下一个GAN?OpenAI提出可逆生成模型Glow
目前,生成对抗网络 GAN 被认为是在图像生成等任务上最为有效的方法,越来越多的学者正朝着这一方向努力:在计算机视觉顶会 CVPR 2018 上甚至有 8% 的论文标题中包含 GAN。近日来自 OpenAI 的研究科学家 Diederik Kingma 与 Prafulla Dhariwal 却另辟蹊径,提出了基于流的生成模型 Glow。据介绍,该模型不同于 GAN 与 VAE,而在生成图像任务上也达到了令人惊艳的效果。
该研究一经发表,立刻引起了机器学习社区的注意,有人对此表示:终于,我们有了 GAN 以外的优秀生成模型!
本文将介绍 OpenAI 创造的 Glow,一种使用可逆 1×1 卷积的可逆生成模型。它在之前可逆生成模型研究的基础上(论文:NICE: Non-linear Independent Components Estimation、Density estimation using Real NVP)进一步扩展,并简化了架构。OpenAI 提出的模型可以生成逼真的高分辨率图像,支持高效率采样,并能发现用于操作数据属性的特征。目前,OpenAI 已经发布了该模型的代码,并开放了在线可视化工具,供人们试用。
论文:Glow: Generative Flow with Invertible 1×1 Convolutions

Note:OpenAI 的 Glow 和 PyTorch 内置的机器学习编译器重名了。
摘要:由于可以追踪确切的对数似然度、潜在变量推断,以及训练与合成的可并行性,基于流的生成模型(Dinh et al., 2014)在概念上就很吸引人。在这篇论文中我们提出了 Glow,这是一种简单的使用可逆 1x1 卷积的生成流。使用该方法,我们展示了在标准基准上的对数似然度的显著提升。也许最引人注目的是,我们展示了仅通过普通的对数似然度目标优化,生成模型就可以高效地进行逼真图像的合成以及大尺寸图像的操作。




Glow 模型控制人脸图像属性以及和其它人脸图像融合的交互式 demo(读者可在原网页进行交互操作,还可以上传自己的图片)。
研究动机

研究员 Prafulla Dhariwal 和 Durk Kingma 的图像属性操作。训练过程中没有给模型提供属性标签,但它学习了一个潜在空间,其中的特定方向对应于胡须密度、年龄、头发颜色等属性的变化。
生成建模就是观察数据(比如一组人脸图片),然后学习可生成数据的模型。学习近似数据生成过程需要学习数据中存在的所有结构,而且成功的模型应该能够合成与数据相似的输出。精确生成模型应用广泛,包括语音合成、文本分析与合成、半监督学习和基于模型的控制。研究者提出的技术也能应用于上述任务。
Glow 是一种可逆生成模型,也称为基于流的生成模型,是 NICE 和 RealNVP 技术的扩展。相比 GAN 和 VAE,基于流的生成模型迄今为止在研究界受到的关注寥寥无几。
基于流的生成模型具有以下优点:
结果
使用该技术,OpenAI 在标准基准数据集上获得了优于 RealNVP 的显著改进,后者是之前基于流的生成模型的最好结果。

在不同数据集的测试集上对 RealNVP 模型和 Glow 模型的量化性能评估(bits per dimension)对比结果。
Glow 模型在包含三万张高分辨率人脸图像的数据集上进行训练后生成的结果示例。
Glow 模型可以生成逼真的高分辨率图像,而且非常高效。该模型使用一块 NVIDIA 1080 Ti GPU,只需大约 130ms 即可生成一张 256 x 256 的图像,研究人员发现从温度降低的模型中采样通常会带来高质量的样本。上图中的图像示例就是通过将潜在空间标准差的温度缩放 0.7 而得到的。
潜在空间中的插值
研究人员还可以在任意人脸图像之间插值,方法是使用编码器对两张图像进行编码,然后从中间点进行采样。注意:输入是任意人脸图像,而不是从模型中采集的样本,因此这可以证明该模型支持完整的目标分布。
在 Prafulla 的人脸图像和名人面部图像之间进行插值。
潜在空间中的操作
研究人员可以在无需标签的情况下训练一个基于流的模型,然后使用学到的潜在表征进行下游任务,如处理输入的属性。这些语义属性可以是头发的颜色、图像的风格、乐声的音高,或者文本句子的情绪。由于基于流的模型具备一个完美的编码器,因此你可以编码输入,并计算输入在具备和不具备某属性时的平均本征向量(latent vector)。然后利用两个本征向量之间的向量方向来处理任意输入。
上述过程需要相对较小规模的标注数据,可以在模型训练好之后进行(训练过程不需要标签)。之前利用 GAN 的研究(https://arxiv.org/abs/1606.03657)需要分别训练编码器。使用 VAE 的研究(https://arxiv.org/abs/1804.03599)只能保证解码器和编码器可以兼容分布内数据。其他方法包括直接学习表示变换的函数,如 Cycle-GAN,但是它们需要对每一次变换进行重新训练。
使用基于流的模型处理属性的简单代码片段:
# Train flow model on large, unlabelled dataset X
m = train(X_unlabelled)
# Split labelled dataset based on attribute, say blonde hair
X_positive, X_negative = split(X_labelled)
# Obtain average encodings of positive and negative inputs
z_positive = average([m.encode(x)forxinX_positive])
z_negative = average([m.encode(x)forxinX_negative])
# Get manipulation vector by taking difference
z_manipulate = z_positive - z_negative
# Manipulate new x_input along z_manipulate, by a scalar alpha in [-1,1]
z_input = m.encode(x_input)
x_manipulated = m.decode(z_input + alpha * z_manipulate)
该研究的主要贡献(不同于早期 RealNVP 研究)是添加了可逆 1x1 卷积,以及删除其他组件,从而整体简化架构。
RealNVP 架构包含两种层的序列:含有棋盘掩码(checkerboard masking)的层和含有通道掩码(channel-wise masking)的层。研究人员移除了含有棋盘掩码的层以简化架构。含有通道掩码的层执行并重复以下步骤:
1. 通过在通道维度上反转输入的顺序来置换输入。
2. 从特征维的中间向下将输入分成两部分:A 和 B。
3. 将 A 输入浅层卷积神经网络。根据神经网络的输出对 B 进行线性变换。
4. 连接 A 和 B。
将这些层连在一起之后,A 更新 B,B 更新 A,然后 A 再更新 B……这种信息的二分流动(bipartite flow)显然是相当僵硬的。研究人员发现,通过将步骤(1)的反向排列改变为(固定)shuffling 排列,模型性能可以得到改善。
更进一步,模型还可以学习最优排列。学习置换矩阵(permutation matrix)是一种离散优化,不适合梯度上升。但由于置换操作只是具有平方矩阵的线性变换的特例,因此可以用卷积神经网络来实现,置换通道相当于通道数相等的输入和输出的 1x1 卷积运算。因此,研究人员用学习的 1x1 卷积运算替换固定排列。1x1 卷积的权重被初始化为一个随机的旋转矩阵。如下图所示,这一运算带来了模型性能的大幅提升。研究人员还指出,通过对权重进行 LU 分解,可以高效地完成优化目标函数所涉及的计算。
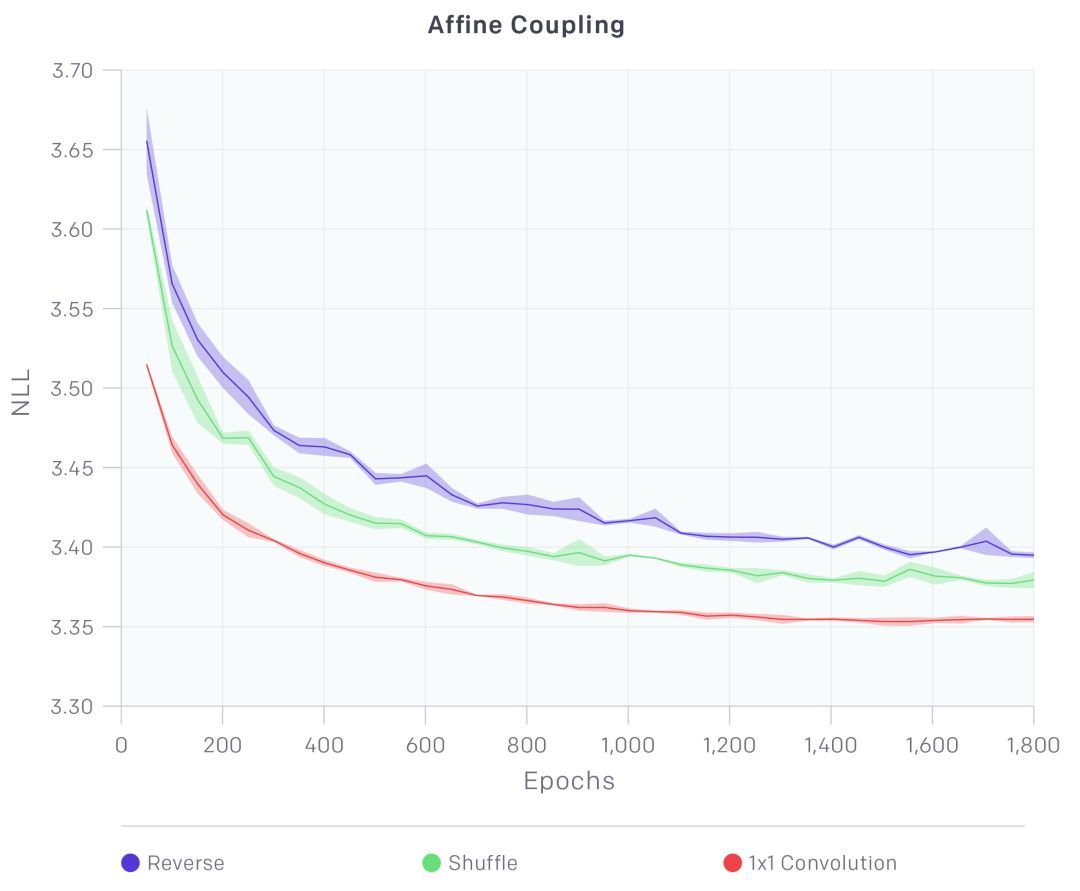
主要贡献——可逆 1x1 卷积,极大地改进了模型。
此外,研究人员删除了批归一化,用一个激活归一化层作为替代。这个层简单地移动和扩大了激活函数,给定数据的初始 minibatch,该层具备依靠数据的初始化技术可对激活函数进行归一化操作。这能把 minibatch 大小缩减到 1(对于较大的图像),把模型大小扩大。
规模
本文提出的架构结合了各种优化方法,例如梯度检查点,因此能够训练规模更大的基于流的生成模型。此外,研究人员使用 Horovod 在机器集群上训练模型。上面 demo 中使用的模型是在有 8 块 GPU 的 5 台机器上训练的。使用这个设置,可以训练具有 1 亿多个参数的模型。
研究方向
本研究表明,训练基于流的模型来生成真实的高分辨率图像并非不可能,而且还能学习隐藏表征,用于数据处理这样的下游任务。研究人员还为未来的研究提供了几个方向:
1. 在似然函数上可与其它模型类别相媲美。自回归模型和 VAE 在对数似然上表现要比基于流的模型好,然而,它们各自有采样效率低、推理不精确的缺陷。可以将基于流的模型、VAE 以及自回归模型三者相结合来权衡其长处。这会是一个有趣的研究方向。
2. 改进架构,从而提高计算与参数效率。为了生成真实的高分辨率图像,人脸生成模型使用了大约 2 亿个参数、600 个卷积层,因此训练成本极高。而较浅的模型在学习长期依存关系时表现会变差。使用自注意架构,或者用更进步的训练方法作为更好的解决方案能够让训练流模型更廉价。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
以下的文章内容来源于刘静老师的专栏,如果您想阅读专栏《刘静:10大业务分析模型突破业务瓶颈》,点击下方链接 https://edu.cda ...
2025-04-23大咖简介: 刘凯,CDA大咖汇特邀讲师,DAMA中国分会理事,香港金管局特聘数据管理专家,拥有丰富的行业经验。本文将从数据要素 ...
2025-04-22CDA持证人简介 刘伟,美国 NAU 大学计算机信息技术硕士, CDA数据分析师三级持证人,现任职于江苏宝应农商银行数据治理岗。 学 ...
2025-04-21持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31






