当下,在线行为分析已并不罕见,但对整个音乐产业进行分析仍然不是一件容易的事情——你需要横跨Spotify、iTunes、YouTube、 Facebook等众多流行平台进行相关跟踪,其中包括近5亿的音乐视频流、下载、艺术家页面上产生的大量likes(每日)等,这将给分析系统扩展性带 来巨大的挑战。Next Big Sound每天从100多个源中收集这些数据,进行分析,并通过基于网络的分析平台将这些信息提供给唱片公司、乐队经理及艺术家。
时至今日,类似Hadoop、 HBase、Cassandra、MongoDB、RabbitMQ及MySQL这样的开源系统已在生产环境中得到了广泛应用,Next Big Sound正是基于开源构建,然而Next Big Sound的规模显然更大了一些——从超过100个源接收或收集数据。Eric团队首先面临的问题就是如何处理这些不停变化的数据源,最终他们不得不自主 研发了一个存储系统,从根本上说是个可以“version”或者“branch”化从这些数据源上收集的数据,类似GitHub上的代码版本控制。 Next Big Sound通过给Cloudera发布版增加逻辑层来实现这个需求,随后将这个层与Apache Pig、 HBase、Hive、HDFS等组件整合,形成一个在Hadoop集群上海量数据的版本控制框架。
作为 “Moneyball for Music”一 员,Next Big Sound开始只是个运行在单服务器上的LAMP网站,为少量艺术家追踪MySpace上的播放记录,用以建立Billboard人气排行榜,以及收集 Spotify上每首歌曲上产生的数据。随着数据以近指数级速度的增长,他们不得不选用了分布式系统。同时,为了跟踪来自公共及私有提供者的100多个数 据源和不同性质音乐的分析处理,Next Big Sound需要比当下开源数据库更优秀的解决方案。
Next Big Sound一直保持着非常小的工程团队,使用开源技术搭建整个系统,采用过完全云架构(Slicehost)、混合云架构(Rackspace)、主机托管(Zcolo)等不同架构形式。
使用类似Cassandra 及HBase这类分布式系统存储时间序列是很容易的,然而,随着数据和数据源的暴增,数据管理变得不再容易。传统情况下,整合从100+数据源中搜集数据 的工作包含以下两个步骤:首先,在Hadoop ETL管道对原始数据进行处理(使用MapReduce应用、Pig或者Hive);其次,将结果存储到HBase以便后续Finagle/Thrift 服务的检索。但是在Next Big Sound,情况有了些不同,所有存储在Hadoop/HBase中的数据通过一个特殊的版本控制系统维护,它支持ETL结果上的改动,允许根据需求来修 改定义处理管道的代码。
在对Hadoop数据进行再计算时,使用“版本化”管理Hadoop数据提供了一个可恢 复及版本化途径,扩展了许多数据处理周期技术(比如LinkedIn)。而Next Big Sound系统的区别在于可以配置版本化的等级,而不是必须在全局运行,举个例子:在记录一个艺术家某个地理区域上tweet转发次数的用例中,忽然发现 在某个时间段内基于地理位置编码的逻辑是错误的,只需建立这个时间段的新数据集就可以了,从而避免了对整个数据集进行重建。不同的数据通过版本进行关联, 也可以为某些用户指定所访问数据的版本,从而实现只有在数据精确时才对用户释放新的版本。类似这样的“Branching”数据可以应对数据源和客户需求 的变化,同时也可以让数据管道更高效。更多详情查看下图(点击查看大图):
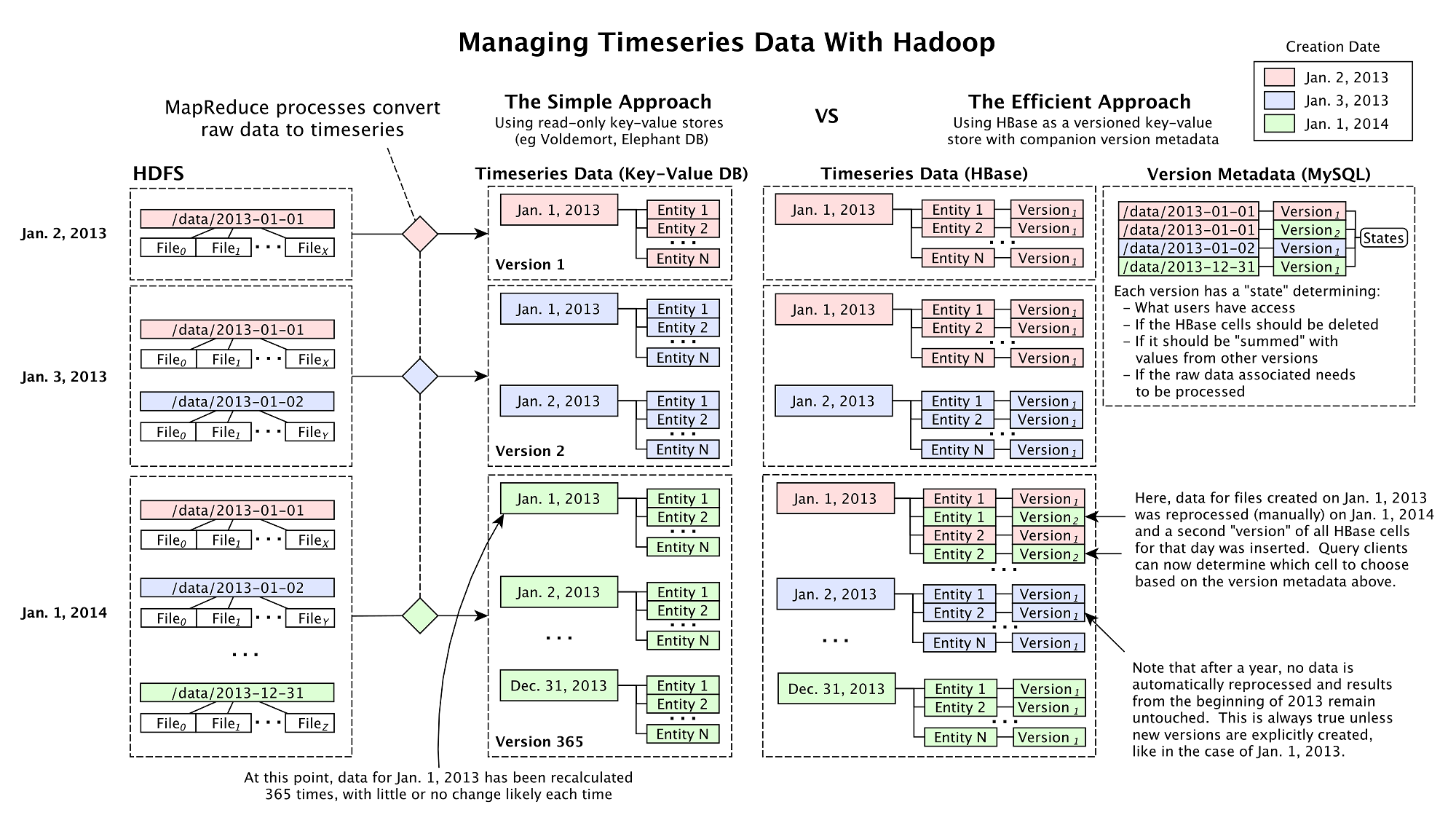
在Hadoop 基础设施方面,同样面临了很多难题:1,跨整个音乐产业的社交网络和内容发布网站的实体关系映射;2,贯穿上千万数据集建立用于排序和搜索的Web应 用;3,管理数百万API调用的信息以及网络爬虫。这些操作都产生了特定的需求,而在Next Big Sound,系统完全建立在开源技术之上,下面是一个概况图(点击查看大图):

数据显示
测量仪表盘一直都是个进行中的项目,这个工作大部分由用户需求主导。由于数据源太多,这里的长期目标是做灵活性和学习曲线之间的平衡;同时,由于新客户和特性的增加,维持一个连续的JavaScript/PHP代码库进行管理也变得愈加困难。Next Big Sound操作如下:
没有做功能标志,但是使用了自己的方法。如果某个代码库经常被重写,这点将非常重要,没有它,很多事情我们都完成不了。
FIND
投 入大量精力做用户基于给定条件的数据集搜索,这个功能被定义为“FIND”项目的预览版本。类似股票筛选器,用户可以做类似的查询。比如:Rap艺术家, 占YouTube视频播放数的30-40百分位,同时之前从未出现在任何流行排行榜上。这个功能主要依赖于MongoDB,在MapReduce作业提供 了大量索引集的情况下,系统完全有能力以近实时速度完成数百万实体上的查询。
MongoDB在这个用例上表现的非常好,然而其中一直存在索引限制问题。Next Big Sound一直在挑战这个瓶颈,ElasticSearch得到了重点关注。
内部服务
产品使用了所有度量数据,API 由1个内部Finagle服务支撑,从HBase和MySQL中读取数据。这个服务被分为多个层(同一个代码运行),关键、低延时层通常直接被产品使用, 一个具备更高吞吐量、高延时的二级层则被用作编程客户端。后两个方向一般具有更多的突发性和不可知性,因此使用这样的分离层可以给客户交付更低的延时。这 样的分层同样有利于为核心层建立更小的虚拟机,将Finagle剩余的服务器共至于Hadoop/HBase机器上。
Next Big Sound API
支撑Next Big Sound内外共同使用的主API已经过多次迭代,下面是一些重点建议:
提醒和基准
在音乐的世界里随时都有事情发生,为了获得“有意义”的事情,Next Big Sound必须在所有平台建立基准数据(比如Facebook 每天产生like的数量),并提醒客户。开始时也遇到过许多扩展性问题,但是在使用Pig/Hadoop做处理并将结果储存在MongoDB或MySQL 后,事情简单了起来。Next Big Sound所做的工作就是发现趋势,那么给“有意义”设立临界值就变得至关重要,因此在做基准时必须使用尽可能多的数据,而不是只从某个数据上入手,与基 准线的偏离量将代表了一切。
Billboard Charts
Next Big Sound被授权做两个Billboard 杂志排行榜,一个是艺术家在线流行指数总排行,另一个是哪个艺术家可能会在未来排行榜上占据一席之地。这个功能并未造成任何扩展性问题,因为只是做所有艺 术家得分的一个反向排行,但是制造一个无重复、有价值的列表显然需要考虑更多因素。非实名给系统带来了大量麻烦(比如Justin Bieber的Twitter用户名到底是"justinbieber"、"bieber"及"bieberofficial"中的哪一个),通常情况 下,会采用机器和人工组合来解决这个问题。基于1个人名的选错会产生重大影响,手动完成则必不可少。随后发现,为在系统上增加这个“功能”,即让它记住类 似的处理方法并有能力重现将变得非常有效,幸运的是,这个系统实现难度并不大。
预测Billboard得分
在 哪个艺术家将会在下一个年度爆发的预测上曾开发了一个专利算法,这个过程应用了Stochastic Gradient Boosting技术,分析基于不同社交媒体成员的传播能力。在数学方面,实现难度比较大,因为许多使用的工具都非Hadoop友好实现,同时也发现 Mahout表现非常一般。这里的处理过程包括输入数据集、通过MapReduce作业写入MongoDB或者是Impala,通过R-MongoDB或 者R-Impala来兼容R,然后使用R的并行处理库在大型机上处理,比如multicore。让Hadoop承担大部分负载和大型机承担剩余负载带来了 很多局限性,不幸的是,暂时未发现更好的解决办法,或许RHadoop是最好的期望。
1. 必须拥有自己的网络解决方案。如果你想从小的团队开始,确保你团队中有人精通这个,如果没有的话必须立刻雇佣。这曾是Next Big Sound最大的痛点,也是导致一些重大宕机的原因。
2. 在 不同的主机托管提供商之间转移总是很棘手,但是如果你有充足的额外预算去支付两个环境运行主机的开销,那么风险将不会存在。抛开一些不可避免的异常,在关 闭旧供应商的服务之前,将架构完全复制到新服务供应商,并做一些改进。使用提供商服务往往伴随着各种各样的问题,对比因此耗费的工作及宕机时间来说,资金 节省根本不值一提。
3. Next Big Sound有90%的工作负载都运行在 Hadoop/HBase上,鉴于大部分的工作都是数据分析而非用户带访问网站产生,因此峰值出现的很少,也就造成了使用提供商服务开销很难比自己托管服 务器低的局面。Next Big Sound周期性的购买容量,但是容量增加更意味着获得了更大的客户或者是数据合作伙伴,这也是为什么使用自己硬件可以每个月节省2万美元的原因。
1. 如果你从很多的数据源中收集数据,同时还需要做适度的转换,错误不可避免会发生。大多数情况下,这些错误都非常明显,在投入生产之前给予解决;但是也有一些时候,你需要做充足的准备以应对生产过程中发生的错误。下面是一些生产过程中发现的错误:
在这些情景下可能存在更明智的做法,直到出现的次数足够多,你才会明确需要修改这些不能被完全删除的生产数据并重建,这也是为什么Next Big Sound为之专门建立系统的原因。
2. 多数的数据都使用Pig 建立并处理,几乎所有的工程师都会使用它。因此,工程师们一直在致力研究Pig,这里不得不提到Netflix的Lipstick,非常有效。这个过程中 还发现,取代可见性,降低Pig上开发迭代的时间也非常重要。同时,在测试之前,花时间为产生20+ Hadoop作业的长期运行脚本建立样本输入数据集也非常重要。
3. 关于HBase和Cassandra,在使用之前讨论这两个技术的优劣纯粹是浪费时间,只要弄懂这两个技术,它们都会提供一个稳健且高效的平台。当然,你必须基于自己的数据模型和使用场景在这两个技术之间做选择。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27






