数据,现在“非结构化数据”占到整个数据比例的70%~80%。早期的非结构化数据,在企业数据的语境里,可以包括诸如电子邮件、文档、健康、医疗记录等非结构化文本。随着互联网和物联网(Internet of things,IoT)的快速发展,现在的非结构化数据又扩展到诸如网页、社交媒体、音频、视频、图片、感知数据等,这诠释了数据的形式多样性。
但倘若深究下去,就会发现,“非结构化”未必是个成立的概念。在信息中,“结构化”是永存的。而所谓的“非结构化”,不过是某些结构尚未被人清晰的描述出来而已。IT咨询公司Alta Plana的高级数据分析师Seth Grimes曾在IT领域著名刊物《信息周刊》(Information Week)撰文指出:不存在所谓的非结构化,现在所说的“非结构化”,应该是非模型化(unmodeled),结构本在,只是人们处理数据的功力未到,未建模而已(Most unstructured data is merely unmodeled)[5](如图3所示)。
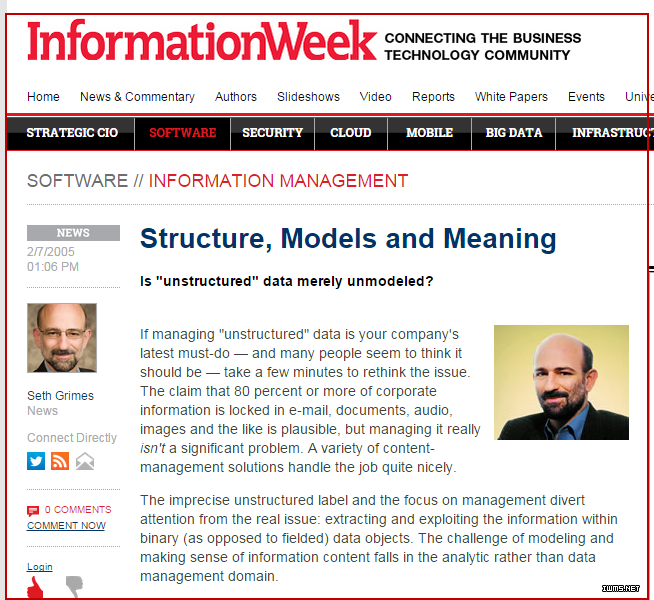
图3 Seth Grimes:非结构化乎,不!应是非建模
大数据的多样性(Variety),还体现在数据质量的参差不齐上。换句话说,这个语境下的多样性就是混杂性(Messy),即数据里混有杂质(或称噪音)。大数据的混杂性,基本上是不可避免的,既可能是数据产生者在产生数据过程出现了问题,也可能是采集或存储过程存在问题。如果这些数据噪音是偶然的,那么在大数据中,它一定会被更多的正确数据淹没掉,这样就使得大数据具备一定的容错性;如果噪音存在规律性,那么在具备足够多的数据后,就有机会发现这个规律,从而可有规律的“清洗数据”,把噪音过滤掉。吴甘沙先生认为[15],多元抑制的数据,能够过滤噪声、去伪存真,即为辩讹。更多有关混杂性的精彩描述,读者还可批判性地参阅舍恩伯格教授的大著《大数据时代》[3]。
事实上,大数据的多样性(Variety),最重要的一面,还是表现在数据的来源多和用途多上。每一种数据来源,都有其一定的片面性和局限性,只有融合、集成多方面的数据,才能反映事物的全貌。事物的本质和规律隐藏在各种原始数据的相互关联之中。对同一个问题,不同的数据能提供互补信息,可对问题有更为深入的理解。因此在大数据分析中,汇集尽量多种来源的数据是关键。中国工程院李国杰院士认为[6],这非常类似于钱学森老先生提出的“大成智慧学”,“必集大成,才能得智慧”。
著名历史学家许倬云先生,站在历史的高度,也给出了自己的观点,他说“大数据”之所以能称之为“大数据”,就在于,其将各种分散的数据,彼此联系,由点而线,由线而面,由面而层次,以瞻见更完整的覆盖面,也更清楚地理解事物的本质和未来取向。
英国数学家及人类学家托马斯·克伦普(Thomas Crump)在其著作《数字人类学》(The Anthropology of Numbers)指出[7],数据的本质是人,分析数据就是在分析人类族群自身,数据背后一定要还原为人。东南大学知名哲学教授吕乃基先生认为[8],虽然每个数据来源因其单项而显得模糊,然而由“无限的模糊”所带来的聚焦成像,会比“有限的精确”更准确。“人是社会关系的总和(马克思语)”。大数据利用自己的“多样性”,比以往任何时候都趋于揭示这样的“总和”。
因此,李国杰院士认为[6],数据的开放共享,提供了多种来源的数据融合机会,它不是锦上添花的事,而是决定大数据成败的必要前提。
从上分析可见,虽然大数据有很多特征(甚至有人整出11个V来),但大数据的多样性(Variety),无疑它是区分以往小数据的最重要特征。
2. 大数据的力量与陷阱
大数据的多样性,给大数据分析带来了庞大的力量,但这个多样性也带来了大数据的陷阱,下面我们就聊聊这个话题。
2.1 大数据的力量
很多小概率、大影响的事件(即黑天鹅事件),在单一的小数据环境下,很可能难以发现。但是由“八方来客”汇集而来的大数据,却能有机会提供更为深刻的洞察(insight)。例如,癌症属于一类长尾病症,经过多少年努力,癌症治愈率仅提升了不到8%。其中一个重要原因是,单个癌症的诊疗机构的癌症基因组样本都相对有限。“小样本”得出的研究结论,得出有关“癌症诊断”的结论,极有可能是“盲人摸象化”的[9]。
于是,英特尔公司提出的“数据咖啡馆”概念,吴甘沙先生做了一个形象的类比,他说咖啡馆的好处在于“Let ideas have sex”,而大数据产生价值、爆发力量的关键是“Let data have sex”。取意如此,数据咖啡馆”的核心理念在于,把不同医疗机构的癌症诊疗数据汇聚到一起,形成大数据集合,但不同机构间的数据,“相逢但不相识”。让多源头的“小数据”汇集起来,可实现数据之间“1+1>2”的价值。对多数据融合用“have sex”这个比喻,是非常有意思的,因为倘若你真想要达到“1+1> 2”的效果,就不能带着“套子”挡着,就要打破“数据流的割据”。难怪李院士一直强调,数据的流通性,是决定大数据成败的前提,还是真的(纯属调侃,不可较真)!
类似的,2014年美国总统办公室发布了题为“大数据:抓住机遇,留住价值(Big Data:Seizing Opportunities, Preserving Values)”的报告[10],文中列举了一个案例:
Broad 研究院(这是一个由麻省理工学院和哈佛大学联合创办的世界著名的基因研究机构)的研究人员发现,海量的基因数据,在识别遗传变异对疾病的意义中,有着及其重要的作用。在这个研究中,当样本数量是 3,500 时,与精神分裂症有关的遗传变异,根本无法检测出来;当使用 10,000 个样本时,也只能有细微的识别;但是当样本达到 35,000 时,统计学上的统计显著性(statistically significant)便突然显示出来。正如一个研究人员所观察到的那样,“跨越拐点,一切皆变!(There is aninflection point at which everything changes)”[11](如图4所示)。从这个案例中,大数据把哲学中的“量变引发质变”演绎得淋漓尽致。
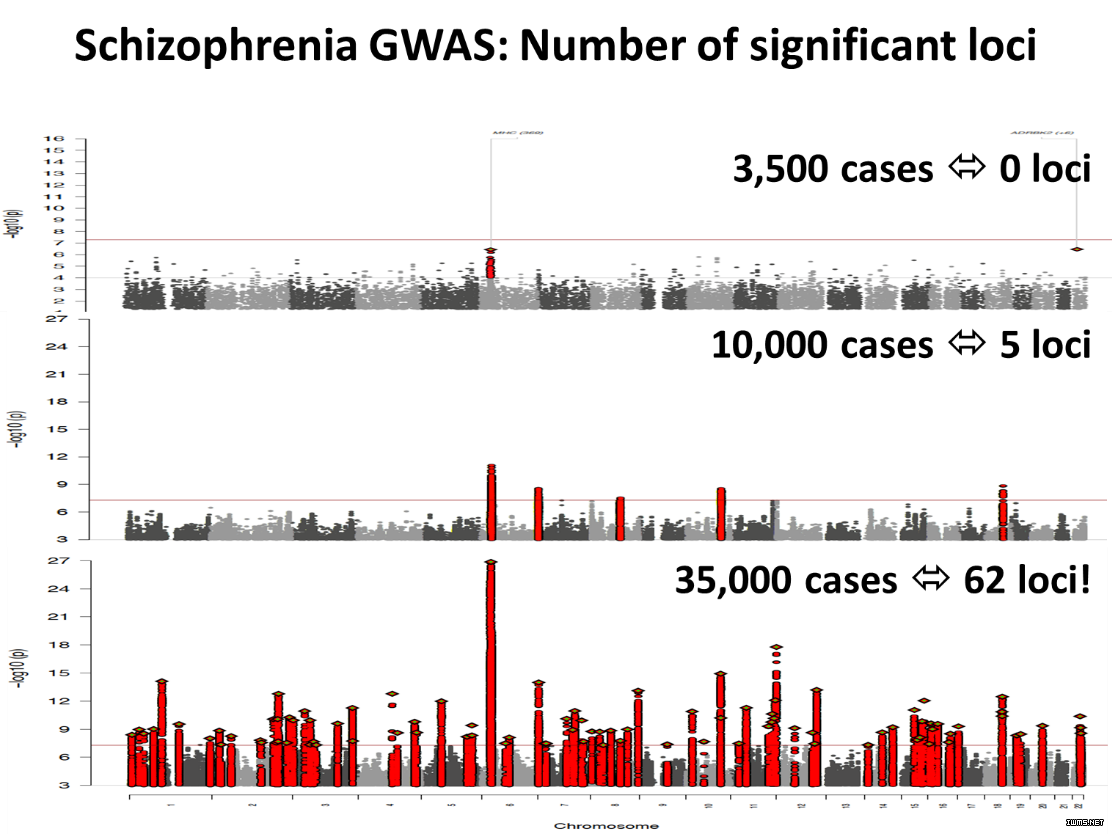
图4 精神分裂症有关的遗传变异发现——大数据的“汇集”的力量(图中loci表示“基因座”,又称座位,它基因在染色体上所占的位置。在分子水平上,是有遗传效应的DNA序列。图片来源:MIT)
2.2 大数据的陷阱
大数据的多样性,带人们来了“兼听则明”的智慧。然而,正如英谚所云:“一个硬币有两面(Every coin has two sides)”, 这个多样性也会带来一些不宜察觉的“陷阱”。用“成也萧何,败也萧何”来描述大数据的两难,再恰当不过了。
2.2.1 DIKW金字塔体系
1989年,管理学家罗素·艾可夫(Russell .L. Ackoff)撰写了《从数据到智慧》(From Data to Wisdom),系统地构建了DIKW体系[12],即从低到高依次为数据(Data)、信息(Information)、知识(Knowledge)及智慧(Wisdom)。美国学者泽莱尼(Zeleny)提出了4个Know(知道)比喻[12],比较形象地区分了DIKW体系中的元素,如图5所示。
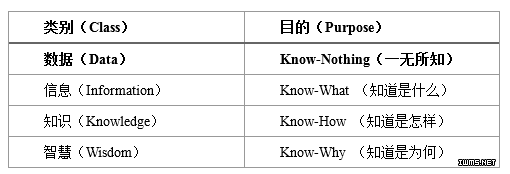
图5 泽莱尼对DIKW体系中的4个Know比拟
泽莱尼对DIKW体系的注解,让人感触最深的可能在于,数据如果不实施进一步地处理,即使收集数据的容量再“大”,也毫无价值,因为仅仅就数据本身,它们是“一无所知(Know-Nothing)”的。数据最大的价值,在于形成信息,变成知识,乃至升华为智慧。
舍恩伯格教授在其大作《大数据时代》有个核心观点是:“要相关,不要因果”,即知道“是什么”就够了,没必要知道“为什么”。但从DIKW体系可知,如果放弃“为什么”的追寻,事实上,就放弃了对金字塔的最顶端——智慧(Wisdom)的追求——而智慧正是人类和机器最本质的区别。
对此,青年学者周涛教授总结得非常精彩:“放弃对因果性的追求,就是放弃了人类凌驾于计算机之上的智力优势,是人类自身的放纵和堕落。如果未来某一天机器和计算完全接管了这个世界,那么这种放弃就是末日之始”。对大数据的因果性和相关性的探讨,我们已经在《来自大数据的反思:需要你读懂的10个小故事》一文中[14],已有涉及,在此不再赘言,下面我们想探讨的是,事实上,对因果关系的追寻,是人类惯有的思维,在这个惯性思维推动下,很容易误把“相关”当“因果”——这是我们需要警惕的大数据陷阱。
2.2.2 误把“相关”当“因果”
所谓“相关性”是指两个或两个以上变量的取值之间存在某种规律性。两个变量A和B有相关性,只反映A和B在取值时相互有影响,但并不能说明因为,有A就一定有B,或者反过来因为有B就一定有A。
在上面的论述中,似乎我们一直在说“相关性”的不足。而事实上,需要说明的是,相关性在很多场合是极其有用的。例如,在大批量的小决策上,相关性就是有用的,亚马逊的电子商务个性化推荐,就是利用相关性,给无数顾客推荐相关的或类似商品,这样顾客找起商品方便多了,亚马逊也落得个赚得钵满盆满。
然而,对于小批量的大决策,对因果关系的追求,依然是非常重要的。吴甘沙先生用“中西药”药方做类比,给出了一个很精彩的例子,用来说明相关性和因果性的关系[15]。对于中药处方而言,多是“神农尝百草”式的经验处方,目前仅仅到达知道“相关性”这一步,但它没有可解释性,无法得出是那些树皮和虫壳的因,为什么就是导致某些病能治愈的果,换句话说,中药仅仅到了“知其然”阶段(追求“是什么”),如果我们的国粹止步于“知其所以然”(追求“为什么”),那么中医想要走出中国,面向世界,是非常困难的(注:笔者曾是中医的受益者,请不要误判是在黑中医)。
而西药则不同,在发现相关性后,并没有止步,而是进一步要做随机对照试验,把所有可能导致“治愈的果”的干扰因素排除,获得因果性和可解释性。在商业决策上也是类似,相关性只是决策的开始,它取代了拍脑袋、依靠直觉获得的假设,而后面验证因果性的过程仍然是重要。
在大数据时代,“相关性”被很多大数据粉丝奉为圭臬。前文也提到,“相关性”也的确有用,但有时,人们会不自觉地把“相关性”不自觉地当作“因果性”。
加拿大莱桥大学管理学院鲍勇剑教授指出[16],在大数据时代,只要有超大样本和超多变量,我们都可能找到无厘头式的相关性。美国政府每年公布4.5万类经济数据。如果你要找失业率和利率受什么变量影响,你可以罗列10亿个假设。只要你反复尝试不同的模型,上千次后,你一定可以找到统计学意义上成立的相关性。下面我们讲几个小故事(段子)来说明这个观点。
在小数据时代的1992年,香港人拍了一个电视连续剧《大时代》,其中著名演员郑少秋饰演丁蟹,丁蟹是一个资深的股民,股海翻腾,身心疲惫,终无所得。在1992年的随后20多年里,只要电视台一播放郑少秋主演的连续剧,香港恒生指数都会有不同程度的下跌,人称“丁蟹效应(或称秋官效应)”,这是有样本支持的,如图6所示。每次郑少秋主演的电视剧播放预告时,总有香港股民打电话到电视台,希望不要播放,因为担心亏钱。
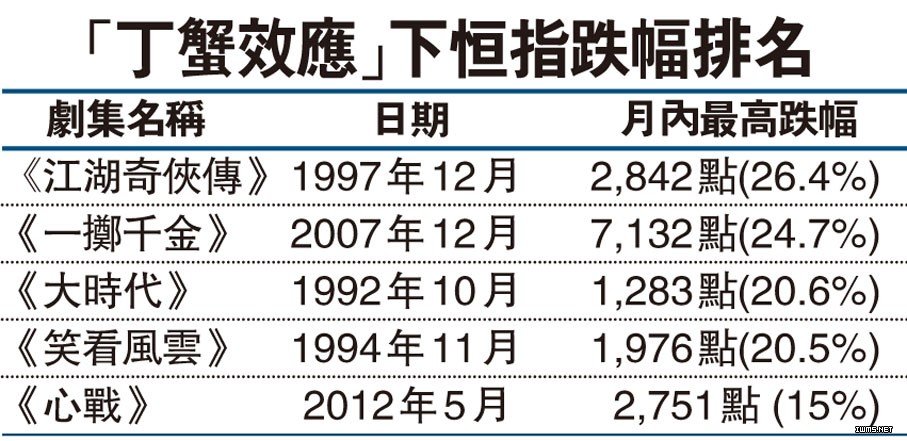
图6 丁蟹效应与香港股市(图片来源:文汇报)
更无厘头的是,这相关性还扯到中国运动员刘翔身上了,下面是个“余温尚存”段子,它是这样描述的:
2008年8月18日 北京奥运会,刘翔因伤退赛,当天股市大跌5.3%,并且一个月内大跌20%。
2014年9月他宣布结婚一个月后,股市就开始狂涨,从2300点涨到5178点。
2015年6月26日,刘翔离婚,股市继续大跌至8%。股市的涨跌原来都是因为刘翔啊!
因此,网友们强烈要求刘翔尽快宣布再次结婚。
香港的股民为什么不希望郑少秋主演的电视剧播放,是因为怕电视剧一播放,股市就下跌。大陆的股民为什么希望刘翔再次结婚,因为刘翔有喜了,所以股市就有喜了。注意到前面描述中体现出来的“因果关系”吗?
事实上,《大时代》和刘翔和股市之间有何因果关系?不过是样本大了,变量多了,统计上的“相关性”就会冒出来而已。而人们却“潜移默化”地把观察到的“相关”,当作事物背后的“因果”。
或许,就有人不太认可上述观点,认为上面两个小故事,都是属于段子级别的案例,何以能说明问题?那我们就举一个古而有之的案例来说明这个观点。请读者略看下面的文字:
黄梅时节家家雨,青草池塘处处蛙。
潮起潮落劲风舞,夏夜夏雨听蛙鸣。
荷沐夏雨娇滴滴,稻里蛙鸣一片欢。
夏雨凉风,蝉噪蛙鸣,热浪来袭,远处云树晚苍苍。
皇阿玛,你还记得当年蛙鸣湖边的夏雨荷吗?
我们知道,文学虽然高于生活,但亦源于生活。从上面的从古至今的“文人墨客”的诗情画意中,读者依稀可看出一点点相关性——人类祖先经过长期观察发现,蛙鸣与下雨往往是同时发生。这样的长期观察样本,也可称得上是“大数据”。于是,在久旱无雨的季节,不求甚解的古人,就会把这个“相关性”当作“因果性”了,他们试图通过学蛙鸣来求雨。在多次失灵之后,就会走向巫术、献祭和宗教[8](如图7所示)。因此,同小数据一样,在大数据中,可解释性(因果关系)始终是重要的。

图7 印度人民以蛙求雨的习俗,源远流长,至今留存(图片来源:互联网)
博弈论创始人之一、天才计算机科学家诺伊曼(John von Neumann)曾戏言称:“如果有四个变量,我能画头大象,如果再给一个,我让大象的鼻子竖起来!”大数据的来源多样性,变量复杂性,为诞生 “新颖”的相关性,创造无限可能。而本质上,人们对因果关系的追求,事实上,已经根深蒂固,这种思维惯性难以轻易改变,而在大数据时代,会面临着冒出更多的相关性,“乱花渐欲迷人眼”。大数据的拥趸者们说,“要相关,不要因果”,但事实上,在很多时候,特别是人们在对未来无法把控的时候,很容易把“相关”当作“因果”!这是大数据时代里一个很大的陷阱,特别值得注意。
[page]
2.2.3 大数据的其它陷阱
下面,我们用另外一个小“故事”来说明大数据的第二个陷阱:
假如你是一位出车千次无事故的好司机,年关将近,酒趣盎然,在朋友家喝了点小酒,这时估计警察也该下班过年了,于是你坚持自己开车回家,盘算着这酒后驾车出事故的概率也不过千分之一吧。如果这样算,你就犯了一个取样错误,因为前一千次出车,你没喝酒,它们不能和这次“酒后驾车”混在一起计算(故事来源:参考文献[16])。
这是大数据分析中的第二个容易跳入的陷阱。大数据的多样性里,包括了数据质量上的“混杂性”,某些低频但很重要的弱信号,很容易被当作噪音过滤掉了!从而痛失发现“黑天鹅”事件的可能性。
再例如,在美国,学习飞机驾驶是件“司空见惯”的事,在几十万学习飞机驾驶的记录中,如果美国有关当局能注意到,有那么几位学员只学习“飞机起飞”,而不学习“飞机降落”,那么9/11事件或许就可以避免,世界的格局可能就此发生根本性的变化(当然,这个事件也为中国赢得了10年的黄金发展期,不在本文的讨论范围,就不展开说)。在大数据时代的分析中,很容易放弃对精确的追求,而允许对混杂数据的接纳,但过多的“混杂放纵”,就会形成一个自设的陷阱。因此,必需“未雨绸缪”,有所提防。
在大数据时代里,第三个值得注意的陷阱是,大数据的拥趸者认为,大数据可以做到“n=all”(这里n数据的大小),因此无需采样,这样做也就不会再有采样偏差的问题,因为采样已经包含了所有数据。但事实上,“n=all”很难做到,统计学家们花了200多年,总结出认知数据过程中的种种陷阱(如统计偏差等),这些陷阱不会随着数据量的增大而自动填平。
3.今日王谢堂前燕,暂未飞入百姓家——大数据没那么普及!
目前,虽然大数据被炒得火热,甚至连股票交易大厅的大爷大妈都可以聊上几句“大数据”概念股,但是大数据真的有那么普及吗?
事实上,倘若想要充分利用大数据,至少要具备3个条件:(1)拥有大数据本身;(2)具备大数据思维;(3)配备大数据技术。这三个高门槛,事实上,已经把很多公司企业拒之门外,套用刘禹锡那句诗:今日王谢堂前燕,不入寻常百姓家——大数据依然还是那么高大上,远远没有那么普及!
图8所示的是,著名IT咨询公司高德纳(Gartner)于2014年公布的技术成熟度曲线(hype cycle)。国内将“hype cycle”翻译成“成熟度曲线”,实在是太过文雅了,直译为“炒作周期”也毫不为过。从图8可以看出,大数据已经过了炒作的高峰期,目前处于泡沫化的底谷期 (Trough of Disillusionment)。
在历经前面的科技诞生促动期 (Technology Trigger)和过高期望峰值期(Peak of Inflated Expectations)这两个阶段,泡沫化的底谷期存活下来的科技(如大数据),需要经过多方历练,技术的助推者,要么咬牙坚持创新,要么无奈淘汰出局,能成功存活下来的技术及经营模式,将会更加务实地茁壮成长。
李国杰院士在接受《湖北日报》的采访时,也表达了类似的观点,“大数据刚刚过了炒作的高峰期”[17]。冷静下来的大数据,或许可以走得更远。

图8 高德纳技术成熟度曲线(图片来源:Gartner)
李国杰院士还表示,大数据与其他信息技术一样,在一段时间内遵循指数发展规律。指数规律发展的特点是,在一段时期衡量内(至少30年),前期发展慢,经过相当长时间(可能需要20年以上)的积累,会出现一个拐点,过了拐点以后,就会出现爆炸式的增长。但任何技术都不会永远保持“指数性”增长,最后的结局,要么进入良性发展的稳定状态,要么走向消亡。
大数据的布道者们,张口闭口言称大数据进入PB时代了。例如,《连线》杂志的前主编克里斯·安德森早在2008年说:“在PB时代,数量庞大的数据会使人们不再需要理论,甚至不再需要科学的方法。”但是这个吹捧也是非常不靠谱的,亦需要泼冷水还有大数据。
在大数据时代,我们要习惯让数据发声。下面的统计数据来自大名鼎鼎的学术期刊《科学》(Science)。2011年,《科学》调查发现[18],在“你科研过程中使用的(或产生的)最大数据集是多少?”的问卷调查中(如图9所示),48.3%的受访者认为他们日常处理的数据小于1GB,只有7.6%的受访者说他们日常用的数据大于1TB(1TB=1024GB,1PB=1024TB),也就是说,调查数据显示,92.4%用户所用的数据小于1TB,一个稍微大点的普通硬盘就能装载得下,这让那些动辄言称PB级别的大数据的布道者们情何以堪啊?而大数据重度鼓吹手IDC,目前正在为业界巨擘摇旗呐喊ZB时代(1ZB=1024PB),我们一定要冷眼看世界,慢慢等着瞧吧!
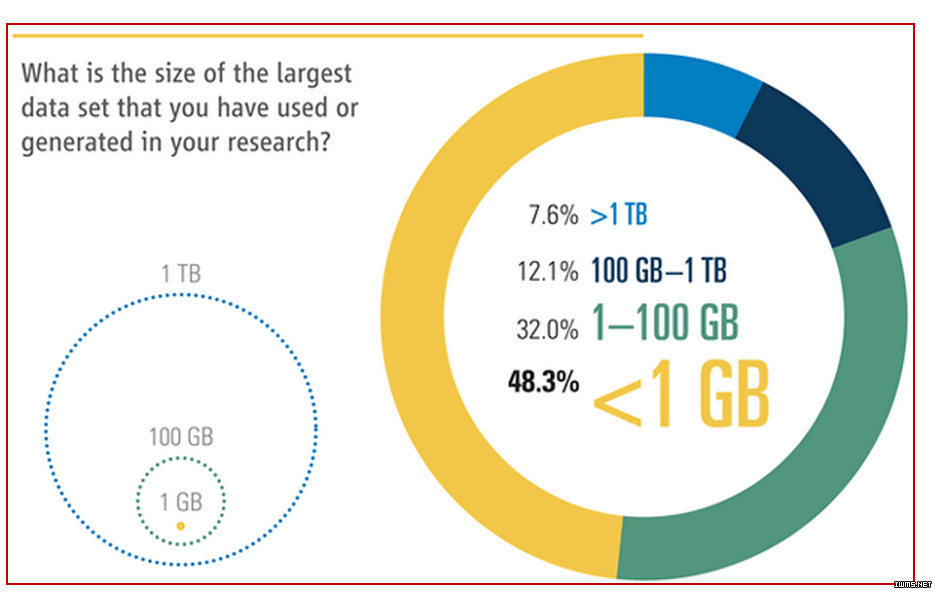
图9 在你的科研中,你使用的(或产生)最大数据集是多大?(图片来源:科学期刊)
而在“你在哪里存储实验室产生的数据或科研用的数据?”问卷调查中,50.2%的受访者回答是在自己的实验室电脑里存储,38.5%受访者回答是在大学的服务器上存储。由此可见,大部分的数据依然处于数据孤岛状态,在数据流通性的道路是,依然“路漫漫其修远兮”。而数据的流通性和共享性,如前文所述,是大数据成败的前提。
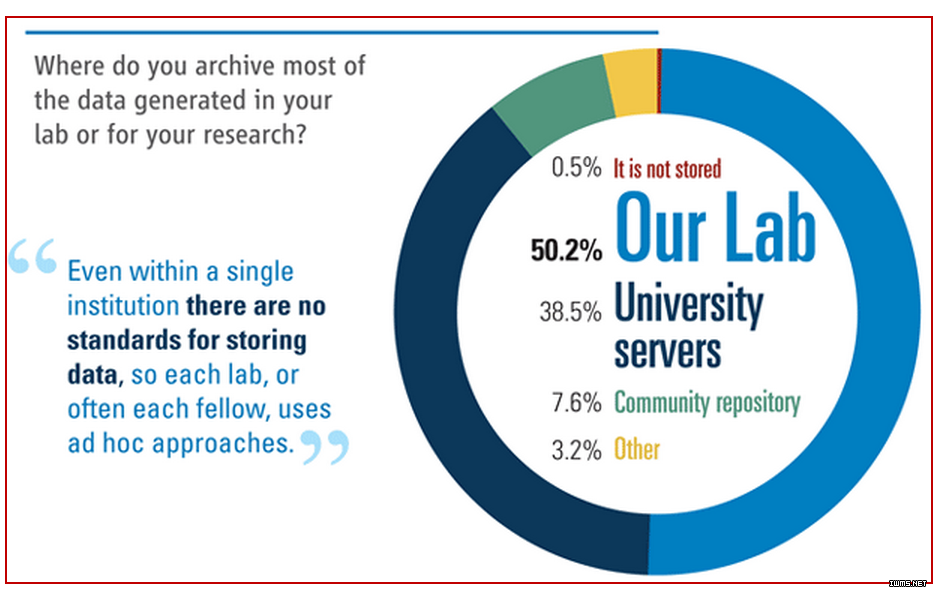
图10 你主要在哪里存储你实验产生的或科研数据?(图片来源:科学期刊)
或许也有读者不以为然,说我就是属于那部分小于7.6%的人(即使用或产生的数据大于1TB)。“我小众,我自豪”,此类信心满满的人,大多来自主流的互联网公司,如Google、Yahoo、微软、Facebook等,而在国内的自然非BAT莫属了。事实上,即使来自这类大公司的日常业务,其数据集也不是那么大的“触目惊心”。
微软研究院资深研究员Antony Rowstron等人撰文指出[19],根据微软和Yahoo的统计,所有Hadoop的作业放一起,取个中间值,其输入数据集的大小也不过是14GB。即使是在大数据大户Facebook,其90%的作业输入数据集,也是小于100GB的(clusters (at Microsoft and Yahoo) have median job input sizes under 14 GB, and 90% of jobs on a Facebook cluster have input sizes under 100 GB)。那些动辄拿某个互联网巨头的数据体积总和,来“忽悠”大家的大数据布道者们,更应该借给受众们“一双慧眼”,让他们“把这纷扰看得清清楚楚明明白白真真切切”。
当然,Antony Rowstron的这篇论文“意不在此”,文中的主要诉求是,既然我们日常处理的数据没有那么大到“不成体统”,就没有必要把某台机器的性能指标一味地纵向扩展(scale up),比如把内存从8G升级为16GB,32GB,64GB,甚至更高,而是应该选择更加“经济实惠”的横向扩展(Scale out)策略,比如将若干个8GB低配置的机器连接在一起,组成一个廉价的集群(cluster),然后利用Hadoop将集群用起来,所以这篇论文的标题是“没有人会因在集群上使用Hadoop而被解雇(Nobody ever got fired for using Hadoop on a cluster)”,言外之意,在目前大数据语境下,使用“类Hadoop(Hadoop-like)”工具分析大数据是未来主流的趋势之一,就业市场一片光明。
从上面的分析可以看出,我们不否认,大数据是前沿,但我们更不能对目前的现状熟视无睹——小数据依然是主流。目前大多数公司、企业其实仍处于“小数据”处理阶段。但只要在纵向上有一定的时间积累,在横向上有较丰富的记录细节,通过多个源头对同一个对象采集的各种数据有机整合,实施合理的数据分析,就可能产生大价值。基于此,李国杰院士指出,在大数据时代,我们是不能抛弃“小数据”的[9]。
对精确的追求,历来是传统的小数据分析的强项,这在一定程度上弥补大数据的“混杂性”缺陷。犹如有句歌词唱得那样:“结识新朋友,不忘老朋友”。在大数据时代,我们也不能忘记小数据。大数据有大数据的力量,小数据有小数据的美。下面我们就聊聊这个话题。
4.你若安好,便是晴天——小数据之美
小数据,其实是大数据的一个有趣侧面,是其众多维度的一维。有时,我们需要大数据的全维度可视,周涛教授甚至把“全息可见”作为大数据的特征,而这个特征在对用户数字“画像”时,非常有用,因为这样做,非常有利于商家推广“精准营销”。
在这里,我们再次强调托马斯·克伦普的哲学观——数据的本质是人。技术也是为人服务的。对于 “普罗大众”而言,有时,我们并不希望自己被数字化,被全息透明化,这就涉及到个人隐私问题了。如果大数据技术侵犯个人的隐私,让受众不开心了,那这个技术就应该有所限制和规范,但这不在本文的讨论范围,就不展开说了。
流行的“大数据”定义是:“无法通过目前主流软件工具在合理时间内采集、存储、处理的数据集”。我们很容易反其道而用之,定义出“小数据(small data)”, “通过目前主流软件工具可以在合理时间内采集、存储、处理的数据集”。这就是传统意义上的小数据,经典的数理统计和数据挖掘知识,可以较好地解决这类问题。这个范畴的小数据,属于老生常谈,所以本文不谈。
我们下文讨论的小数据,是一类新兴的数据,它是围绕个人为中心全方位的数据,是我们每个个体的数字化信息,因此,也有人称之为“iData”。这类小数据跟大数据的根本区别在于,小数据主要以单个人为研究对象,重点在于深度,对个人数据深入的精确的挖掘,对比而言,大数据则侧重在某个领域方面,在大范围、大规模全面数据收集处理分析, 侧重在于广度。
小数据是大数据的某个侧面,事实上,很多时候,对于个人而言,这个所谓的侧面就有可能是特定个人的全面。当大数据受万人瞩目时,创新技术(如智能手机、智能手环及智能体育等)也让小数据——个人的自我量化(Quantified Self,QS), “面朝大海,春暖花开”。
个人量化,可以测量、跟踪、分析我们日常生活中点点滴滴。比如,今天的早餐我摄入了多少卡路里?围着操场跑一圈我消耗了多少热量,在手机的某个App(如微信)上我耗费了多少时间?等等诸如此类。在某种程度上,是小数据,而非大数据,才是我们生活的帮手。“小数据”不比大数据那样浩瀚繁杂,却对我自己至关重要。下面我们用两个小案例来说明小数据的应用。
先说一个稍微高大上的案例。据科技记者Emily Waltz在IEEE Spectrum的撰文指出[20],目前佩戴在运动员身上生物小配件(Biometric gadget,通常指传感器),正在改变世界精英级运动员的训练方式。这些可穿戴传感器设备,提供实时的生理参数,而在以前,倘若要获取这样的数据,需要笨重和昂贵的实验室设备。如同40年前,风靡一时的负重训练方案,可让运动员更有韧性,可穿戴装备能帮助运动员提高成绩并同时避免受伤。一些棒球手、自行车运动员和橄榄球等竞技运动员用新装备寻求优势。
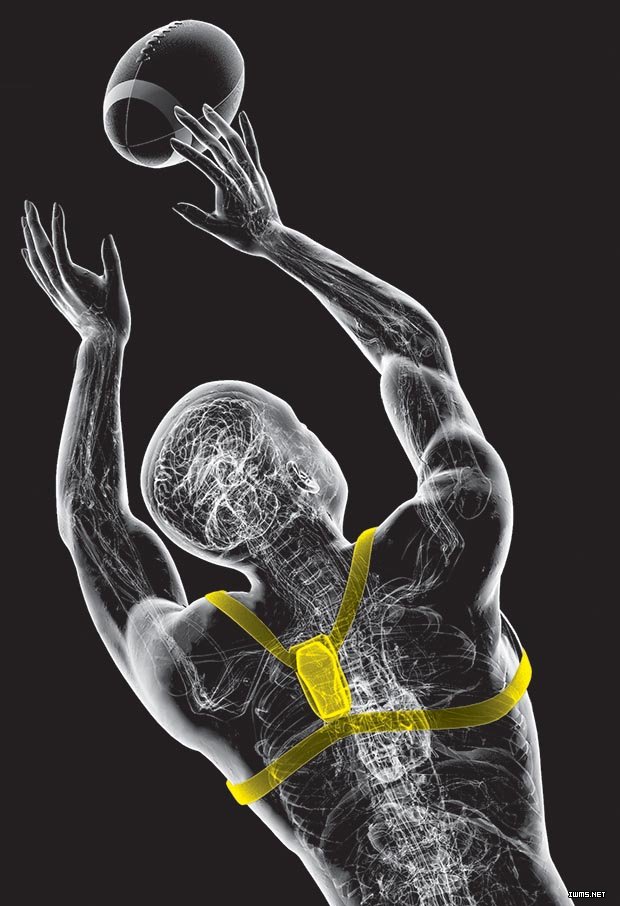
图11 运动员利用可穿戴设备训练美式橄榄球(图片来源:IEEE)
例如,在如图11所示的装备中,运动员身上的传感器能够精确记录在室内外场馆的运动特征。这些自我量化设备,可放置于运动员背部的压缩衣中,它能够监控运动员的加速、减速、方向改变以及跳跃高度和运动距离等指标。教练员能够通过监控数据,来检测每个运动员训练强度,并防止过度训练所带来的伤害。这些自我量化设备的工作原理是,协同使用很多小设备,如加速计、磁力计、陀螺仪、GPS接收仪等——这些设备每秒能够产生100个数据点。通过无线连接,计算机可以实时采集这些数据。个人量化分析软件,可对运动特征和特定位置实施分析,计算机专家系统中的算法,可以检测到运动员在做对了什么、做错了什么,基于此,教练可以给出更加有针对性的训练。目前此类设备的使用者,包括一半以上的NFL(橄榄球联盟)、三分之一的NBA运动员、一半以上的英超球队以及世界各地的足球队、橄榄球队和划船运动队等。
自我量化设备(可穿戴设备)通常是和物联网(Internet of things,IoT)是有关联的。而现在还处于炒作巅峰的物联网(如图8所示),通常是和大数据扯到一起的,但是就某个具体的物联网设备而言,它一定先是产生少量的甚至是微量的数据,也就是说,物联网首先是小数据,然后才能汇集成大数据。沃顿商学院教授、纽约时报最佳畅销书作者乔纳·伯杰(Jonah Berger)推测[21],个人的自我量化数据,或许将会是大数据革命中下一个演进方向。由此可见,大、小数据之间并无明显的界限。再大的数据也是人们一点一滴聚沙成塔、集腋成裘的。没有小数据的积少成多、百川归海,大数据也是无源之水、无本之木。
但如同中国那句老话说的,“一屋不扫,何以扫天下”,如果小数据都不能很好地处理,如何来很好地处理“汇集”而来的大数据?
说完高大上的案例,下面我们再聊聊一个“平淡无奇”生活小案例[22]:
故事的主人是美国康奈尔大学教授德波哈尔·艾斯汀(Deborah Estrin)。Estrin的父亲于2012年去世了,而早在父亲去世之前的几个月里,这位计算机科学教授就注意到一些“蛛丝马迹”, 相比从前,父亲在数字社会脉动(social pulse)中,已有些许变化——他不再查阅电子邮件,到附近散步的距离也越来越短,也不去超市买菜了。
然而,这种逐渐衰弱的迹象,在他去医院进行的常规心脏病(cardiologist)体检中,不一定能看出来。不管是测脉搏,还是查病历,这位90岁的老人都没有表现出特别明显的异常。可事实上,倘若追踪他每时每刻的个体化数据,这些数据虽小,但也足够刻画好出,老人的生活其实已然明显与之前不同。
这种日常自我量化的小数据,带来了生命讯息的警示和洞察,启发了这位计算机科学教授,促使Estrin在康奈尔大学创建创建了“小数据实验(the small data lab @CornellTech,访问链接:http://smalldata.io/)”。在Estrin看来,小数据可以看作是一种新的医学证据,它仅是“他们的数据中属于你的那一行(your row of their data)”[23] 。
舍恩伯格教授在其著作《大数据时代》中,将大数据定义为全数据(即n=All,n为数据的大小),其旨在收集和分析与某事物相关的“全部”数据。类似的, Estrin将小数据定义为:“small data where n=me”,它表示,小数据就是全部有关于我(me)的数据[24]。
如此一来,可以看出,小数据更加“以人为本”,它可以为我们提供更多研究的可能性:能不能通过分析年老父母的集成数据,进而获得他们的健康信息?能不能通过这些集成数据,比较不同的医学治疗方案?如果这些能实现,“你若安好,便是晴天”,便不再是一句空洞的“文艺腔”,而是一席“温情脉脉”的期望。
人,是一切数据存在的根本。人的需求是所有科技变革发展的动力。可以预见,不远的将来,数据革命下一步将进入以人为本的小数据的大时代。当然,这并非说大数据就不重要。一般来说,从大数据得到规律,用小数据去匹配个人。吴甘沙先生用《一代宗师》的台词来比拟大、小数据的区分,倒也甚是恰当。他说,小数据“见微”,作个人刻画,可用《一代宗师》中“见自己”形容之;而大数据“知著”,反映自然和群体的特征和趋势,可用《一代宗师》中的 “见天地、见众生”比喻之。
著名科技史学家马尔文·克兰兹伯格(Melvin Kranzberg)提出的“克兰兹伯格第一定律”指出,“技术既无好坏,亦非中立”,即技术确实是一种力量,但“与社会生态技术的相互作用,使得技术发展经常有问题,远远超出了技术设备的直接目的和实践自己的环境,人类释放出来的技术力量与人类本身互动的复杂矩阵,都是有待探索的问题,而非必然命运”。
前面我们说道大数据可能存在数据安全及隐私问题,事实上,小数据同样存在类似的问题,甚至更为严峻。我们应清楚,诸如大数据、小数据的科技,既可以为公众谋福利,也可能对人造成伤害。关键就是,如何在机遇与挑战间寻找到最佳的平衡。
5.小结
在数据的江湖里,既有波澜壮阔的大数据,也有细流涟漪的小数据,二者相辅相成,才能相映生辉。美国电子电气工程师协会会士(IEEE Fellow)、中国科学院计算技术研究所研究员闵应骅表示[25]:目前大数据流行,人们就“言必称大数据”,这不是做学问的态度,不要碰到大量的数据,就给它戴上一顶帽子“大数据”。目前,各行各业碰到的数据处理多数还是“小数据”问题。不管是大数据还是小数据,我们应该敞开思想,研究实际问题,切忌空谈,精准定位碰到的数据业务问题,以应用为导向,而非以技术为导向,不要哪个技术热,追逐哪个。
《Fierce Big Data》编辑Pam Baker表明[26],当你在寻思如何抉择大数据,还是小数据时,先搁置这事儿。思量一下,你的公司是否擅长利用数据创造价值,如果你的公司还没有达到这个境界,那先把这事解决了再说。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
CDA持证人简介 刘伟,美国 NAU 大学计算机信息技术硕士, CDA数据分析师三级持证人,现任职于江苏宝应农商银行数据治理岗。 学 ...
2025-04-21持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28






