神探Sherlock如何用AI破案?教你在Excel中搭建一个人脸识别CNN网络
【导读】人脸识别技术已经有了非常广泛的应用,国内大规模监控系统背后运用的技术就是人脸识别。
与大家常规见到的搭建人脸识别的神经网络方法不同,本文作者 Dave Smith 走了一次不同寻常路,他在 Excel 中用 9 步就搭建了一个人脸识别的CNN 神经网络,让神探 Sherlock 识别出世界的终结者“Elon”!在这篇文章中,作者试图以直观的可视化方式呈现出代码背后发生的事情,希望可以帮助大家消除学习过程中的一些疑虑,
本文的目标就是为您提供一个简单的机器学习入门,将涵盖下图所示的 9 个步骤。
补充工具:帮助大家了解如何在 30 秒左右的时间将任意一张图片转换为有条件格式的Excel 文件
http://think-maths.co.uk/spreadsheet

终结者视角—在电子表格中创建卷积神经网络
背景
我们首先假设,在终结者的大脑中有一个名叫'Sherlock Convolution Holmes'的特殊侦探。他的工作就是仔细查看证据(输入图像)并使用敏锐的眼睛和推演能力(特征检测),预测图片中的人物是谁以此来破案(正确分类图像)。
注:为了减少大家对后面内容的疑惑,首先剧透一点,这篇文章的“男主”其实是Sherlock Convolution Holmes。作者可能是神探夏洛克的粉丝,整篇文章都是围绕Sherlock 是如何破案来展开的。
我们将用电子表格模型来查看图片,分析像素值,并预测它是否是 Elon Musk,Jeff Bezos 或者 Jon Snow,显然这三个人是 Skynet 最大的威胁。用图像化来比喻,CNN就像 Sherlock Holmes。这个过程中会使用到一些数学公式,我们在这里给出了参考链接,方便大家学习。
参考链接:
https://drive.google.com/open?id=1TJXPPQ6Cz-4kVRXTSrbj4u4orcaamtpGvY58yuJbzHk
以下9个步骤中的每个步骤都是这个图像化比喻的一部分。

卷积神经网络体系结构
第一步

▌输入:一张图片就像是成千上万的数字
下面是我们的输入图片,我们是如何对这张照片进行操作的呢?


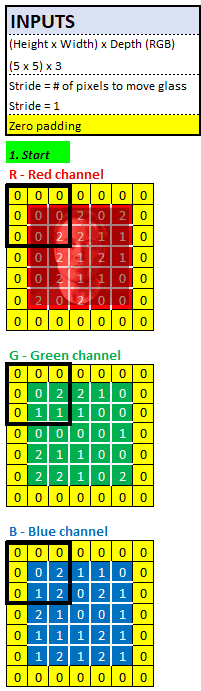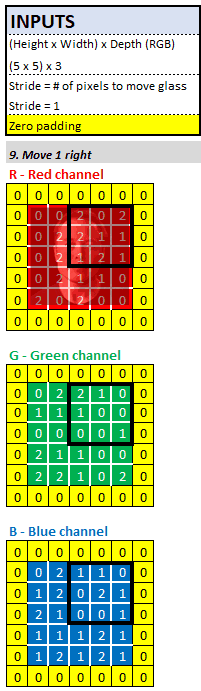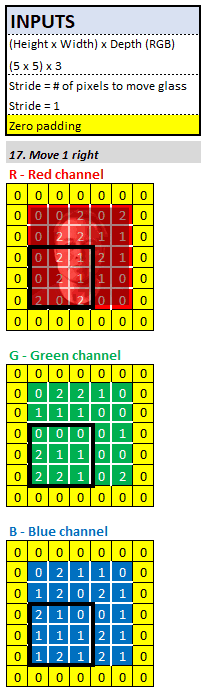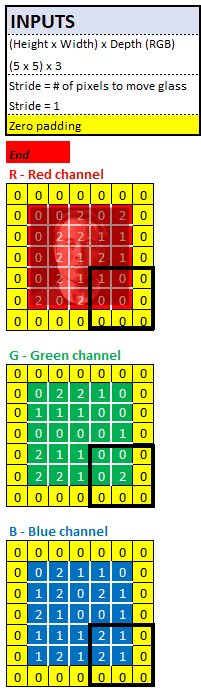
将数码照片看作3个电子表格(1个红色,1个绿色,1个蓝色)堆叠在一起,每个电子表格都是一个数字矩阵。拍摄照片时,相机会测量每个像素的红色,绿色和蓝色光量。然后,按 0-255 的等级对每个像素进行排名,并将它们记录在电子表格中:

在上面的 28x28 图像中,每个像素由 3 行(1个红色,1个蓝色和1个绿色)表示,其值为 0-255。其中像素已根据其值进行了格式化。

没有看到真实的眼睛,看到的只是一堆数字
如果我们将每种颜色分成单独的矩阵,就会得到 3 个 28x28 矩阵,而每个矩阵都是训练神经网络的输入:

模型输入
▌训练概述
在你刚出生的时候并不认识什么是狗。但在你成长的过程中,你的父母会在书中,动画片,现实生活中向你展示狗的照片,最终你可以指着那些四条腿毛茸茸的动物说“这是只狗”。这是由于大脑中数十亿神经元之间的联系变得足够强大,让你可以识别狗。
终结者也是以同样的方式学会谁是 Elon。通过一个监督训练的过程,我们给它展示成千上万张 Elon Musk,Jeff Bezos 和 Jon Snow 的照片。起初,它有三分之一的机会猜中,但就像一个小孩,随着时间的推移这个几率会提高。网络的连接或“权重/偏差”就会随着时间更新,使得它可以基于像素级的输入去预测图片输出。

5个字:平移不变性。让我们来简单解析它一下:
对于计算机视觉,这意味着无论我们把目标移动到哪个位置(平移),它都不会改变目标的内容(不变性)。

平移不变性(还可加上尺度不变性)
无论他在图像中什么位置(平移),什么大小(尺度不变),卷积神经网络经过训练都能识别到 Elon 的特征。CNN 擅长识别图像任何部分的模式,然后将这些模式叠加在一起,以构建更复杂的模式,就像人类一样。
在普通神经网络中,我们将每个单独的像素视为我们模型的输入(而不是3个矩阵),但这忽略了相邻像素是具有特殊的意义和结构。对于 CNN,我们关注彼此相邻的像素组,这允许模型学习像形状,线条等的局部模式。例如,如果 CNN 在黑色圆圈周围看到许多白色像素,它会将此模式识别为眼睛。
为了让 CNN 实现 translation variance,他们必须依靠特征检测,也就是Sherlock Convolution Holmes 。
第二步

▌特征检测:遇见 Sherlock Convolution Holmes
Sherlock 使用放大镜,仔仔细细地检查每一张图像,找到该图像的重要特征或“线索”。然后将这些简单的线条和形状特征堆叠在一起,就可以开始看到像眼睛或鼻子这样的面部特征。

每个卷积层都会包含一堆特征图或相互构建的“线索”。在所有卷积完成过后,他将所有这些线索放在一起,就破解了案件并正确识别出目标。

每个特征图都像是另一个“线索”
网络的每个卷积层都有一组特征图,这些特征图使用分层方式来识别越来越复杂的图案/形状。CNN 使用数字模式识别来确定图像最重要的特征。它使用更多的层将这些模式堆叠在一起,因此可以构建非常复杂的特征图。

让人吃惊的是,CNN 他们可以自己学习到这些特征,而不需要工程师编写代码教他学习什么是2只眼睛,1个鼻子,嘴巴等等。
在这种方式下,工程师更像是建筑师。他们告诉 Sherlock,“我给你 2 个空白特征图(“线索”)的堆栈(“卷积层”),你的工作是分析图片并找到最重要的线索。第一个堆栈包含 16 个特征图(“线索”),第二个堆栈包含64 个特征图.。接下来就可以利用这些侦探技巧去解决问题吧!”
第三步:

为了让 Sherlock 找到案件中的“线索”(即“计算一张特征图”),他需要使用几个工具,我们将一一介绍:
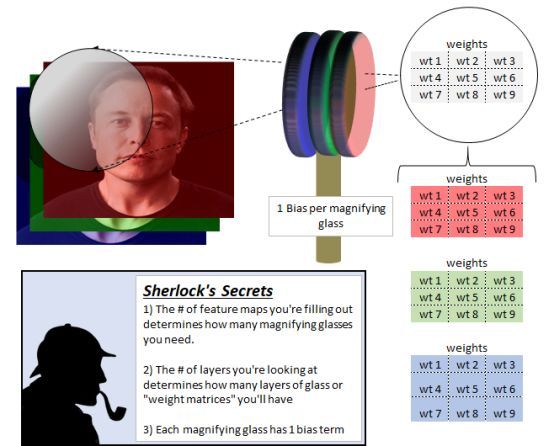
▌Sherlock 的放大镜(滤波器)
Sherlock 毫无疑问非常敏锐且具有极高的洞察能力。但如果没有他的特殊放大镜或“滤波器”,他就无法完成他的工作。因此他使用不同的放大镜来帮助他填充每个空白特征图的细节。 所以,如果他有 16 张特征图,他就会用 16 个放大镜。
每个放大镜由多层玻璃组成,每层玻璃重量不同。玻璃层的数量,也就是我们的“滤波器深度”,总是与观察的神经网络层的深度相匹配。
一开始,Sherlock查 看的输入图像,它有3层,红色,绿色和蓝色。所以,我们的放大镜也有 3 层。当我们构建 CNN时,随着层深度增加,我们的放大镜也会变得更厚。
为了建立 1 个特征图或“线索”,Sherlock 首先取出 1 个放大镜并将其放在输入图像的左上部分。红色玻璃层只能看到红色输入图像,绿色玻璃看到绿色图像,而蓝色玻璃看到的是蓝色图像。
接下来是进行数学计算。
▌卷积数学
我们特征图中的每个像素都是线索的一部分。为了计算每个像素,Sherlock 必须运用一些基本的乘法和加法。
在下面的例子中,我们将使用 5x5x3 的输入图像和 3x3x3 的滤波器,每个像素点需要 27 次乘法:
卷积计算——建立特征地图
让我们放大来看。一个像素由27次乘法组成,下面图片显示了 27次 乘法中的 9 次:
就偏置而言,您可以将其视为每个放大镜的手柄。与权重一样,它是模型的另一个参数,每次训练都会调整这些参数以提高模型的准确性并更新特征图。
滤波器权重——在上面的例子中,将权重保持在1 和 0 是为了计算更方便; 但是,在正常神经网络中,可以使用随机较低的值来初始化权重,如使用(0.01)和(0.1)之间的钟形曲线或正态分布类型方法。

元素乘法—用来计算1条线索
▌步长:移动放大镜
在计算了特征图中的第一个像素后,Sherlock 会怎样移动他的放大镜?
答案就是步长参数。作为神经网络的建筑师/工程师,在 Sherlock 计算特征图下一个像素之前,我们必须告诉他应该向右移动多少像素。在实践中,2 或 3 的步长是最常见的,为了便于计算我们这里设置步长为 1。这意味着 Sherlock 将他的放大镜向右移动 1 个像素,然后再执行与之前相同的卷积计算。
当放大镜到达输入图像的最右边时,他会将放大镜向下 1 个像素并移动到最左边。

▌为什么步长会超过 1?
优点:通过减少计算和缓存,使模型训练速度更快。
缺点:步长大于 1 时,你会因为跳过一些像素从而导致丢失图片的信息,并可能错过一些学习模式。
但是设置步幅为 2 或 3 也是合理的,因为紧邻的像素通常具有相似的值,但是如果它们相距 2-3 个像素,则更有可能是对于特征图/模式更重要的像素值变化。
▌如何防止信息丢失(丢失线索)
为了破解这个案子,Sherlock在一开始的时候就需要很多线索。在上面的例子中,我们采用了一张 5x5x3 图像,也就是 75 位像素的信息(75 = 5 x 5 x 3)。在第一个卷积层后,我们只得到了一个 3x3x2 图像,也就是 18 位像素(18 = 3 x 3 x 2)。这意味着我们丢失了部分证据,这将会让他的搭档John Watson 非常生气。

在 CNN 的前几层中,Sherlock 会看到很多细微的模式,这是一个增加线索的过程。而在后面的层中,可以通过“下采样”的方法来减少线索,Sherlock会将细微的线索堆积起来以便查看更清晰的模式。
▌那么我们如何防止信息丢失呢?
1:填充:我们必须在图像周围进行“填充”来保护犯罪现场。

在我们的例子中,在到达右边缘之前需要移动滤波器 3 次,从上到下都是一样的。这意味着我们得到的输出高度/宽度为 3x3,那我们从左到右时丢失了2 个像素,而从上到下移动时我们又损失了 2 个像素。
为了防止这种信息丢失,通常用零填充原始图像(称为“零填充”或“相同填充”),就像犯罪现场布置的警戒线一样,来保证没有人篡改线索。
在填充之后,如果 Sherlock 再次使用相同的放大镜,那他的 2 个特征图将是 5x5 而不是 3x3。这意味着我们将留下 50 个像素的信息,因为这个卷积的新输出是 5x5x2 = 50。50 像素比 18 像素要好。但是,我们是从 75 像素开始的,所以我们仍然丢失了一些线索。
除此之外我们还能做些什么呢?
2:使用更多的滤波器—通过在卷积层中添加至少 1 个特征图,为 Sherlock提供更多线索
我们模型的特征图或“线索”数量是没有限制,这是一个可以控制的参数。
如果我们将特征图从 2 增加到 3(5x5x2 到 5x5x3),那么总输出像素(75)与输入像素(75)刚好匹配,可以确保没有信息丢失。如果我们将特征图增加到 10,那么就会有更多的信息(250像素= 5 x 5 x 10)让Sherlock 筛选以找到线索。

总之,前几层中的总像素信息通常高于输入图像,是因为我们希望为Sherlock 提供尽可能多的线索/模式。在我们网络的最后几层中,通常做法是下采样得到少量的特征。因为这些层是用来识别图像更明确的模式。
第四步

▌ReLU:非线性模式识别
给 Sherlock 提供充足的信息是非常重要的,但现在是时候进行真正的侦探工作了——非线性模式识别!像识别耳廓或鼻孔等。
到目前为止,Sherlock 已经做了一堆数学来构建特征图,但每个计算都是线性的(取输入像素并对每个像素执行相同的乘法/加法),因此,他只能识别像素的线性模式。
为了在 CNN 中引入非线性,我们使用称为 Relu 的激活函数。从第一个卷积计算我们的特征图之后,激活函数会检查每个值来确认激活状态。如果输入值为负,则输出变为零。如果输入为正,则输出值保持不变。ReLU 的作用类似于开/关,每个特征图的像素值经过 Relu 后,就得到了非线性的模式识别。
回到我们最初的 CNN 示例,我们将在卷积后立即应用 ReLU:
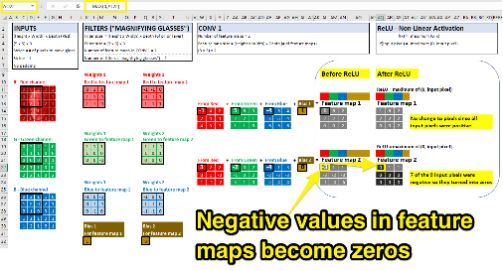
虽然有许多非线性激活函数可用于将非线性引入神经网络(比如 sigmoids,tanh,leakyReLU 等),但 ReLU 是 CNN 中最常用的,因为它们计算效率高,并可以加速训练过程。
第五步

▌Max Pooling:保留关键的少数信息在大脑中
现在,Sherlock 已经有了一些特征图或“线索”,那么他如何确定哪些信息是不相关的细节,哪些是重要的?答案就是最大池化!
Sherlock 认为人脑就像一个记忆宫殿。傻瓜会存储各种各样的信息,最终有用的信息却在杂乱无章中丢失了。而聪明人只存储最重要的信息,这些信息可以帮助他们迅速做出决定。Sherlock 采取的方法就是 Max Pooling,使他只保留最重要的信息,从而可以快速做出决定。

最大池化就像Sherlock Holmes 记忆宫殿
通过最大池化,他可以查看像素的邻域并仅保留“最大”值或“最重要”的证据。
例如,如果他正在观察 2x2 的区域(4个像素),那只保留最高值的像素并丢掉其他 3 个。这种技术使他能够快速学习还有助于归纳出可以存储和记忆未来图像中的线索。
与之前的放大镜滤波器类似,我们还可以控制最大池化的步长和池的大小。在下面的示例中,我们假设步长为 1,最大池化为 2x2:
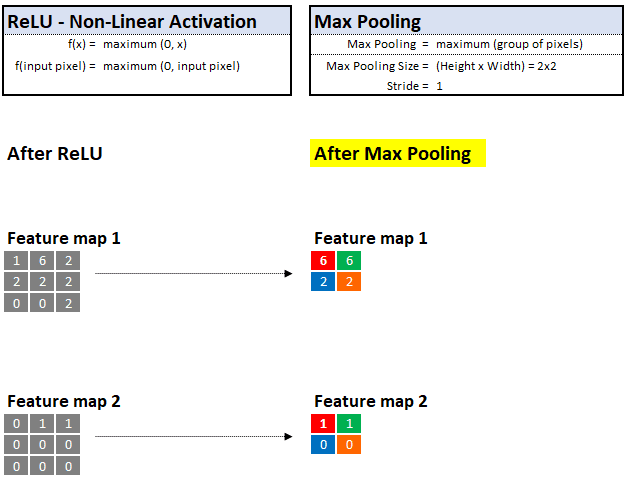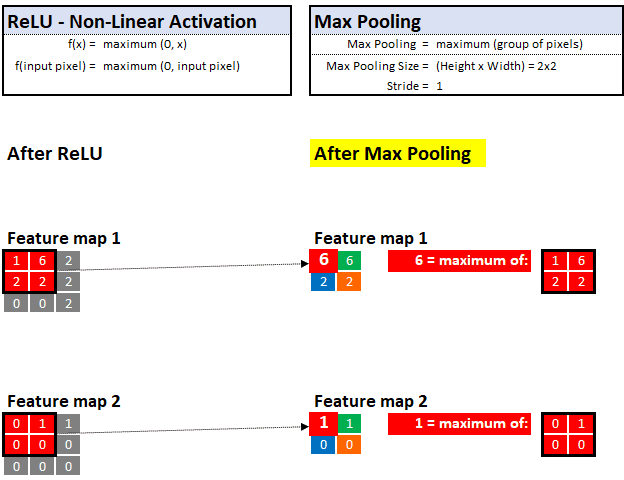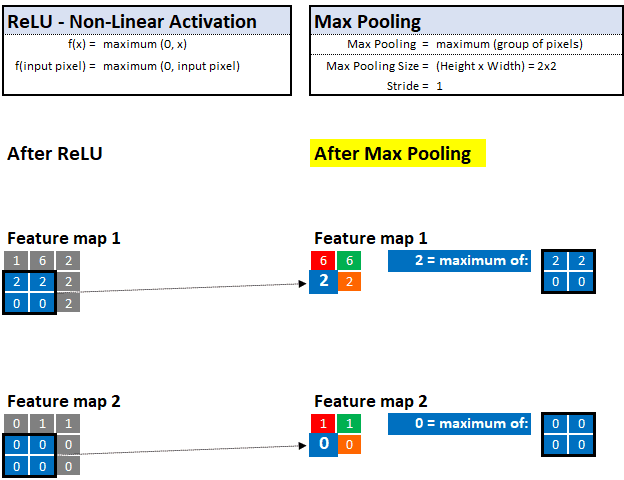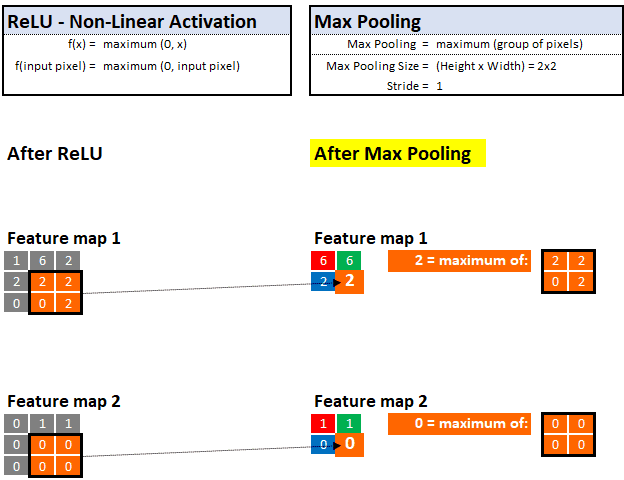
最大池化—在定义的值邻域中选择“最大”值
在最大池化做完之后,我们就完成了 1 轮卷积 / ReLU / 最大池化的过程。
在典型的CNN中,进入分类器之前,我们一般会有几轮卷积 / ReLU / 池的过程。每一轮,我们都会在增加深度的同时挤压高度/宽度,这样我们就不会丢失一些证据。
前面的这 1-5 步,重点就是收集证据,接下来就是 Sherlock 查看所有线索并破案的时候了:

第六步

当 Sherlock训练循环结束时,他有很多零散的线索,然后他需要一个方法可以同时看到全部的线索。其实每条线索都对应一个简单的二维矩阵,但是有成千上万条这样的线索堆积在一起。
现在他必须获得的全部线索都收集并组织起来,以便在法庭上展示给陪审团。

拉平前的特征图
他采用了 Flatten Layer 来完成这项工作(Flatten Layer 常用在从卷积层到全连接层的过渡),简单来说这个技术的做法就是:
下图展示了人眼识别的示例:

回到我们的例子,下面是计算机看到的
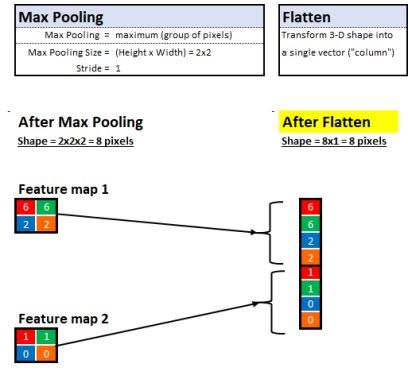
现在Sherlock 已经组织完了他的证据,接下来他需要让陪审团相信他的证据最终都指向同一个嫌疑人。
第七步

在全连接层中,我们将证据与每个嫌疑人相连。换句话说就是我们在展示证据与每个嫌疑人之间的联系。
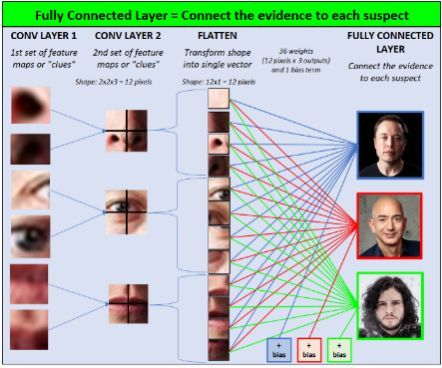
全连接层—连接证据与每个嫌疑人
以下是计算机看到的内容:
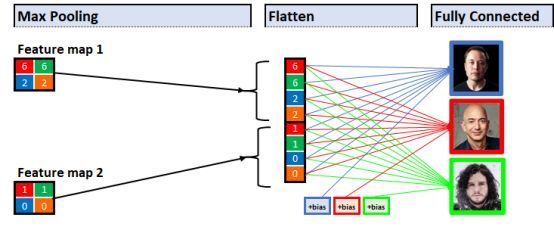
全连接层
在 Flatten Layer 和 3 个输出的每个证据之间是权重和偏差。与网络中的其他权重一样,当我们首次开始训练 CNN 时,这些权重将以随机值初始化,并且随着时间的推移,CNN 会“学习”如何调整这些权重/偏差来得到越来越准确的预测结果。
现在是 Sherlock 破解案件的时候了!
第八步

在 CNN 的图像分类器阶段,模型的预测结果就是最高分数的输出。
这个评分函数有两部分:
▌第1部分:Logits ——逻辑分数
每个输出的 logit 分数是基本的线性函数:
Logit分数 =(证据x权重)+ 偏差
每一个证据乘以连接证据与输出的权重。所有这些乘法都加在一起,然后在末尾添加一个偏差项,得到的最高分就是模型的猜测。
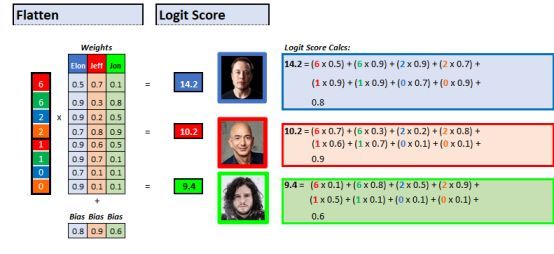
Logit 分数计算
为什么得到了最高分数却不是最终结果? 有 2 个直观的原因:
Sherlock 的目标是让他的预测尽可能接近 1,以此获得正确的输出。
▌第2部分:Softmax——Sherlock 的置信度加权概率分数
2.1.Sherlock 的置信水平:
为了找到 Sherlock 的置信水平,我们取字母 e(等于2.71828)为底,并计算 logit 得分做幂运算。让高分值越高,而低分值越低。
在进行幂运算中还保证了没有负分数。由于 logit 分数“可能”为负数,所以下图是置信度曲线:
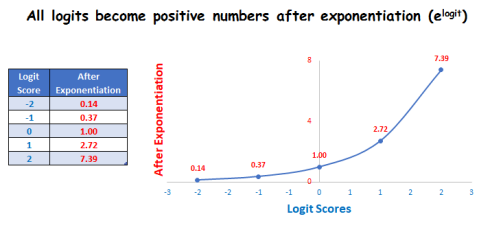
置信度曲线
2.2. Sherlock 的置信加权概率:
为了找到置信加权概率,我们将每个输出的置信度量除以所有置信度得分的总和,就可以得到每个输出图像的概率,所有这些加起来为 1。用 Excel 示例如下:
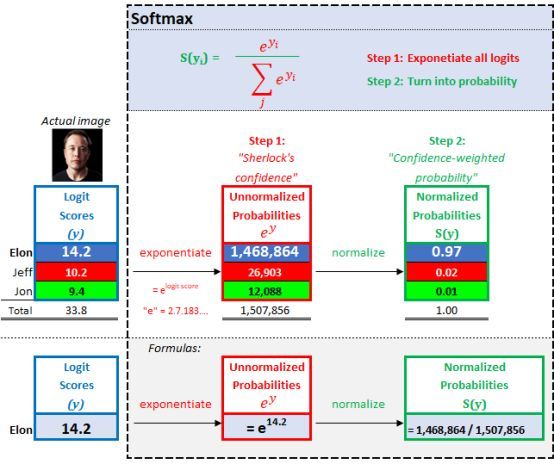
Softmax
这个 softmax 分类器非常直观。Sherlock 认为,终结者看到的照片是 Elon Musk 的机率是97%(置信度加权)。我们模型的最后一步是计算损失。损失值告诉我们侦探 Sherlock 的辨识能力究竟有多好(或者多差)。
第九步

每个神经网络都有一个损失函数,我们将预测结果与实际情况进行比较。当训练 CNN 时,随着网络权重/偏差的调整,我们的预测结果会得到改善(Sherlock的侦探技能变得更好)。
CNN 最常用的损失函数是交叉熵损失函数。在 Google 上搜索交叉熵会出现很多希腊字母的解释,很容易混淆。尽管描述各不相同,但它们在机器学习的背景下都是相同的,我们将覆盖下面最常见的3个。
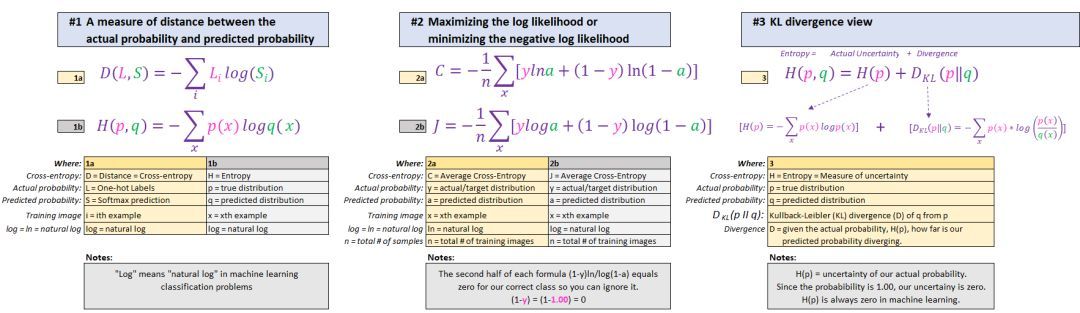
以上得到的答案都相同!存在 3 种不同的解释
▌解释 1:实际概率与预测概率之间距离的度量
直觉是,如果我们的预测概率接近 1,则我们的损失接近 0。如果我们的预测接近于 0,那么将受到严厉的惩罚。目标是最小化预测结果(Elon,0.97)与实际概率(1.00)之间的“距离”。
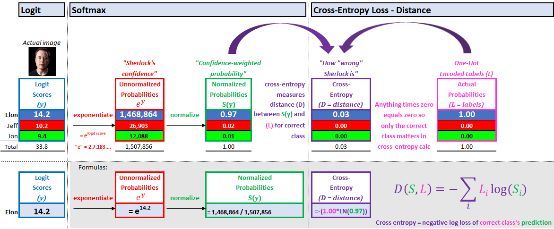
交叉熵 1.距离解释
▌解释 2:最大化对数似然或最小化负对数似然
在 CNN 中,“log” 实际上意味着“自然对数(ln)”,它是在 softmax 的步骤1中完成的“指数/置信度”的倒数。
我们不是用实际概率(1.00)减去预测概率(0.97)来计算损失,而是通过log 来计算损失,当 Sherlook 的预测结果离 1 越远的时候,损失是指数级增长的。
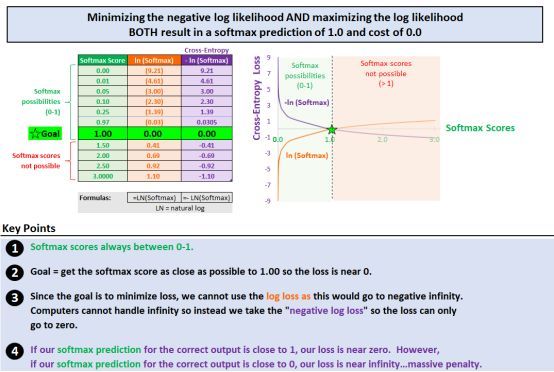
交叉熵 2.对数损失解释
▌解释 3:KL 散度(Kullback–Leibler divergence)
KL 散度是用来衡量预测概率(softmax得分)与实际概率的差异程度。
该公式分为两部分:
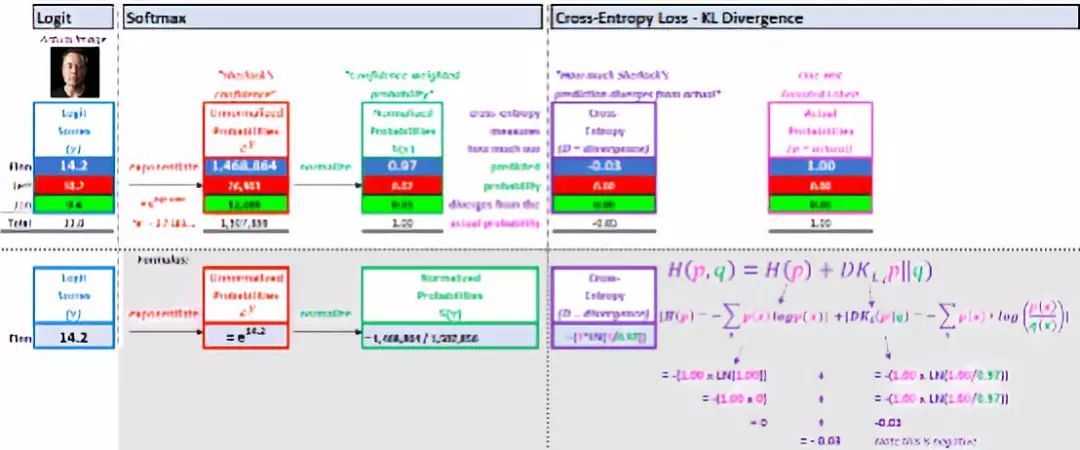
交叉熵 3.KL散度解释
总结
在侦探 Sherlock Holmes 的帮助下,我们给了终结者一双眼睛,所以他现在有能力寻找并摧毁自由世界的保护者 Elon Musk。(Sorry Elon!)
虽然,我们只训练终结者来辨别 Elon,Jeff 和 Jon,但是 Skynet 拥有无限多的资源和训练图像,它可以利用我们构建的网络去训练终结者来识别世间万物!

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27






