近年来,随着数据科学的逐步发展,Python语言的使用率也越来越高,不仅可以做数据处理,网页开发,更是数据科学、机器学习、深度学习等从业者的首选语言。
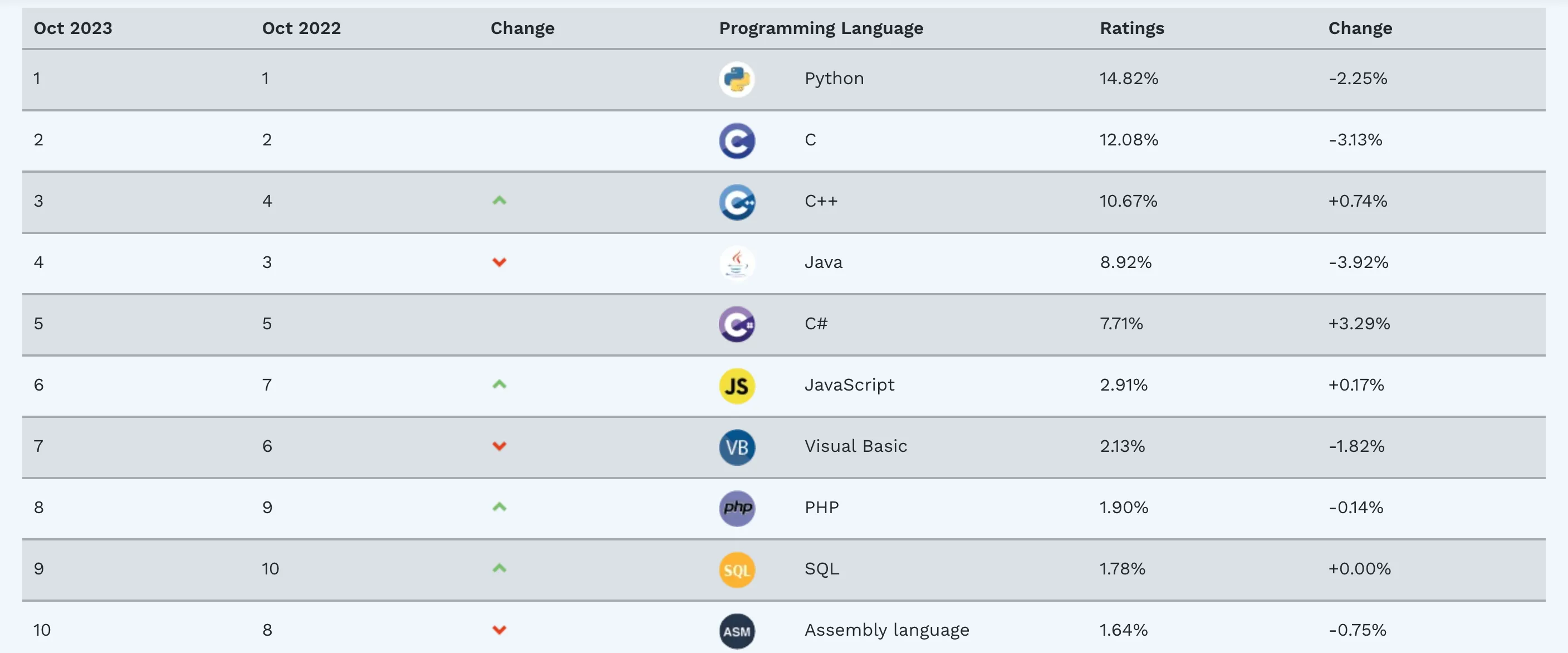
“工欲善其事,必先利其器。” 要做好数据分析,离不开一个好的编程工具,不论是从Python的语法之简洁、开发之高效,招聘岗位之热门来说,Python都是数据科学从业者需要掌握的一门语言。
但一直以来,人们却误以为“学会Python”是件很难的事情。
实则不然,这恰恰是我们选择学Python的理由之一。
事实证明,Python人人皆能学会——千万别不信。
老少皆宜 —— 也就是说,“只要你愿意”,根本没有年龄差异。十二岁的孩子可以学;十八岁的大学生可以学;在职工作人员可以学…… 就算你已经退休了,想学就能学,谁也拦不住你。
不分性别,男性可以学,女性同样可以学,性别差异在这里完全不存在。
不分国界,更没有区域差异 —— 互联网的恩惠在于,你在北京、纽约也好,老虎沟、门头沟也罢,在这个领域里同样完全没有任何具体差异。
尤其是在中国。现状是,中国的人口密度极高,优质教育资源的确就是稀缺…… 但在计算机科学领域,所有的所谓 “优质教育资源” 事实上完全没有任何独特的竞争力 —— 编程领域,实际上是当今世上极为罕见的 “教育机会公平之地”。又不仅在中国如此,事实上,在全球范围内也都是如此。
多年以前,不识字的人被称为文盲……
后来,不识英文,也是文盲。人们发现很多科学文献的主导语言都是英语……
再后来,不会计算机的也算是文盲,因为不会计算机基本操作,很多工作的效率很低下,浪费了很多时间……
近些年,不会数据分析的,也算做文盲了,互联网高速发展,用户行为数据越来越多,
你作为一个个体,每天都在产生各种各样的数据,然后时时刻刻都在被别人使用着、分析着…… 然而你自己却全然没有数据分析能力,甚至不知道这事很重要,是不是感觉很可怕?你看看周边那么多人,有多大的比例想过这事?反正那些天天看机器算法生成的信息流的人好像就是全然不在意自己正在被支配……
怎么办?学呗,学点编程罢 —— 巧了,这还真是个正常人都能学会的技能。
为便于上手学习,在开始前再做两点补充
安装开发工具 众所周知,在数据分析相关的编程语言中,有三个重中之重:Python、R、Julia 俗称数据科学三剑客。如果有一个工具能集中编写这三者的代码,为大家省去各种安装开发工具的时间,那简直太好不过了,于是jupyter应运而生,作为“工具的工具”而备受数据科学从业者的青睐!
Jupyter的名字就很好地诠释了这一发集大成的思路,它是 Julia、Python、R 语言的组合,拼写相近于木星(Jupiter),而且现在支持的语言也远超这三种了。
所以需要读者自行下载安装好Anaconda提供的Jupyter notebook或者jupyter lab,以便于更好地运行本文相关代码。安装好后可以直接运行Python,因为里面已经帮你集成好了环境。
文章阅读指南 虽然笔者力求极简,带你入门Python,但你依然有可能遇到问题,因为编程语言的知识体系有一个特点,知识点之间不是线性的从前往后,而是呈网状的,经常出现前置引用。所以很多时候可能不经意间就用的是后面的知识点,这是不可避免的,遇到这种情况,注定要反复阅读若干遍,之所以取名叫极简入门,这一部分的目标就在与并不是让你立马学会就去写代码,而是让你脱盲……
好了,接下来,与大家一起开始我们的Python旋风之旅,沿用之前《极简统计学入门》、《SQL数据分析极简入门》的“MVP”思路,用三节的内容梳理一下Python数据分析的核心内容。整个系列框架如下:
第1节 Python基础知识
第2节 Pandas基础知识
第3节 Pandas基础知识
如果你接触过不同编程语言就会发现,任何编程语言的学习,都离不开3个最基本的核心要素,数据类型、流程控制、函数
数据类型是用来描述数据的性质和特征的,它决定了数据在计算和处理过程中的行为和规则。常见的数据类型包括整数、浮点数、字符串、日期等。简而言之,就是你将要操作的东西具有什么样的特点。
流程控制是指通过条件判断和循环等方式,控制程序按照一定的顺序执行不同的操作步骤。它决定了数据的处理流程,包括判断条件、循环次数、分支选择等。简而言之,就是你要操作这个东西的基本流程是什么。
函数是一段预先定义好的代码,用于执行特定的操作或计算。它接受输入参数,并返回一个结果。函数可以用来对数据进行各种计算、转换、筛选等操作,以满足特定的需求。简而言之,就是你要怎么样才能可复用地操作这一类东西。
我们来看第一个核心要素:数据类型
Python中的数据类型有很多,如果我们按照大类来分,可以分为三大数据类型:
整型 int
a = 2022 # 把2022赋值给a
type(a) # 查看数据类型:<class 'int'>
int
浮点型 float
b = -21.9
type(b) # 数据类型:<class 'float'>
float
复数型 complex
c = 11 + 36j
type(c) # 数据类型:<class 'complex'>
complex
布尔型 bool
d = True
type(d) # 数据类型:<class 'bool'>
bool
str_a = "Certified_Data_Analyst" # 创建字符串:"Certified_Data_Analyst"
type(str_a) # 数据类型:<class 'str'>
str
len(str_a) # 字符串长度:
22
str_a[0] # 输出字符串第1个字符
'C'
str_a[10] # 输出字符串第11个字符
'D'
str_a[15] # 输出字符串第16个字符
'A'
str_a[:9] # 输出字符串第1到9个字符
'Certified'
str_a[10:14] # 输出从第11到14个的字符
'Data'
str_a[15:] # 输出从第15个后的所有字符
'Analyst'
str_a * 2 # 输出字符串2次
'Certified_Data_AnalystCertified_Data_Analyst'
str_a+"_Exam" # 连接字符串
'Certified_Data_Analyst_Exam'
str_a.upper() # 转换为大写
'CERTIFIED_DATA_ANALYST'
str_a.lower() # 转换为小写
'certified_data_analyst'
int("1024") # 字符串转数字:1024
1024
str(3.14) # 数字转字符串:'3.14'
'3.14'
"Certified_Data_Analyst".split("_") # 分隔符拆分字符串
['Certified', 'Data', 'Analyst']
"Certified_Data_Analyst".replace("_", " ") # 替换字符串"_"为" "
'Certified Data Analyst'
"7".zfill(3) # 左边补0
'007'
可以容纳多个元素的的对象叫做容器,这个概念比较抽象,你可以这么理解,容器用来存放不同的元素,根据存放特点的不同,常见的容器有以下几种:list(列表)、tuple(元组)、dict(字典)、set(集合)
用中括号[]可以创建一个list变量
[2,3,5,7]
[2, 3, 5, 7]
用圆括号()可以创建一个tuple变量
(2,3,5,7)
(2, 3, 5, 7)
用花括号{}可以创建一个集合变量
{2,3,5,7}
{2, 3, 5, 7}
用花括号{}和冒号:,可以创建一个字典变量
{'a':2,'b':3,'c':5,'d':7}
{'a': 2, 'b': 3, 'c': 5, 'd': 7}
分支
举例说明,我们给x赋值-10,然后通过一个分支做判断,当x大于零时候输出"x是正数",当x小于零的时候输出"x是负数",其他情况下输出"x是零"
x = -10
if x > 0:
print("x是正数")
elif x < 0:
print("x是负数")
else:
print("x是零")
x是负数
循环
举例说明for循环,用for循环来迭代从1到5的数字,并将每个数字打印出来
# for循环
for i in range(1, 6):
print(i)
1
2
3
4
5
首先,range(1, 6)函数生成一个序列,从1到5(不包括6)。
然后,for循环使用变量i来迭代这个序列中的每个元素。
在每次迭代中,print(i)语句将当前的i值打印出来。
再举例说明while循环:用while循环迭代从1到10的数字,并将每个数字打印出来
# while循环
i = 1
while i <= 10:
print(i)
i += 1
if i == 6:
break
1
20
3
4
5
首先,将i初始化为1。
然后,while循环将在i小于或等于10时执行。在每次循环中,print(i)语句将当前的i值打印出来。
接下来,i += 1语句将i的值递增。在每次循环中,if i == 6: break语句将检查i的值是否等于6。如果是,则使用break语句终止循环。
Python提供了许多常用函数,这部分内容数据分析最基础的内容,有部分函数在Python内置库就已经自带
常用函数:
abs(x) # 返回x的绝对值。
round(x) # 返回最接近x的整数。如果有两个整数与x距离相等,将返回偶数。
pow(x, y) # 返回x的y次方。
sqrt(x) # 返回x的算术平方根。
max(x1, x2, ...) # 返回一组数中的最大值。
min(x1, x2, ...) # 返回一组数中的最小值。
sum([x1,x2,...]) # 返回可迭代对象中所有元素的和。
也有一些是来自于math库,我们需要用from math import *来引入math库,然后才能调用里面的函数。这个过程就好比你要使用一个工具箱里面的工具,必须先找到工具箱。通过使用这些数学函数,可以进行各种数学计算和数据处理操作。
常用数学函数
# 数学运算函数
from math import *
sqrt(x) #x的算术平方根
log(x) #自然对数
log2(x) #以2为底的常用对数
log10(x) #以10为底的常用对数
exp(x) #x的e次幂
modf(x) #返回x的⼩数部分和整数部分
floor(x) #对x向下取值整
ceil(x) #对x向上取整
divmod(x,y) #接受两个数字,返回商和余数的元组(x//y , x%y)# 三角函数
sin(x) #x的正弦值
cos(x) #x的余弦值
tan(x) #x的正切值
asin(x) #x的反正弦值
acos(x) #x的反余弦值
atan(x) #x的反正切值# 排列组合函数
# from itertools import *
product() #序列中的元素进行排列, 相当于使用嵌套循环组合
permutations(p[, r]) #从序列p中取出r个元素的组成全排列
combinations(p, r) #从序列p中取出r个元素组成全组合,元素不允许重复
combinations_with_replacement(p, r) #从序列p中取出r个元素组成全组合,允许重复# 简单统计函数 pandas
describe() #描述性统计
count() #非空观测数量
sum() #所有值之和
mean() #平均值
median() #中位数
mode() #一组数的众数
std() #标准差
var() #方差
min() #所有值中的最小值
max() #所有值中的最大值
abs() #绝对值
prod() #数组元素的乘积
corr() #相关系数矩阵
cov() #协方差矩阵# 排序函数
sort() #没有返回值,会对列表进行原地排序
sorted() #需要用一个变量进行接收,不会修改原有列表# 集合运算符号和函数
& #交集
| #并集
- #差集
^ #异或集(不相交的部分)
intersection() #交集
union() #并集
difference() #补集
symmetric_difference() #异或集(不相交的部分)
isdisjoint() #两集合有无相同元素
issubset() #是不是子集
issuperset() #是不是超集# 缺失值处理(Pandas)
np.nan (Not a Number) #空值
None #缺失值
pd.NaT #时间格式的空值# 判断缺失值
isnull()/isna() #断Series或DataFrame中是否包含空值
notnull() #与isnull()结果互为取反
isin() #判断Series或DataFrame中是否包含某些值
dropna() #删除Series或DataFrame中的空值
fillna() #填充Series或DataFrame中的空值
ffill()/pad() #用缺失值的前一个值填充
bfill()/backfill() #用缺失值的后一个值填充
replace() #替换Series或DataFrame中的指定值
自定义函数是一种在Python中自行定义的可重复使用代码块的方法。通过定义自己的函数,可以将一系列操作放在一个函数中,并在需要时多次调用该函数。
举例说明,如何创建和调用一个自定义函数:
def linear(x):
y = 2*x + 4
return y
在上面的例子中,我们用def linear(x): 定义了一个名为linear的函数,该函数接收一个参数x。
然后函数体内计算了一个y值,它是x的两倍加上4。
这样,我们调用linea函数的时候,并传入一个参数x时,函数将返回计算得到的y值。例如,如果我们调用linear(3),函数将返回10,因为2*3 + 4 = 10。
可以根据具体的需求来编写自定义函数,并在程序中调用它们。
再看一个稍微复杂一点的例子(PS:建议初学者先跳过这个例子)
# 斐波那契数列(通过迭代方法实现)
def fib(n):
n1=1;n2=1;n3=1
if n<1:
print('输入有误!')
return 0
else:
while (n-2) > 0 :
n3 = n2 + n1
n1 = n2
n2 = n3
n -= 1
return n3
result = fib(35)
result
9227465
# 斐波那契数列(通过递归方法实现)
def fib(n):
if n < 1:
print('输入有误!')
return -1
elif n == 1 or n == 2:
return 1
else:
return fib(n-1) + fib(n-2)
result = fib(35)
result
9227465
# 斐波那契数列(通过矩阵方法实现)
import numpy as np
def dotx(a,n):
for i in range(1,n+1):
if i == 1:
b = a
else :
b = np.dot(a,b)
return b
def fib(n):
a = np.array([[1,1],[1,0]])
r = dotx(a,n)
return r[0,1]
result = fib(35)
result
9227465
下一节 《第2节 Pandas简介》
这里分享一个你一定用得到的小程序——CDA数据分析师考试小程序。 它是专为CDA数据分析认证考试报考打造的一款小程序。可以帮你快速报名考试、查成绩、查证书、查积分,通过该小程序,考生可以享受更便捷的服务。 扫码加入CDA小程序,与圈内考生一同学习、交流、进步!


数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27TensorFlow Datasets(TFDS)是一个用于下载、管理和预处理机器学习数据集的库。它提供了易于使用的API,允许用户从现有集合中 ...
2025-03-26"不谋全局者,不足谋一域。"在数据驱动的商业时代,战略级数据分析能力已成为职场核心竞争力。《CDA二级教材:商业策略数据分析 ...
2025-03-26当你在某宝刷到【猜你喜欢】时,当抖音精准推来你的梦中情猫时,当美团外卖弹窗刚好是你想吃的火锅店…… 恭喜你,你正在被用户 ...
2025-03-26






