R语言使用密度聚类笔法处理数据
说明
除了使用距离作为聚类指标,还可以使用密度指标来对数据进行聚类处理,将分布稠密的样本与分布稀疏的样本分离开。DBSCAN是最著名的密度聚类算法。
操作
将使用mlbench包提供的仿真数据
library(mlbench)
library(fpc)
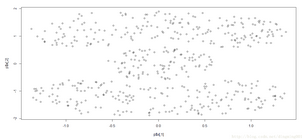
使用mlbench库绘制Cassini问题图:
set.seed(2)
p = mlbench.cassini(500)
plot(p$x)
根据数据密度完成聚类:
ds = dbscan(dist(p$x),0.2,2,countmode = NULL,method = "dist")
> ds
dbscan Pts=500 MinPts=2 eps=0.2
1 2 3
seed 200 200 100
total 200 200 100
绘制聚类结果散点图,属于不同簇的数据点选用不的颜色:
plot(ds,p$x)
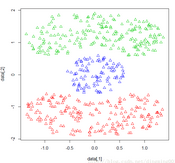
根据聚簇标号绘制的彩色散点图
调用dbscan来预测数据点可能被划分到那个簇,在样例中,首先在矩阵P中处理三个输入值:
生成y矩阵
y = matrix(0,nrow = 3,ncol = 2)
y[1,] = c(0,0)
y[2,] = c(0,-1.5)
y[3,] = c(1,1)
y
[,1] [,2]
[1,] 0 0.0
[2,] 0 -1.5
[3,] 1 1.0
预测数据点属于那个簇:
predict(ds,p$x,y)
[1] 3 1 2
原理
基于密度的聚类算法利用了密度可达以及密度相连的特点,因而适用于处理非线性聚类问题。当探讨密度聚类算法的处理过程前,我们要知道基于密度的聚类算法通常需要考虑两个参数,eps和MinPts,其中eps为最大领域半径,MinPts是领域半径范围内的最小点数。
确定好这两个参数后,如果给定对象其领域范围内的样本点个数大于MinPts,则称该对象为核心点。
如果一个对象其领域半径范围内的样本点个数小于MinPts,但紧挨着核心点,则称该对象为边缘点。
如果P对象的eps领域范围内样本点个数大于MinPts,则称该对象为核心对象。
进一步,我们还要定义两点间密度可达的概念,给定两点p和q,如果p为核心对象,且q在p的eps邻域内,则称p直接密度可以达q。如果存在一系列的点,p1,p2,…,pn。且p1 = q,pn = p,根据Eps和MinPts的值,当1<=i<=n,pi + 1 直接密度可以达pi,则称p的一般密度可以达q。
DBSCAN处理过程:
1.随机选择一个点p
2.给定Eps和MinPts的条件下,获得所有p密度可达的点
3.如果p是核心对象,则p和所有p密度可达的点被标记成一个簇,如果p是一个边缘点,找不到密度可达点,则将其标记为噪声。接着处理其它点。
4.重复这个过程,直到所有的点被处理。
本例使用dbscan算法聚类Cassini数据集,将可达距离设置为0.2,最小可达点个数设置为2,计算进度设为NULL,使用距离矩阵做为计算依据。经过算法处理,数据被划分成三个簇,每个簇的大小分别为200,200,100.通过聚簇的结果示意图也可以发现Cassini图被不同颜色区分开来。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试详情;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试详情;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330
