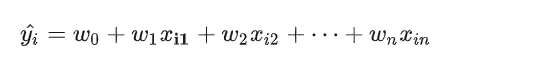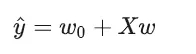真正的数据分析大神是什么样的呢?有人认为他们能轻松驾驭各种分析工具,能够从海量数据中找到潜在关联,或者一眼识别报告中的数据异常,甚至写出经典的数据分析报告。其实,成为数据大神的关键在于提升数据敏感度。
数据敏感度就是快速洞察数据与业务之间的联系。比如,走进一家餐厅,普通人可能只看到“生意火爆”,但数据专家会分析客流量、客单价等,评估盈利能力。掌握这些技能需要不断地实践与训练。想提高数据敏感度?赶紧往下看~
掌握核心概念:学习均值、方差、标准差、分布类型(正态分布、二项分布等)以及相关性和因果关系等基本统计概念。
选择一两种工具:从常用的数据分析工具中选择,如Excel、R或Python,专注于深入学习。Python特别受欢迎,因为其库(如Pandas、NumPy)强大且易于使用。
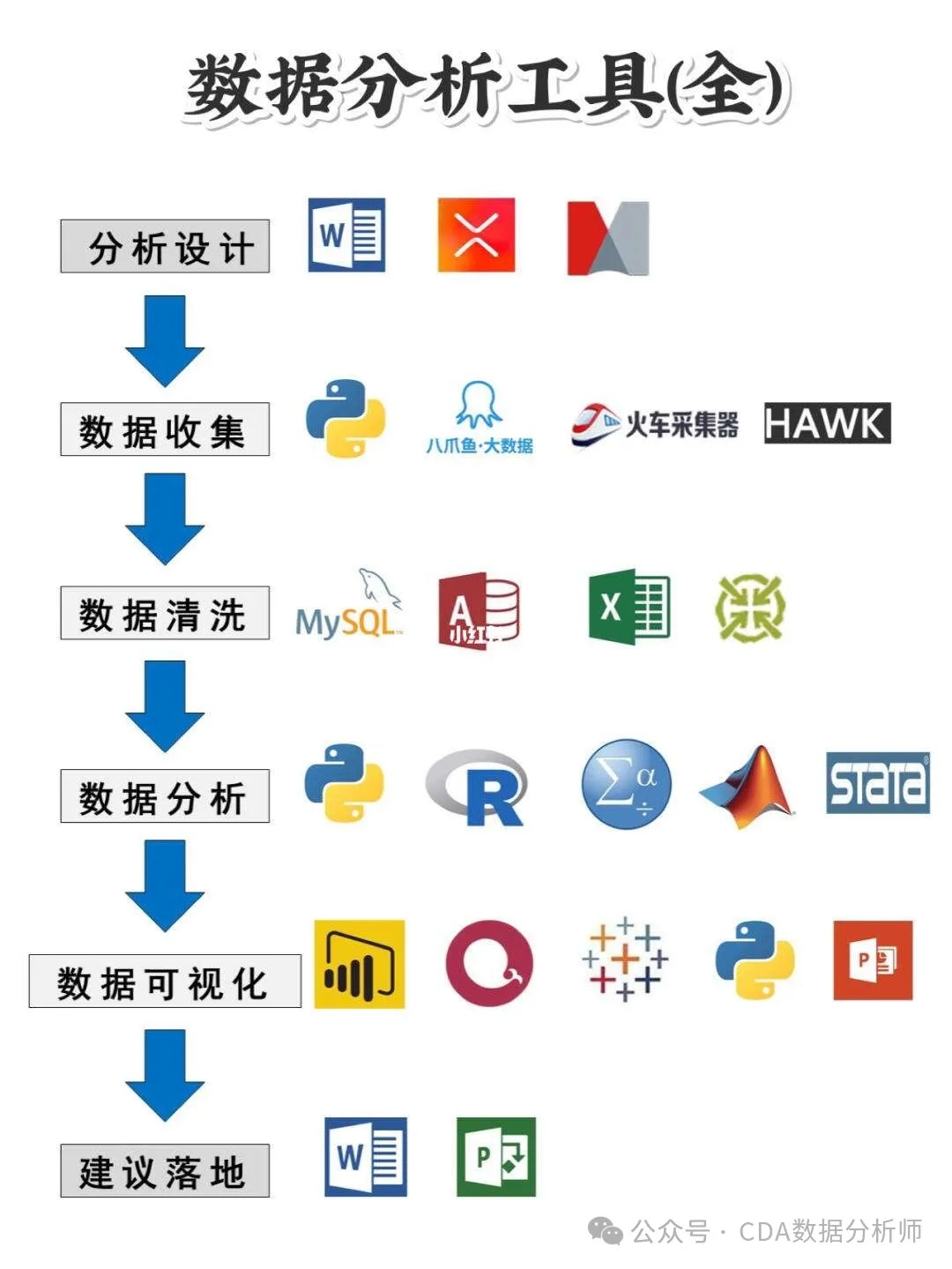
学习数据可视化技术:通过图表(如折线图、柱状图、散点图等)可视化数据,有助于更直观地理解数据的模式和趋势。
使用可视化工具:熟悉如Tableau、Power BI等工具,能够快速将数据转化为可视化信息,从而提高数据敏感度。
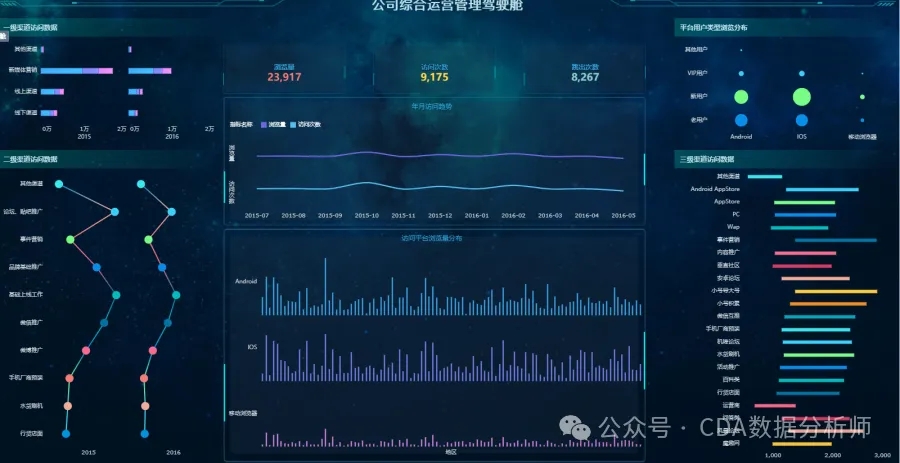
分析知名企业如何利用数据驱动决策,通过实际案例学习数据的应用。
一、瑞幸从数字造假到逆袭翻盘
8月《黑神话:悟空》受到了包括央媒在内的广泛肯定,显示出中国数字经济和虚拟经济的积极市场前景。瑞幸迅速开展联名活动,继去年的酱香拿铁后再次破圈。瑞幸咖啡在经历财务造假丑闻后,退市之后还能维持运营并实现盈利,这一现象在企业中较为罕见,作为一名财务人员,财务分析不仅要关注利润和现金流,更要深入理解数字背后的含义,这是财务分析的深层次要求。分析瑞幸咖啡的案例有助于探讨数字管理的重要性。
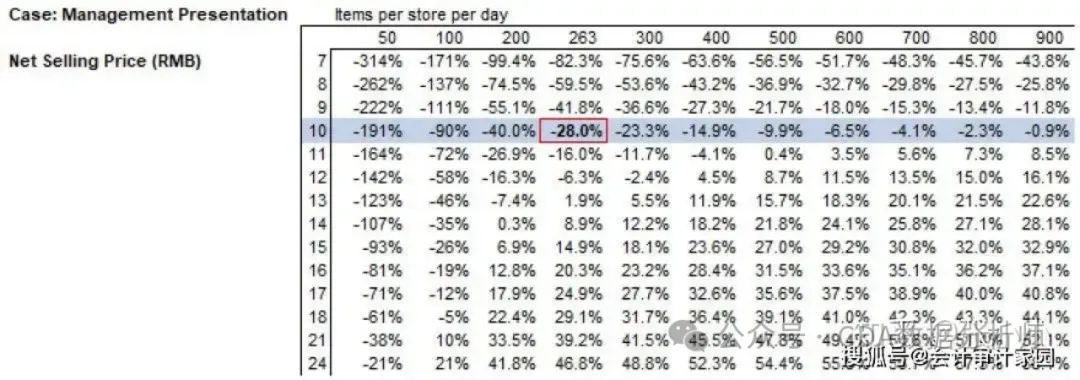
定价9.9,瑞幸还有得赚么?
为什么客单价很重要?因为快消品包括我们的生活日用品,包括一些零售副食商品之类的,它可替代性太强了。有10块钱一杯的瑞幸,就不会有人去喝30块钱一杯的星巴克。所以价格敏感系数对于快消品来讲它是至关重要的,如果要给快消品的一个界定的话,它就是低价倾销模式来抢占市场。
瑞幸在商店赢利能力的敏感性分析中披露,单店赢利的关键因素在每家店每天卖出400件商品的情况下,每件售价16元,单店利润会达到28.4%;但如果按报告中的数据,在每店每天销售263件商品,净售价9.97元的实际情况下,按照管理层的介绍,门店层面亏损为28.0%。如果按9.97元的售价要实现盈利,每家店每天要卖800杯咖啡才行,不然就得把售价提高到13元。这突出体现了数据清洗的重要意义。
二、强大的数据运营能力
美国退市并没有让瑞幸沉浸在污点中,一蹶不振。而是选择了直面危机,诚恳整改。迅速公开承认错误,向消费者、投资者和社会各界诚恳道歉。随后,瑞幸对内部管理体系进行了大刀阔斧的改革。瑞幸加强了财务审计和内部控制,引入了专业的管理团队,重新梳理了公司的治理结构和决策流程。
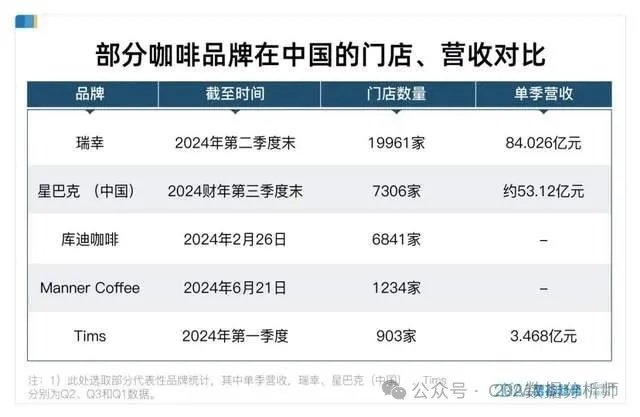
2024年7月30日,瑞幸咖啡披露2024年第二季度财报,交出了一份让行业惊讶的成绩单:
面对同行6.9元、9.9元的低价围剿,瑞幸咖啡二季度收入同比增长35.5%,实现收入84.03亿元,创下单季度营收新高;
外界关注的利润表现也恢复至健康水平,实现净利润 8.71 亿元,净利润率达到 10.4%;
随着门店的迅速扩张,瑞幸月均交易用户数再创历史新高,二季度达到6,969 万;
二季度瑞幸产品总售卖数突破7.5 亿件,占国内总杯量的 24%,也就是每4杯中就有1杯出自瑞幸。
联名共赢 指数级增长
瑞幸爆款制造的底层逻辑是强大的数据运营能力,瑞幸利用大数据分析消费者偏好,通过数字化研发体系快速响应市场变化,瑞幸每三四天推出一款新产品,2020年、2021年和2022年上半年,瑞幸推出的现制新饮品分别是77款、113款和68款,这种快速迭代的能力让瑞幸能够持续推出受欢迎的产品。
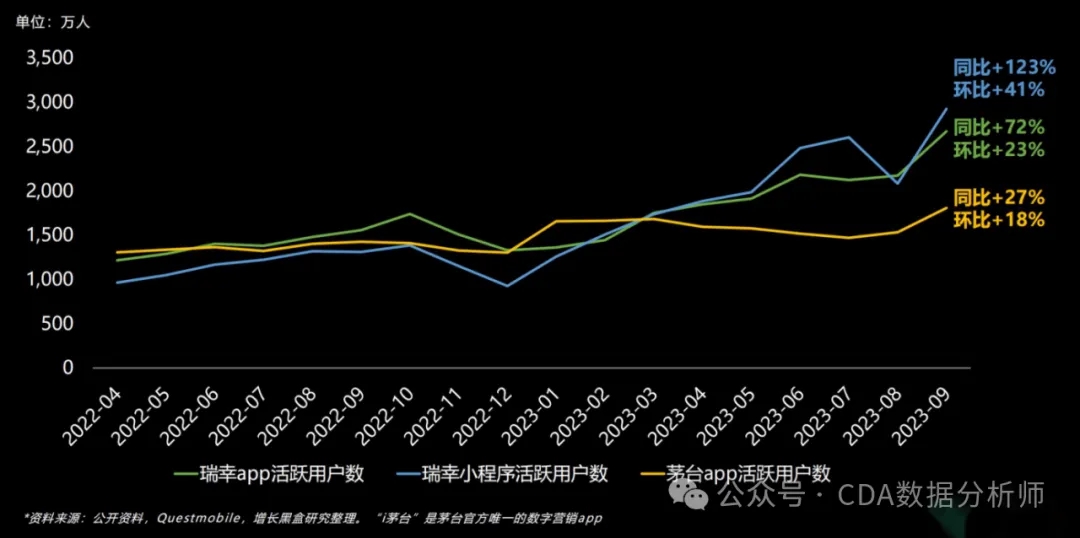
2023 年瑞幸和茅台的联名实现了瑞幸和茅台的共赢。一个是在销售收入上,一个是在广告宣发上,整体的销量以及活跃度暴涨,特别是瑞幸小程序活跃度,基本上是同比增加123%,环比上升 41%,可以说是指数级增长。
三、爆款制造的底层逻辑
作为一名数据分析师,我们要回归分析瑞幸为什么有能力去制造这样的爆款?
1、头部产品稳定输出
瑞幸咖啡的某些产品,如生椰拿铁,无论任何时候,都能稳定地保持其在销售排行榜上的领先地位。这款产品的销量表现始终稳定,显示出其作为头部产品的强大吸引力。瑞幸咖啡始终注重这些核心产品的生产和供应,确保它们始终能满足消费者的需求。这些稳定的产品,是为公司带来稳定收入的基石。
2、与知名IP联名
瑞幸咖啡通过与知名IP或品牌进行联名合作,创造出具有冲击力的营销效果。例如,2023年推出的酱香拿铁以及今年的黑神话联名产品,都取得了显著的成功。
这些联名产品不仅吸引了大量消费者的注意,还显著提升了男性客户的购买力,这一市场潜力在以往的营销策略中往往被忽视。在黑神话联名产品的推广过程中,瑞幸咖啡的内部包装和营销模式似乎提前泄露,引起了市场的广泛关注。过去的营销实践中,很多品牌可能没有充分认识到男性消费者在特定产品类别中的购买潜力。瑞幸咖啡通过与黑神话等男性向IP的合作,成功地激发了这一部分市场的活力,展示了男性消费者在咖啡消费市场中的重要性。
瑞幸咖啡通过稳定的头部产品和创新的联名合作,成功地构建了其在市场上的竞争地位。这些策略不仅保证了收入的稳定性,还为其带来了新的增长点,值得其他品牌学习和借鉴。
3、线下合作
瑞幸公司正积极进行版图扩张,以此作为未来增长的动力。这包括线下门店的增加、与商超的合作以及与银行的战略合作。特别值得注意的是,尽管当前消费趋势倾向于线上购物,瑞幸咖啡依然重视线下门店的运营,并探索与银行的合作机会。当然,瑞幸咖啡在抖音、小红书等平台设有直播店铺并销售产品,但仍然没有放弃线下,即便在实体经济面临挑战的时期,瑞幸咖啡依然坚持对线下门店的投入和运营。
4、回顾客户服务本身
真正知道顾客想要的是什么,黑神话联名的咖啡在网上也不是一致好评,口感也不是特别好。也有很多人说不好喝,但为什么它的销量还是会缔造这样一个神话?就是客户需求的,真的是那一杯咖啡吗?还有我们玩这个游戏真的是为了打通关这个游戏吗?其实需求本身也许不是表面上的一些内容,需求的本身可能是更深层次的一些文化含义。
那么正是因为瑞幸对于数据运维的掌控能力上才实现了其服务的升级,瑞幸咖啡的产品联名策略时,可以看出公司在推出新产品前进行了深入的市场调研。例如,瑞幸咖啡推出的“酱香拿铁”是在分析了茅台酒的品牌形象和股市趋势后做出的决策。瑞幸咖啡推出“黄玫瑰”系列产品,则是针对热门连续剧在网上的热议和评价进行的市场响应。可以推测,瑞幸咖啡的运维团队可能利用Python等技术手段,对相关数据进行了爬取和分析,以此为依据,打造了符合市场需求的产品,增强了品牌的市场竞争力。
对比不同的数据,了解哪些方法最有效。
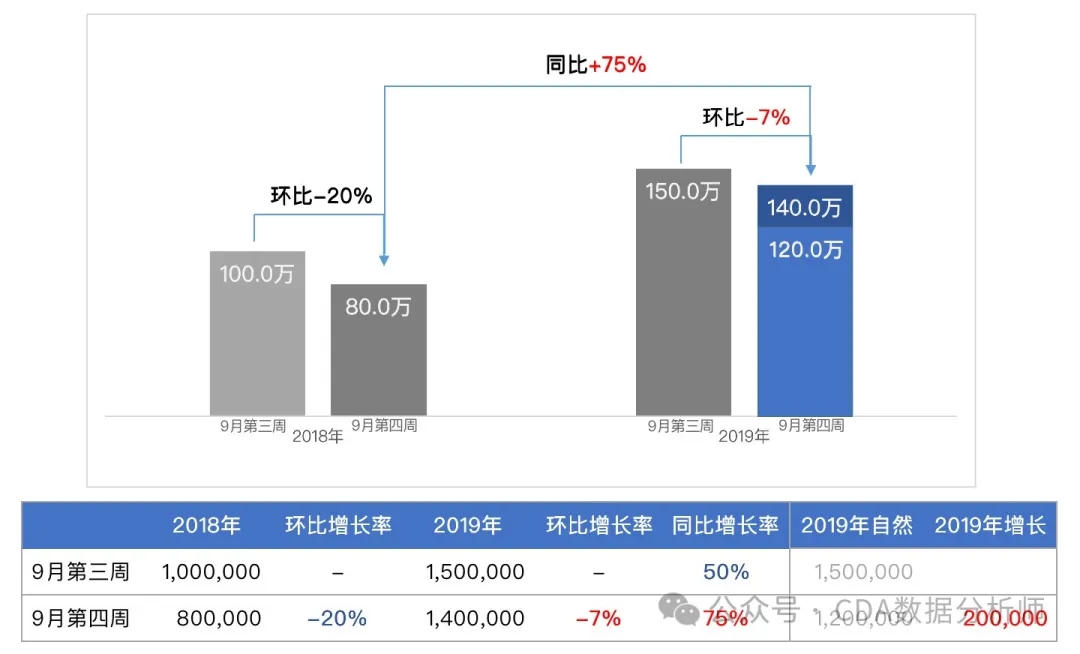
对比分析就是比较两个相关的指标,以展示规模、水平、速度等。常见的对比方法有时间对比(如同比、环比、定基比)、空间对比和标准对比。比如,本周和上周的对比是环比,本月第一周和上月第一周的对比是同比,所有数据和今年第一周的对比是定基比。这样可以分析业务增长和速度。
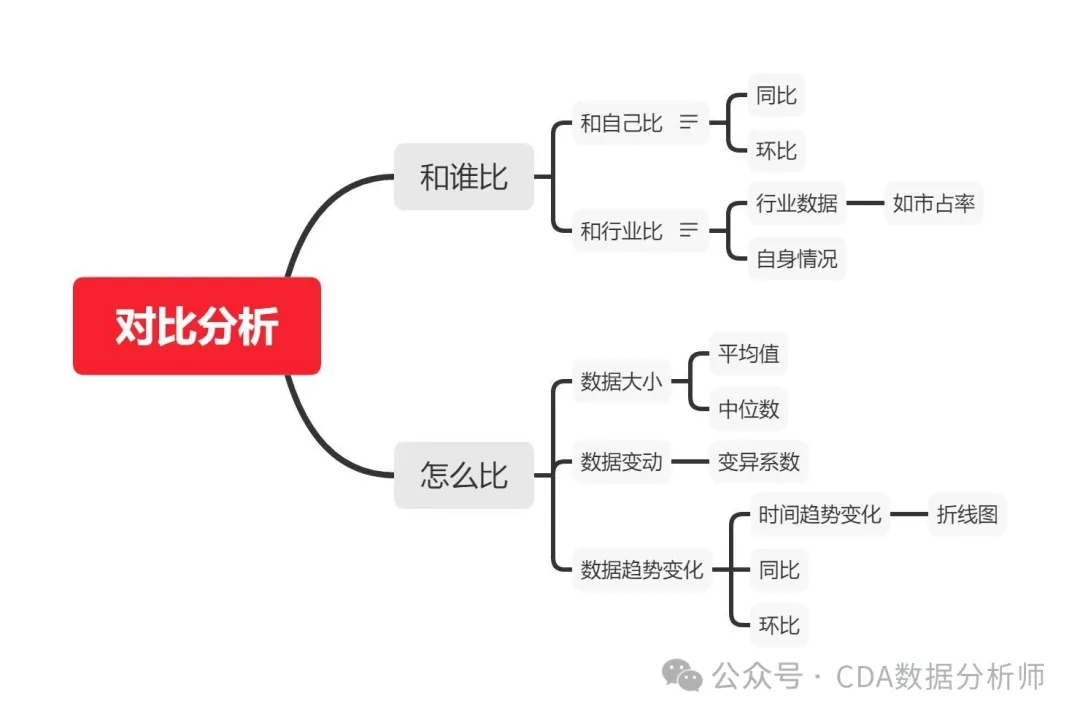
学习评估数据的可靠性,理解数据的上下文,识别潜在的偏差或错误。合理地质疑数据的来源、准确性和有效性,并分析数据背后的假设和局限性。在建立模型前考虑不同的假设和可能性,确保所选模型与实际情况相符。
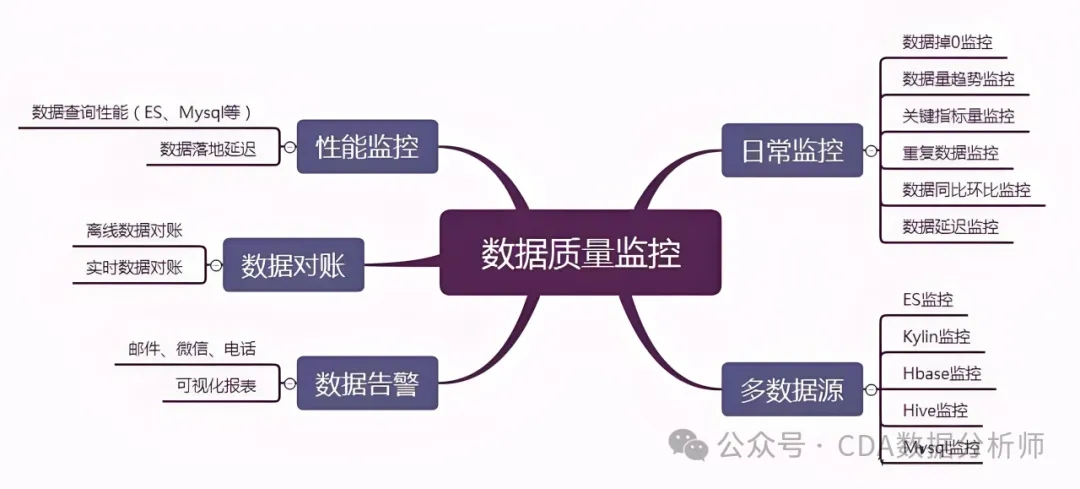
识别缺失值:确定数据集中哪些数据缺失。
填补缺失值:使用均值、中位数、众数或插值等方法填补缺失值,或根据业务需求选择删除缺失数据的行或列。
识别重复项:查找并标记数据集中重复的记录。
删除重复项:根据特定的标准(如时间戳或唯一标识符)删除重复的数据记录,确保每条记录都是唯一的。
一致化格式:确保数据格式统一,例如日期格式(YYYY-MM-DD 或 MM/DD/YYYY)、字符串大小写(全部小写或首字母大写)等。
数据类型转换:将数据转换为合适的数据类型(如将字符串转为日期类型,或将数值转为浮点数)。
识别异常值:使用统计方法(如Z-score、IQR)检测数据中的异常值。
处理方法:可以选择删除、修正或保留异常值,具体取决于数据分析的需求和背景。
去除噪声:清除文本数据中的无关内容,如标点符号、空格、HTML标签等。
数据规范化:消除冗余信息,确保各个数据表之间的关系明确,避免数据冲突。
光学不练假把式,你需要参与实际的数据分析项目,进行数据清洗、可视化和建模。通过实践,培养对数据的直觉。
模拟数据分析:使用真实数据集进行练习,尝试进行不同类型的数据分析(如探索性数据分析、回归分析等)。
线性回归的基本概念
线性回归分析是数据挖掘里一个非常重要的方法,相信大家以前在高中或者大学时都学过一点点线性回归的概念。在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。
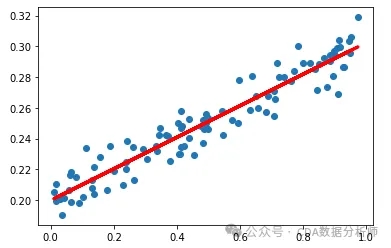
听着有点复杂,简单来说,就是看一组零散的数据是否存在相关性。直白点说,就是在图像上给你一堆点,你来找一条线,然后让这条线尽可能的在所有点的中间。这个找直线的过程,就是在做回归了。如下图所示。
线性回归是一种预测连续值的统计方法 。它假设因变量(Y)与一个或多个自变量(X)之间存在线性关系。简单线性回归涉及一个自变量和一个因变量,其模型可以表示为 Y = β0 + β1X + ε,其中β0是截距,β1是斜率,ε是误差项。
进一步思考:为什么非要找这么一条尽可能的在所有点的中间的直线?
我们面对的是一堆散乱的点,看不出具体的相关关系,而线能够体现趋势。所以,我们就是想办法来找一条尽可能在所有点的中间的直线,代表一个数据的整体趋势,让数据的整体关系更加清晰可见,这样就方便我们预判未来的情况。
回归的目的:通过找到的线来预测未来。
回归之所以能预测,是因为它的底层逻辑是:通过历史数据,摸透了“套路”,然后通过这个套路来预测未来的结果。
· 注意:在回归中,我们要预测的target是连续型数据(降雨量,房价,长度,密度这些)
应用场景
线性回归分析在日常工作中运用非常广泛,通过线性回归,我们可以用模型去描述两组数据中是否存在相关性。
在分析销售数据时,我们经常要对广告费用以及销售额的关系进行判断,评估广告费用对销售额的作用到底有多大,公司应不应该加大广告费投入,如果未来投入一定的广告费用,预测销售额可以达到多少…这一系列问题都可以通过线性回归分析去得出答案。
提升预测准确性
怎么使得预测更加准确呢?
那就多加入一些预测信息,机器学习中也把这些预测信息叫作特征。特征多了呢,我们的预测也就会靠谱的多。同时,特征增多了,原来的参数也就不够用了。所以,有几个特征就会有几个参数,即让每一个特征对应一个参数。这用多个 x 来预测 y ,就是多元线性回归,也可以引出线性回归的一般表达式:
拿房价预测来说,可能需要综合考虑到地段、房屋大小、距离、还有其他,并且按照重要性大小给到他们一定的权重大小(体现在下面公式中就是系数的大小)。
那么写成表达式为:
这个式子就是一个回归方程,地段、距离这些是特征,房价就是要预测的标签,系数w称为回归系数,我们通过输入收集到的现有房价信息数据求得回归系数w的过程就是回归。得到回归系数后,我们另外拿一个房屋信息数据输入,就可以通过这个式子得到预测值,也就是这里预测出的房价。
为了方便计算,我们可以用矩阵来表示上面的方程:
其中,W看成W1 ~Wn组成的列矩阵,x 是 xi1 ~ xin 不同特征组成的特征矩阵。这个预测函数的本质就是我们需要构建的模型,机器学习中也称“决策函数”。
实际操作案例
以Python的statsmodels库为例,演示如何进行线性回归分析:
import statsmodels.api as sm
# 假设df是包含自变量X和因变量Y的DataFrame
X = df[['Independent Variable']]
Y = df['Dependent Variable']
# 添加常数项,以便模型包含截距
X = sm.add_constant(X)
# 建立线性回归模型
model = sm.OLS(Y, X).fit()
# 输出回归结果
print(model.summary())总结
线性回归是一个强大的工具,适用于各种预测和分析场景。通过理解其基本原理和正确应用,可以有效地从数据中提取信息和洞见。
通过以上方法,逐步培养和提升自己的数据敏感度,关键在于实践和持续学习,随着时间的推移,你会发现自己在数据分析和决策方面的能力显著提高!
随着各行各业进行数字化转型,数据分析能力已经成了职场的刚需能力,这也是这两年CDA数据分析师大火的原因。和领导提建议再说“我感觉”“我觉得”,自己都觉得心虚,如果说“数据分析发现……”,肯定更有说服力。想在职场精进一步还是要学习数据分析的,统计学、概率论、商业模型、SQL,Python还是要会一些,能让你工作效率提升不少。备考CDA数据分析师的过程就是个自我提升的过程。

CDA 考试官方报名入口:https://www.cdaglobal.com/pinggu.html

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27TensorFlow Datasets(TFDS)是一个用于下载、管理和预处理机器学习数据集的库。它提供了易于使用的API,允许用户从现有集合中 ...
2025-03-26"不谋全局者,不足谋一域。"在数据驱动的商业时代,战略级数据分析能力已成为职场核心竞争力。《CDA二级教材:商业策略数据分析 ...
2025-03-26当你在某宝刷到【猜你喜欢】时,当抖音精准推来你的梦中情猫时,当美团外卖弹窗刚好是你想吃的火锅店…… 恭喜你,你正在被用户 ...
2025-03-26当面试官问起随机森林时,他到底在考察什么? ""请解释随机森林的原理""——这是数据分析岗位面试中的经典问题。但你可能不知道 ...
2025-03-25在数字化浪潮席卷的当下,数据俨然成为企业的命脉,贯穿于业务运作的各个环节。从线上到线下,从平台的交易数据,到门店的运营 ...
2025-03-25在互联网和移动应用领域,DAU(日活跃用户数)是一个耳熟能详的指标。无论是产品经理、运营,还是数据分析师,DAU都是衡量产品 ...
2025-03-24ABtest做的好,产品优化效果差不了!可见ABtest在评估优化策略的效果方面地位还是很高的,那么如何在业务中应用ABtest? 结合企业 ...
2025-03-21在企业数据分析中,指标体系是至关重要的工具。不仅帮助企业统一数据标准、提升数据质量,还能为业务决策提供有力支持。本文将围 ...
2025-03-20解锁数据分析师高薪密码,CDA 脱产就业班助你逆袭! 在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的 ...
2025-03-19在 MySQL 数据库中,查询一张表但是不包含某个字段可以通过以下两种方法实现:使用 SELECT 子句以明确指定想要的字段,或者使 ...
2025-03-17在当今数字化时代,数据成为企业发展的关键驱动力,而用户画像作为数据分析的重要成果,改变了企业理解用户、开展业务的方式。无 ...
2025-03-172025年是智能体(AI Agent)的元年,大模型和智能体的发展比较迅猛。感觉年初的deepseek刚火没多久,这几天Manus又成为媒体头条 ...
2025-03-14以下的文章内容来源于柯家媛老师的专栏,如果您想阅读专栏《小白必备的数据思维课》,点击下方链接 https://edu.cda.cn/goods/sh ...
2025-03-13