北京焦灼?上海颓废?大数据如何解读城市性格?
城市如人,在形成的过程中也会显现出独特的性格。具有特殊文化品格和精神气质的城市,无疑是最具吸引力而叫人难忘的。但你是否想过,如何用大数据深度探寻一个城市专属的性格特色,了解城市心理?在1月4日的数据侠线上实验室,DT君邀请到城市象限的地产业务总监张希煜,她通过挖掘分析歌词、豆瓣、点评等多维数据,对城市性格特征进行轮廓侧写,有趣生动地为我们讲述了如何用大数据解密城市性格。
何谓城市性格?
说到城市性格,也许大家会觉得城市性格是一个复杂且充满神秘的话题。首先,我将从人的性格研究开始讲。因为这是所有科学研究当中最为通俗化的内容,任何一个人有可能不知道某个专业领域的研究,但他一定知道关于人的性格科学或伪科学的研究,比如大家接触到最多的星座、血型、八字的研究。
我把人的性格研究划分成了成因研究和表现研究两个部分。
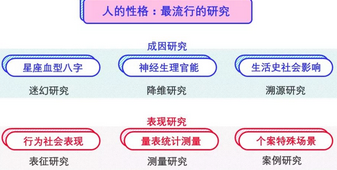
从成因研究上来看,这三个类型对城市性格研究有较大的借鉴意义,可以借鉴到分析城市性格的类型化研究中去。
一是星座、血型、八字类的迷幻研究,它的一大特点是会充分折叠一切可以观测的现象,能在折叠中寻找出凸显话题性的方式,从而讯速博取大家的关注,形成共鸣。这可以对应到文人作家是如何描述城市特点的,他们会提取一些非常抽象的内容,以一种比较具有感染力但不全面的方式去表达,从而形成对一个城市的简单感性的描述。
二是神经生理观能类的降维研究,人的性格和脑功能、生理结构、神经系统有很大的关系,这类研究是把高度复杂、多维的结构还原到较单纯的物理基础内容,从而去探究它的成因和表现的过程。对应到城市研究,就像是通过城市空间有形可见的物理功能性元素,去探究城市性格的表现。
三是生活史社会影响类的溯源研究,主要针对如何挖掘过去的事情,包括环境变化是如何影响性格形成的。这可以对应到我们对城市文化溯源、发展历程的研究中。
个体间的区别促生个性,对城市来讲也是这样——由于气候、历史、建筑、习俗、方言、食性等等诸多不同,城市才会有血肉有灵魂,谓之“城市性格”。研究一个城市的城市性格,不可避免地要去做一个全面的分解。

我们认为城市性格是从物理到心理的。
其中城市空间是我们所在城市性格展示的空间载体,包括了建筑元素和交通元素;城市场景由我们的交互过程、认知、情感、行为建构;另一方面,我们也是城市个体化的成员,集聚成群体化的方式去呈现城市性格,我个人认为城市成员是城市性格最为核心的内容。
所以综上所述,城市性格是一种城市特性的集合,是在城市空间和城市场景的影响之下,城市成员所表现出来的特点和特征。

城市性格与大数据间的碰撞融合
类比人的性格,我们通过行为情感和认知反映关注城市性格特质,而大数据是作为城市性格的素材。
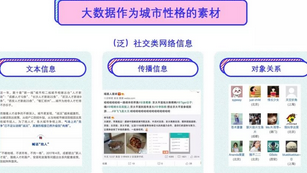
这个素材主要是三个层面:
一是社交网络类的信息网站上提供的广泛文本信息,它和我们一般接触到的纯数据最大的区别是,文本信息是一种信息量大且折叠程度高的信息,其中的分析内容有很大的空间可以去主观操作、创作。
二是社交网络类网站提供的对某一个信息传播方式及传播范围的指向性数据,这为我们提供了观测每一个贡献信息的人之间关系的方式。我们可以通过这些用户是否对同一件事情发表评论、是否参与同一个活动、是否分享了类似的内容等途径去构建用户之间的关系。
三是对象关系,主要是通过挖掘用户与用户之间、参与者与参与者之间的内在联系,比如通过豆瓣同城,可以将关注同一类或同一个活动的用户建立成一个群组,这样他们就有了一个维度上联系。
在基于种种途径去挖掘城市性格时,实际上是在建立一个更为丰满的城市感知。

通过和其他传统城市感知方式来对比,当我们去试图建立城市性格时,实际上是在挖掘一个城市发展的内部动机。那么它的源头是什么?这是一个很好的视角,因为如果去对比一些传统的研究方式,大家很容易发现如果仅仅是以建立因果联系就去做发展预判,会导致对城市的预测是扁平的。
焦灼的北京 VS 颓废的上海
谈到各个城市的性格,很多人会第一时间想到上海与北京。它们是近代以来中国的两个最大的都市,一南一北,互为“他者”,无论是城市形态、社会分层,还是城市景观、文化风格,都呈现出鲜明的对比。
对北京和上海的比较,永远是大家乐此不疲的话题。那么对生活在这两个城市的人来说,他们所怀的城市情感是怎样的呢?
为了找到答案,我们团队在去年5月做了一个研究:通过挖掘北京和上海歌词文本信息探测其城市情感,我从中节选了一些研究结果展示。
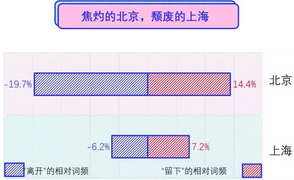
我们提取了“离开”和“留下”两个对立性的词语作为指向词,用以评估两座城市,大家通过词频可以明显看到,相比于上海,北京是一座在离开和留下之间非常纠结挣扎的城市。
这张图是类比语言学研究方式后建立的词库:
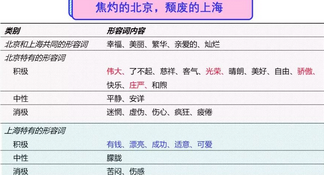
我们通过词库来对比两座城市词性的相似和异同,最后建立了一个形容词列表。从中我们发现北京会有更多积极的词语,描述感情更为激烈,色彩更为明确;而上海会更多地使用一些私人化的词汇,表现更多的是朦胧的情感。
另外关于歌词,我们建立了一个词与词之间联系的主成员分析图表,具体如下图:
我们团队也在试图去建立一个基于文化地图之上的城市词频地图,希望能够挖掘到更为广泛的语料信息,通过词与词之间的关联,挖掘城市背后的故事,目前还在起步阶段。
选餐厅:北京追网红,上海觅小众
俗话说“民以食为天”,饮食也是构成城市性格必不可少的一部分。我们通过分析大众点评的数据做了关于两座城市推荐餐厅的研究,其中数据主要是从大众点评上的社区推荐上爬取了大家推荐的不同商铺信息和传播情况。

通过对比北京和上海的推荐数据,我们发现在北京大家更倾向于去推荐人气餐厅、网红餐厅、爆款餐厅,而在上海大家更喜欢推荐小众、有特色的餐厅,且推荐的接受度比北京要高一些。
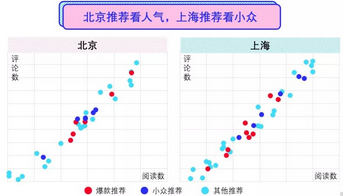
当然这只是我们巨大研究链条当中小小的一环,但从这个小细节上可以看到两座城市的性格差异。北京更倾向于追求人气、热闹的消费氛围,但上海相对于北京而言,更看重小众、独立、私人化的消费氛围。
比文化:北京爱历史,上海重商业
文化是时间的沉淀,更是城市永恒的追求,一个具有特殊文化品格和精神气质的城市,无疑是最具吸引力而叫人难忘的。那么北京和上海在城市文化上相比又如何呢?
我们爬取了豆瓣同城上的数据,这些数据内容包括在城市范围内发生的文化活动的名称和性质、参与者的发生时间、消费门槛、文字描述等信息。

我们利用这些数据做了关于活动特性、活动参与者、活动发生地点等分析。以下两张地图是根据北京和上海豆瓣同城上的活动数据(活动距离商圈、文明古迹、老城区等的距离)进行的分析。
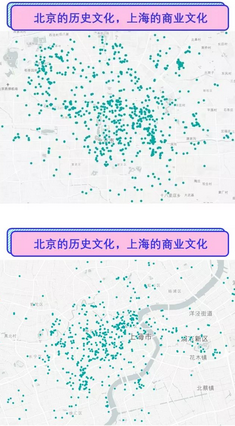
通过这两张地图可以明显发现,北京的文化活动距离历史街区、文化遗产更近一些,而上海的文化活动更靠近一些商业机构和商圈。基于这一结果可以猜测,北京的文化活力、文化内容更为明显地受到了其历史文化的影响;而上海更为核心的发展动力是其商业文化或是商业动机。
下面这一张图是关于活动类型的对比:
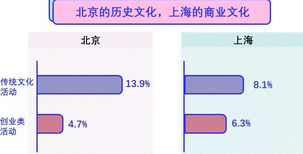
我们依据活动内容的描述将其划分成两个类别,第一类是传统文化类的活动,包括京剧表演、手艺表演、城市文化资源分享等;另外一类是创业类的活动,主要是工作坊、演讲培训、游戏等。
那么从比例上,大家可以发现北京的传统文化活动明显高于创业类文化活动,而在上海这个数值上则很接近。这更明显的反映,商业文化对于文化活动在上海的渗透,也从侧面表现出上海的城市性格更倾向于追求一种价值的分享,而北京更多的是关于文化体验、传承的分享。
小区名:北京喜复古,上海崇洋气
除了情感、饮食和文化,北京和上海在小区命名上也存在着很大的差异。
我们对比了不同城市住宅小区的命名,通过把小区名称、小区位置、小区类型、房价规模等数据提取出来进行一系列研究。从中我们发现了一些很有意思的成果,下面节选了北京和上海的两个小片段。

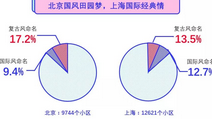
北京(尤其是在2005年以后)的小区,在命名上喜欢田园风或是中国风,而上海则更偏爱国际经典情,下图列表上有几个例子:

大家可以看到像耕天下、礼士阁以及江南山水、扬州水乡这种“CP感”明确的小区名字越来越多;而在上海则会看到更多舶来词,如城市经典高迪、莫奈庄园、硅谷商墅等。
这些名字也反映出了所在城市居民的价值取向,我们研究了两种类型名字在整个城市小区中的占比情况,可以看到相对来说北京用田园复古风的命名会更多一点,上海则用国际风的命名会稍多一点。
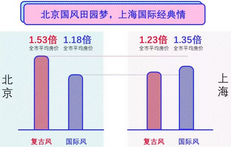
第二张图是关于两种风格房价的对比,由于涉及到房价数据,数据比较敏感,所以很难横向对比,我们是通过对比这一类型房子均价大概是全市均价的多少倍数得到的。很容易发现在北京,以复古风命名的小区明显会卖得更贵一些,而上海则是相反。
以上只是城市象限研究的一部分,但我们的研究不止这些,目前我们还有一个脑洞是关于如何通过城市地名的命名方式去挖掘城市的性格,观察胡同街道名称、桥梁道路名称、水系名称等数据,从中发现城市的价值取舍、希望寄托、外来文化、红色文化等对城市的影响。
举例来说,通过看全国有多少红旗街、红旗路以及分布在全国的哪些地区;又或者通过对比北京胡同和上海弄堂的命名,从而发现当中寄托了城市什么样的愿景;还有历史传流下来的文化图腾的命名方式……这些都能让我们发现各个城市的性格特点。
关于我的分享就到这里,希望能给大家带来启发。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330