实时计算 流数据处理系统简单分析_数据分析师
一. 实时计算的概念
实时计算一般都是针对海量数据进行的,一般要求为秒级。实时计算主要分为两块:数据的实时入库、数据的实时计算。
主要应用的场景:
1) 数据源是实时的不间断的,要求用户的响应时间也是实时的(比如对于大型网站的流式数据:网站的访问PV/UV、用户访问了什么内容、搜索了什么内容等,实时的数据计算和分析可以动态实时地刷新用户访问数据,展示网站实时流量的变化情况,分析每天各小时的流量和用户分布情况)
2) 数据量大且无法或没必要预算,但要求对用户的响应时间是实时的。比如说:
昨天来自每个省份不同性别的访问量分布,昨天来自每个省份不同性别不同年龄不同职业不同名族的访问量分布。
二. 实时计算的相关技术
主要分为三个阶段(大多是日志流):
数据的产生与收集阶段、传输与分析处理阶段、存储对对外提供服务阶段
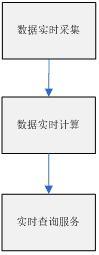
下面具体针对上面三个阶段详细介绍下
1)数据实时采集:
需求:功能上保证可以完整的收集到所有日志数据,为实时应用提供实时数据;响应时间上要保证实时性、低延迟在1秒左右;配置简单,部署容易;系统稳定可靠等。
目前的产品:Facebook的Scribe、LinkedIn的Kafka、Cloudera的Flume,淘宝开源的TimeTunnel、Hadoop的Chukwa等,均可以满足每秒数百MB的日志数据采集和传输需求。他们都是开源项目。
2)数据实时计算
在流数据不断变化的运动过程中实时地进行分析,捕捉到可能对用户有用的信息,并把结果发送出去。

实时计算目前的主流产品:
-
Yahoo的S4:S4是一个通用的、分布式的、可扩展的、分区容错的、可插拔的流式系统,Yahoo开发S4系统,主要是为了解决:搜索广告的展现、处理用户的点击反馈。
-
Twitter的Storm:是一个分布式的、容错的实时计算系统。可用于处理消息和更新数据库(流处理),在数据流上进行持续查询,并以流的形式返回结果到客户端(持续计算),并行化一个类似实时查询的热点查询(分布式的RPC)。
-
Facebook 的Puma:Facebook使用puma和HBase相结合来处理实时数据,另外Facebook发表一篇利用HBase/Hadoop进行实时数据处理的论文(ApacheHadoop Goes Realtime at Facebook),通过一些实时性改造,让批处理计算平台也具备实时计算的能力。
关于这三个产品的具体介绍架构分析:http://www.kuqin.com/system-analysis/20120111/317322.html
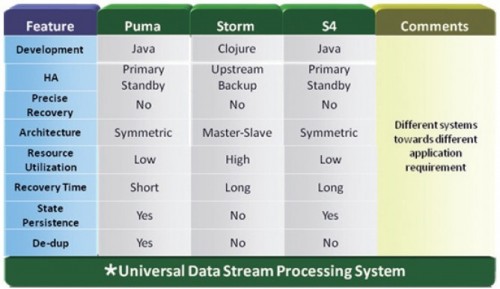
下面是S4和Storm的详细对比

其他的产品:
早期的:IBM的Stream Base、 Borealis、Hstreaming、Esper
4. 淘宝的实时计算、流式处理
1) 银河流数据处理平台:通用的流数据实时计算系统,以实时数据产出的低延迟、高吞吐和复用性为初衷和目标,采用actor模型构建分布式流数据计算框架(底层基于akka),功能易扩展、部分容错、数据和状态可监控。银河具有处理实时流数据(如TimeTunnel收集的实时数据)和静态数据(如本地文件、HDFS文件)的能力,能够提供灵活的实时数据输出,并提供自定义的数据输出接口以便扩展实时计算能力。银河目前主要是为魔方提供实时的交易、浏览和搜索日志等数据的实时计算和分析。
2) 基于Storm的流式处理,统计计算、持续计算、实时消息处理。
在淘宝,Storm被广泛用来进行实时日志处理,出现在实时统计、实时风控、实时推荐等场景中。一般来说,我们从类kafka的metaQ或者基于HBase的timetunnel中读取实时日志消息,经过一系列处理,最终将处理结果写入到一个分布式存储中,提供给应用程序访问。我们每天的实时消息量从几百万到几十亿不等,数据总量达到TB级。对于我们来说,Storm往往会配合分布式存储服务一起使用。在我们正在进行的个性化搜索实时分析项目中,就使用了timetunnel +HBase + Storm + UPS的架构,每天处理几十亿的用户日志信息,从用户行为发生到完成分析延迟在秒级。
3) 利用Habase实现的Online应用
4)实时查询服务
-
半内存:使用Redis、Memcache、MongoDB、BerkeleyDB等内存数据库提供数据实时查询服务,由这些系统进行持久化操作。
-
全磁盘:使用HBase等以分布式文件系统(HDFS)为基础的NoSQL数据库,对于key-value引擎,关键是设计好key的分布。
-
全内存:直接提供数据读取服务,定期dump到磁盘或数据库进行持久化。
关于实时计算流数据分析应用举例:
对于电子商务网站上的店铺:
1) 实时展示一个店铺的到访顾客流水信息,包括访问时间、访客姓名、访客地理位置、访客IP、访客正在访问的页面等信息;
2) 显示某个到访顾客的所有历史来访记录,同时实时跟踪显示某个访客在一个店铺正在访问的页面等信息;
3) 支持根据访客地理位置、访问页面、访问时间等多种维度下的实时查询与分析。
下面对Storm详细介绍下:
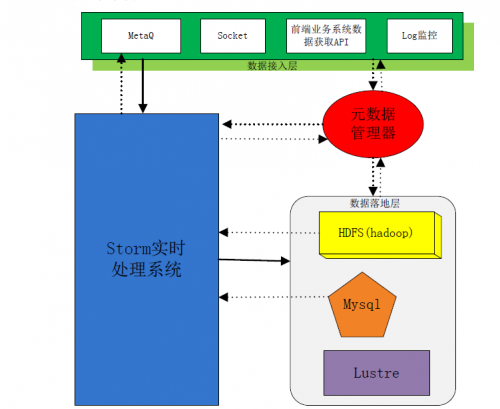
整体架构图
整个数据处理流程包括四部分:
第一部分是数据接入该部分从前端业务系统获取数据。
第二部分是最重要的Storm 实时处理部分,数据从接入层接入,经过实时处理后传入数据落地层;
第三部分为数据落地层,该部分指定了数据的落地方式;
第四部分元数据管理器。
数据接入层
该部分有多种数据收集方式,包括使用消息队列(MetaQ),直接通过网络Socket传输数据,前端业务系统专有数据采集API,对Log问价定时监控。(注:有时候我们的数据源是已经保存下来的log文件,那Spout就必须监控Log文件的变化,及时将变化部分的数据提取写入Storm中,这很难做到完全实时性。)
Storm实时处理层
首先我们通过一个 Storm 和Hadoop的对比来了解Storm中的基本概念。

(Storm关注的是数据多次处理一次写入,而Hadoop关注的是数据一次写入,多次处理使用(查询)。Storm系统运行起来后是持续不断的,而Hadoop往往只是在业务需要时调用数据。两者关注及应用的方向不一样。)
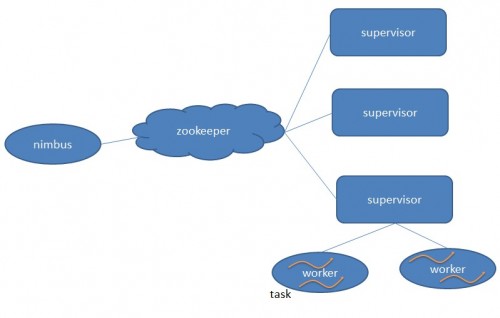
1. Nimbus:负责资源分配和任务调度。
2. Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。
3. Worker:运行具体处理组件逻辑的进程。
4. Task:worker中每一个spout/bolt的线程称为一个task. 在Storm0.8之后,task不再与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。
具体业务需求:条件过滤、中间值计算、求topN、推荐系统、分布式RPC、热度统计
数据落地层:
MetaQ
如图架构所示,Storm与MetaQ是有一条虚线相连的,部分数据在经过实时处理之后需要写入MetaQ之中,因为后端业务系统需要从MetaQ中获取数据。这严格来说不算是数据落地,因为数据没有实实在在写入磁盘中持久化。
Mysql
数据量不是非常大的情况下可以使用Mysql作为数据落地的存储对象。Mysql对数据后续处理也是比较方便的,且网络上对Mysql的操作也是比较多的,在开发上代价比较小,适合中小量数据存储。
HDFS
HDFS及基于Hadoop的分布式文件系统。许多日志分析系统都是基于HDFS搭建出来的,所以开发Storm与HDFS的数据落地接口将很有必要。例如将大批量数据实时处理之后存入Hive中,提供给后端业务系统进行处理,例如日志分析,数据挖掘等等。
Lustre
Lustre作为数据落地的应用场景是,数据量很大,且处理后目的是作为归档处理。这种情形,Lustre能够为数据提供一个比较大(相当大)的数据目录,用于数据归档保存。
元数据管理器
元数据管理器的设计目的是,整个系统需要一个统一协调的组件,指导前端业务系统的数据写入,通知实时处理部分数据类型及其他数据描述,及指导数据如何落地。元数据管理器贯通整个系统,是比较重要的组成部分。元数据设计可以使用mysql存储元数据信息,结合缓存机制开源软件设计而成。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330