近年来,随着数据科学的逐步发展,Python语言的使用率也越来越高,不仅可以做数据处理,网页开发,更是数据科学、机器学习、深度学习等从业者的首选语言。
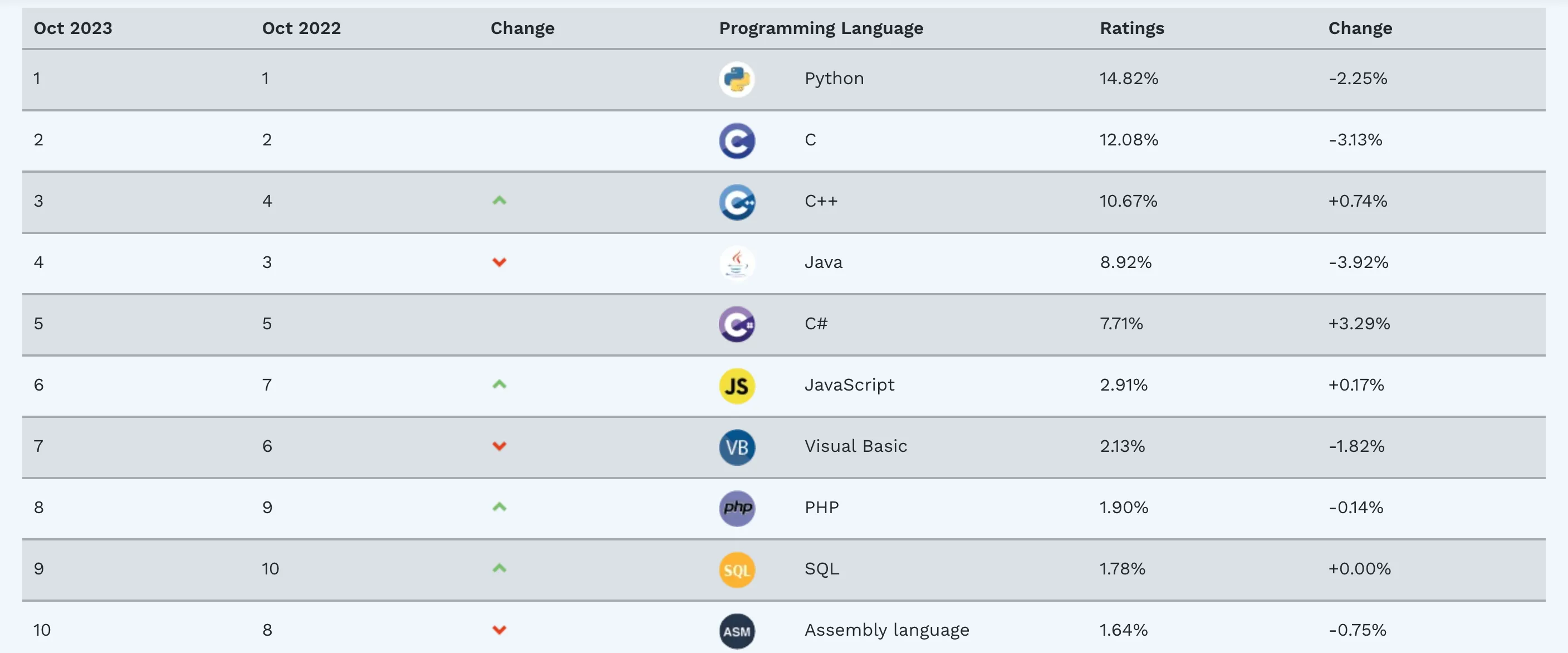
“工欲善其事,必先利其器。” 要做好数据分析,离不开一个好的编程工具,不论是从Python的语法之简洁、开发之高效,招聘岗位之热门来说,Python都是数据科学从业者需要掌握的一门语言。
但一直以来,人们却误以为“学会Python”是件很难的事情。
实则不然,这恰恰是我们选择学Python的理由之一。
事实证明,Python人人皆能学会——千万别不信。
老少皆宜 —— 也就是说,“只要你愿意”,根本没有年龄差异。十二岁的孩子可以学;十八岁的大学生可以学;在职工作人员可以学…… 就算你已经退休了,想学就能学,谁也拦不住你。
不分性别,男性可以学,女性同样可以学,性别差异在这里完全不存在。
不分国界,更没有区域差异 —— 互联网的恩惠在于,你在北京、纽约也好,老虎沟、门头沟也罢,在这个领域里同样完全没有任何具体差异。
尤其是在中国。现状是,中国的人口密度极高,优质教育资源的确就是稀缺…… 但在计算机科学领域,所有的所谓 “优质教育资源” 事实上完全没有任何独特的竞争力 —— 编程领域,实际上是当今世上极为罕见的 “教育机会公平之地”。又不仅在中国如此,事实上,在全球范围内也都是如此。
多年以前,不识字的人被称为文盲……
后来,不识英文,也是文盲。人们发现很多科学文献的主导语言都是英语……
再后来,不会计算机的也算是文盲,因为不会计算机基本操作,很多工作的效率很低下,浪费了很多时间……
近些年,不会数据分析的,也算做文盲了,互联网高速发展,用户行为数据越来越多,
你作为一个个体,每天都在产生各种各样的数据,然后时时刻刻都在被别人使用着、分析着…… 然而你自己却全然没有数据分析能力,甚至不知道这事很重要,是不是感觉很可怕?你看看周边那么多人,有多大的比例想过这事?反正那些天天看机器算法生成的信息流的人好像就是全然不在意自己正在被支配……
怎么办?学呗,学点编程罢 —— 巧了,这还真是个正常人都能学会的技能。
为便于上手学习,在开始前再做两点补充
众所周知,在数据分析相关的编程语言中,有三个重中之重:Python、R、Julia 俗称数据科学三剑客。如果有一个工具能集中编写这三者的代码,为大家省去各种安装开发工具的时间,那简直太好不过了,于是jupyter应运而生,作为“工具的工具”而备受数据科学从业者的青睐!
Jupyter的名字就很好地诠释了这一发集大成的思路,它是 Julia、Python、R 语言的组合,拼写相近于木星(Jupiter),而且现在支持的语言也远超这三种了。
所以需要读者自行下载安装好Anaconda提供的Jupyter notebook或者jupyter lab,以便于更好地运行本文相关代码。安装好后可以直接运行Python,因为里面已经帮你集成好了环境。
虽然笔者力求极简,带你入门Python,但你依然有可能遇到问题,因为编程语言的知识体系有一个特点,知识点之间不是线性的从前往后,而是呈网状的,经常出现前置引用。所以很多时候可能不经意间就用的是后面的知识点,这是不可避免的,遇到这种情况,注定要反复阅读若干遍,之所以取名叫极简入门,这一部分的目标就在与并不是让你立马学会就去写代码,而是让你脱盲……
好了,接下来,与大家一起开始我们的Python旋风之旅,沿用之前《极简统计学入门》、《SQL数据分析极简入门》的“MVP”思路,用三节的内容梳理一下Python数据分析的核心内容。整个系列框架如下:
如果你接触过不同编程语言就会发现,任何编程语言的学习,都离不开3个最基本的核心要素,数据类型、流程控制、函数
数据类型是用来描述数据的性质和特征的,它决定了数据在计算和处理过程中的行为和规则。常见的数据类型包括整数、浮点数、字符串、日期等。简而言之,就是你将要操作的东西具有什么样的特点。
流程控制是指通过条件判断和循环等方式,控制程序按照一定的顺序执行不同的操作步骤。它决定了数据的处理流程,包括判断条件、循环次数、分支选择等。简而言之,就是你要操作这个东西的基本流程是什么。
函数是一段预先定义好的代码,用于执行特定的操作或计算。它接受输入参数,并返回一个结果。函数可以用来对数据进行各种计算、转换、筛选等操作,以满足特定的需求。简而言之,就是你要怎么样才能可复用地操作这一类东西。
我们来看第一个核心要素:数据类型
Python中的数据类型有很多,如果我们按照大类来分,可以分为三大数据类型:
① 数字型
整型 int
a = 2022
type(a)
int
浮点型 float
b = -21.9
type(b)
float
复数型 complex
c = 11 + 36j
type(c)
complex
布尔型 bool
d = True
type(d)
bool
② 字符串型
str_a = "Certified_Data_Analyst"
type(str_a)
str
len(str_a)
22
str_a[0]
'C'
str_a[10]
'D'
str_a[15]
'A'
str_a[:9]
'Certified'
str_a[10:14]
'Data'
str_a[15:]
'Analyst'
str_a * 2
'Certified_Data_AnalystCertified_Data_Analyst'
str_a+"_Exam"
'Certified_Data_Analyst_Exam'
str_a.upper()
'CERTIFIED_DATA_ANALYST'
str_a.lower()
'certified_data_analyst'
int("1024")
1024
str(3.14)
'3.14'
"Certified_Data_Analyst".split("_")
['Certified', 'Data', 'Analyst']
"Certified_Data_Analyst".replace("_", " ")
'Certified Data Analyst'
"7".zfill(3)
'007'
③ 容器型
可以容纳多个元素的的对象叫做容器,这个概念比较抽象,你可以这么理解,容器用来存放不同的元素,根据存放特点的不同,常见的容器有以下几种:list(列表)、tuple(元组)、dict(字典)、set(集合)
列表 list()
用中括号[]可以创建一个list变量
[2,3,5,7]
[2, 3, 5, 7]
元组 tuple()
用圆括号()可以创建一个tuple变量
(2,3,5,7)
(2, 3, 5, 7)
集合 set()
用花括号{}可以创建一个集合变量
{2,3,5,7}
{2, 3, 5, 7}
字典 dict()
用花括号{}和冒号:,可以创建一个字典变量
{'a':2,'b':3,'c':5,'d':7}
{'a': 2, 'b': 3, 'c': 5, 'd': 7}
流程控制
分支
举例说明,我们给x赋值-10,然后通过一个分支做判断,当x大于零时候输出"x是正数",当x小于零的时候输出"x是负数",其他情况下输出"x是零"
x = -10
if x > 0:
print("x是正数")
elif x < 0:
print("x是负数")
else:
print("x是零")
x是负数
循环
举例说明for循环,用for循环来迭代从1到5的数字,并将每个数字打印出来
for i in range(1, 6):
print(i)
1
2
3
4
5
首先,range(1, 6)函数生成一个序列,从1到5(不包括6)。
然后,for循环使用变量i来迭代这个序列中的每个元素。
在每次迭代中,print(i)语句将当前的i值打印出来。
再举例说明while循环:用while循环迭代从1到10的数字,并将每个数字打印出来
i = 1
while i <= 10:
print(i)
i += 1
if i == 6:
break
1
20
3
4
5
首先,将i初始化为1。
然后,while循环将在i小于或等于10时执行。在每次循环中,print(i)语句将当前的i值打印出来。
接下来,i += 1语句将i的值递增。在每次循环中,if i == 6: break语句将检查i的值是否等于6。如果是,则使用break语句终止循环。
函数
Python提供了许多常用函数,这部分内容数据分析最基础的内容,有部分函数在Python内置库就已经自带
常用函数:
abs(x)
round(x)
pow(x, y)
sqrt(x)
max(x1, x2, ...)
min(x1, x2, ...)
sum([x1,x2,...])
也有一些是来自于math库,我们需要用from math import *来引入math库,然后才能调用里面的函数。这个过程就好比你要使用一个工具箱里面的工具,必须先找到工具箱。通过使用这些数学函数,可以进行各种数学计算和数据处理操作。
常用数学函数
from math import *
sqrt(x)
log(x)
log2(x)
log10(x)
exp(x)
modf(x)
floor(x)
ceil(x)
divmod(x,y)
sin(x)
cos(x)
tan(x)
asin(x)
acos(x)
atan(x)
product()
permutations(p[, r])
combinations(p, r)
combinations_with_replacement(p, r)
describe()
count()
sum()
mean()
median()
mode()
std()
var()
min()
max()
abs()
prod()
corr()
cov()
sort()
sorted()
&
|
-
^
intersection()
union()
difference()
symmetric_difference()
isdisjoint()
issubset()
issuperset()
np.nan (Not a Number)
None
pd.NaT
isnull()/isna()
notnull()
isin()
dropna()
fillna()
ffill()/pad()
bfill()/backfill()
replace()
自定义函数
自定义函数是一种在Python中自行定义的可重复使用代码块的方法。通过定义自己的函数,可以将一系列操作放在一个函数中,并在需要时多次调用该函数。
举例说明,如何创建和调用一个自定义函数:
def linear(x):
y = 2*x + 4
return y
在上面的例子中,我们用def linear(x): 定义了一个名为linear的函数,该函数接收一个参数x。
然后函数体内计算了一个y值,它是x的两倍加上4。
这样,我们调用linea函数的时候,并传入一个参数x时,函数将返回计算得到的y值。例如,如果我们调用linear(3),函数将返回10,因为2*3 + 4 = 10。
可以根据具体的需求来编写自定义函数,并在程序中调用它们。
再看一个稍微复杂一点的例子(PS:建议初学者先跳过这个例子)
def fib(n):
n1=1;n2=1;n3=1
if n<1:
print('输入有误!')
return 0
else:
while (n-2) > 0 :
n3 = n2 + n1
n1 = n2
n2 = n3
n -= 1
return n3
result = fib(35)
result
9227465
def fib(n):
if n < 1:
print('输入有误!')
return -1
elif n == 1 or n == 2:
return 1
else:
return fib(n-1) + fib(n-2)
result = fib(35)
result
9227465
import numpy as np
def dotx(a,n):
for i in range(1,n+1):
if i == 1:
b = a
else :
b = np.dot(a,b)
return b
def fib(n):
a = np.array([[1,1],[1,0]])
r = dotx(a,n)
return r[0,1]
result = fib(35)
result
9227465
下一节 《第2节 Pandas简介》
这里分享一个你一定用得到的小程序——CDA数据分析师考试小程序。 它是专为CDA数据分析认证考试报考打造的一款小程序。可以帮你快速报名考试、查成绩、查证书、查积分,通过该小程序,考生可以享受更便捷的服务。 扫码加入CDA小程序,与圈内考生一同学习、交流、进步!












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330