在当今的数据驱动世界中,机器学习 方法在数据挖掘 与分析中扮演着核心角色。这些方法通过从数据中学习模式和规律来构建模型,实现对未知数据的预测和分析。随着大数据和计算能力的迅速发展,机器学习 的应用范围日益广泛,为各个行业提供了强大的工具来解决复杂问题。
监督学习 特征 与输出标签之间的关系。这种学习方式在现代数据分析中占据着重要地位,常见的算法包括决策树 、支持向量机 、逻辑回归 和神经网络 等。
决策树 决策树 具有易于理解和解释的特点,是入门级数据科学家常用的工具。一个简单的实例如预测天气:可以通过决策树 来判断某天是否适合进行户外活动,基于温度、湿度、降水概率等因素。
支持向量机 (SVM )SVM 的一个应用实例是邮件过滤,通过学习标记为“垃圾邮件”和“非垃圾邮件”的样本来提高分类的准确性。
实际应用的价值 有一次,我帮助一家零售公司优化其库存管理系统。通过使用监督学习 ,我们构建了一种预测模型,能够根据历史销售数据和季节性趋势预测未来的需求。这不仅降低了库存成本,还提高了顾客满意度,因为商品的供应更为准确。
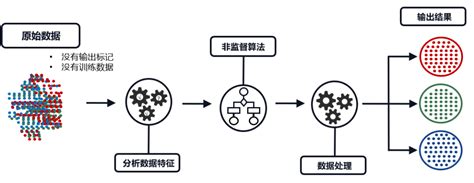
无监督学习 在没有标注数据的情况下,让模型自动发现数据中的隐藏结构和模式。这种方法特别适合用于数据预处理 和探索分析。
聚类 分析聚类 分析的典型代表,它被广泛用于市场细分和图像压缩 。
降维 PCA )和奇异值分解(SVD )是常用的降维 技术,用于降低数据集的复杂性,同时尽可能保留有用的信息。这在图像处理 和文本分析中有重要应用。
关联规则 挖掘
强化学习 强化学习 在自动驾驶、机器人控制和游戏中取得了重大进展。
一个经典的强化学习 案例是围棋AI“AlphaGo”的成功。它通过自我对弈和策略优化,突破了人类在这一复杂棋类游戏上的极限。这种学习方式强调试错和反馈,是对传统编程方法的革命性突破。
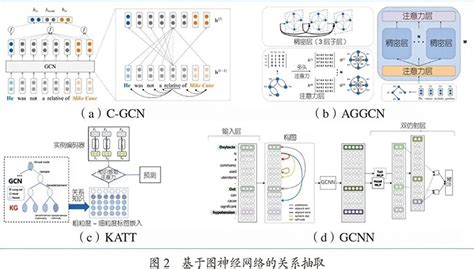
图数据挖掘 :结构化数据的深度探索 图数据挖掘 是数据挖掘 中的一个重要领域,涉及多种机器学习 方法。例如,图自监督学习 、图半监督学习 、图主动学习和图迁移学习 等技术可以有效地利用图数据的结构化特性,提高数据挖掘 的效率和准确性。
在实际应用中,机器学习 方法还可以结合图神经网络 (如GCN、GAT)进行图数据的深度学习 ,以进一步分析网络图 数据。这些方法在社交网络分析、推荐系统 、生物医学等领域有广泛应用。
图神经网络 在处理复杂的图结构数据时展现出强大的能力。比如,在社交网络中,我们可以使用图神经网络 来识别用户群体和预测可能的社交连接。这种能力对推荐引擎的优化起到了关键作用。
职业发展与CDA认证 在数据挖掘 及分析的职业发展中,取得专业认证是提升职业竞争力的有效途径。CDA(Certified Data Analyst)认证因其对行业标准的严格执行和对实际技能的关注,在国际数据分析领域获得广泛认可。持有CDA认证能体现出分析师对数据挖掘 、统计分析 和机器学习 等核心技能的掌握,有助于在职业市场中脱颖而出。
综上所述,机器学习 方法在数据挖掘 与分析中发挥着至关重要的作用。不同的机器学习 算法和技术可以帮助我们从复杂的数据中提取有价值的信息,并做出科学的决策。在不断变化的技术环境中,掌握这些先进的分析工具将为数据分析从业者提供无限的可能性。
随着技术的发展和应用场景的扩展,未来的数据分析将更加智能和自动化,这为我们提供了更广阔的研究空间和创新机遇。通过持续学习和实践,我们能够有效地应对数据分析领域的挑战,为各行业带来更大的价值。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名 ”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材”
▷ 想加入 CDA考试题库 ,点击>>> “CDA 题库 ” 了解CDA考试题库;
▷ 想了解CDA 考试 含金量 ,点击>>> “CDA含金量”
▷ 想了解CDA 院校合作 ,点击>>> “院校合作”











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330