机器学习从入门到放弃之决策树算法
决策树故名思意是用于基于条件来做决策的,而它运行的逻辑相比一些复杂的算法更容易理解,只需按条件遍历树就可以了,需要花点心思的是理解如何建立决策树。
举个例子,就好像女儿回家,做妈妈的给女儿介绍对象,于是就有了以下对话:
妈妈:女啊,明天有没有时间,妈妈给你介绍个对象
女儿:有啊,对方多大了。
妈妈:年龄和你相仿
女儿:帅不帅啊
妈妈: 帅
女儿:那我明天去看看
妈妈和女儿对话的这个过程中,女儿的决策过程可以用下图表示:

你可能会认为,这个决策的过程本质上就是对数据集的每一个做if--else的判断,这不很简单吗?那为什么还要专门弄一个算法出来呢?
不妨可以考虑两点,假如训练数据集中存在无关项,比如以下的例子:
10-1 #表示第一项特征是1,第二项特征是0,最后推出的结果是1,以下同理
12-1
05-0
09-0
17-1
……
显然的,最后结果和第二个特征无关,如果仍要做判断就会增加了损耗。所以在建立决策树的过程中,我们就希望把这些无关项扔掉。
第二点,回到妈妈给女儿介绍对象的这个例子,上图是为了方面读者理解,所以按照顺序画出,但事实上,有一个严重的问题,比如说女儿可能不能容忍某个缺点,而一旦对方的性格中具有这个缺点,那么其他一切都不用考虑。也就是说,有一个特征跟最后的结果相关度极高,这时我们就希望这个数据出现在根节点上,如果核心条件不满足那就结束遍历这棵树了,避免无谓的损耗。
总言言之,决策树第一个是需要从大量的已存在的样本中推出可供做决策的规则,同时,这个规则应该避免做无谓的损耗。
算法原理
构造决策树的关键步骤是分裂属性。分裂属性值得就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。这时分裂属性可能会遇到三种不同的情况:
对离散值生成非二叉决策树。此时用属性的每一个划分作为一个分支。
对离散值生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
属性是连续值。确定一个split_point,按照>split_point和<=split_point转成成离散,分别建立两个分支
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式方法,它决定了拓扑结构及分裂点split_point的选择。
在这里仅介绍比较常用的ID3算法。
从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
循序本系列的从工程角度理解算法,而非数学角度理解算法的原则,因此这里只给出信息增益度量的计算方式,如果需要深入了解其数学原理,请查阅专业资料。
设D为用类别对训练元组进行的划分,则D的熵计算方法为:
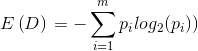
其中pi表示第i个类别在整个训练集中出现的概率。
当按照特征A分割后,其期望信息为:
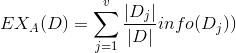
其中Di/D表示每一个D在整体训练集占的比例。
而信息增益即为两者的差值:

其中当gain(A)达到最大时,该特征便是最佳的划分特征,选中最佳特征作为当前的节点,随后对划分后的子集进行迭代操作。
算法实现
github
在本专栏的前面的文章描述了基于决策树的五子棋游戏,算是一个基于决策树的应用了。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330