支持向量机实例讲解
简介
掌握机器学习算法不再是天方夜谭的事情。大多数初学者都是从回归模型学起。虽然回归模型简单易学易上手,但是它能解决我们的需求吗?当然不行!因为除了回归模型外我们还可以构建许多模型。
我们可以把机器学习算法看成包含剑、锋刃、弓箭和匕首等武器的兵器库。你拥有各式各样的工具,但是你应该在恰当的时间点使用它们。比如,我们可以把回归模型看做“剑”,它可以非常高效地处理切片数据,但是它却无法应对高度复杂的数据。相反的是,“支持向量机模型”就像一把尖刀,它可以更好地对小数据集进行建模分析。
到目前为止,我希望你已经掌握了随机森林、朴素贝叶斯算法和集成建模方法。不然的话,我建议你应该花一些时间来学习这些方法。本文中,我将会介绍另外一个重要的机器学习算法——支持向量机模型。
目录
-
什么是支持向量机模型?
-
支持向量机模型运行原理
-
如何利用 Python 实现 SVM?
-
如何调整 SVM 的参数?
-
SVM 的优缺点
什么是支持向量机模型?
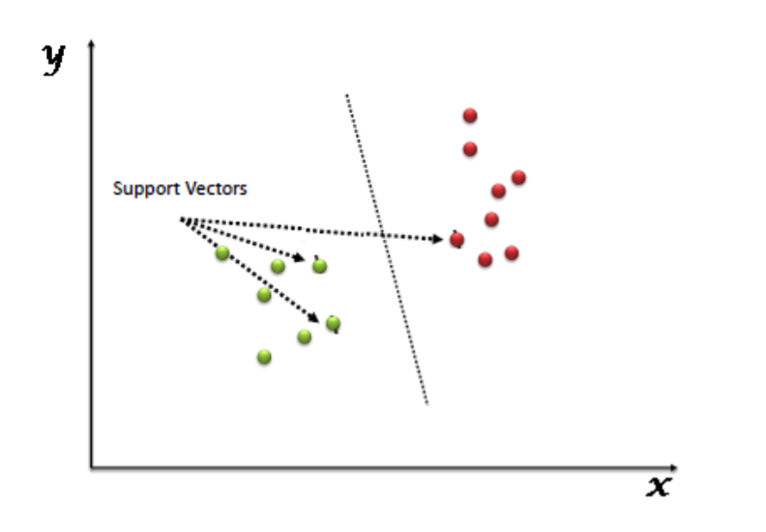
支持向量机(SVM)是一种有监督学习的算法,它可以用来处理分类和回归的问题。然而,实际应用中,SVM 主要用来处理分类问题。在这个算法中,首先我们将所有点画在一个 n 维空间中(其中 n 代表特征个数)。然后我们通过寻找较好区分两类样本的超平面来对数据进行分类处理(如下图所示)。
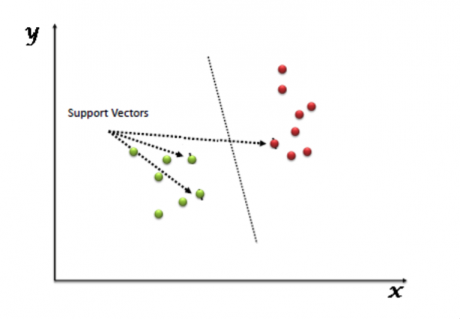
支持向量是观测值的坐标,支持向量机是隔离两个类别的最佳边界(超平面)。
你可以在这里看到关于支持向量的定义和一些实例。
支持向量机的运行原理
首先,我们已经熟悉了如何利用超平面来区分两个类别的数据。如今急需解决的问题是:“如何找出最佳的超平面?”不要担心,它没有你所想的那么困难!
让我们来看几个例子:
场景一:首先,我们有三个超平面(A、B 和 C)。现在我们需要的是找出区分星星和圆圈的最佳超平面。
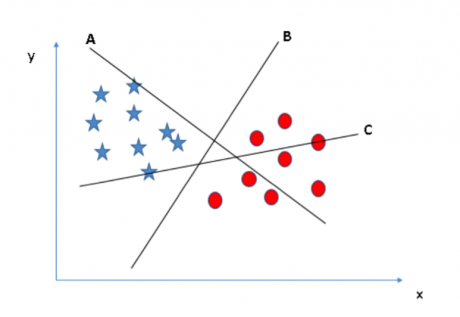
你需要记住一个识别最佳超平面的经验法则:“选择能更好区分两个类别的超平面。”在这个例子中,超平面“B”是最佳分割平面。
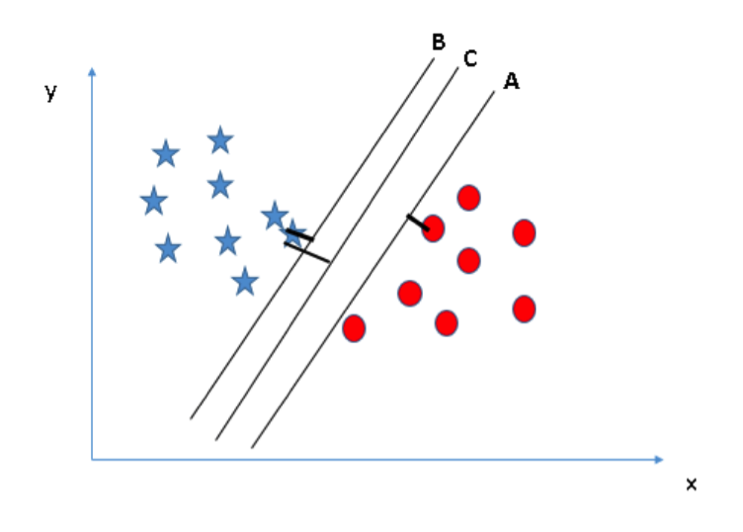
场景二:首先我们有三个超平面(A、B 和 C),它们都很好地区分两个类别的数据。那么我们要如何选出最佳的超平面呢?
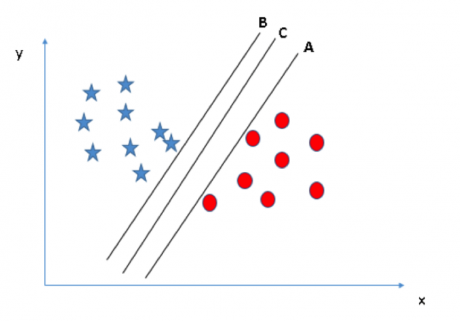
在这里,我们可以通过最大化超平面和其最近的各个类别中数据点的距离来寻找最佳超平面。这个距离我们称之为边际距离。
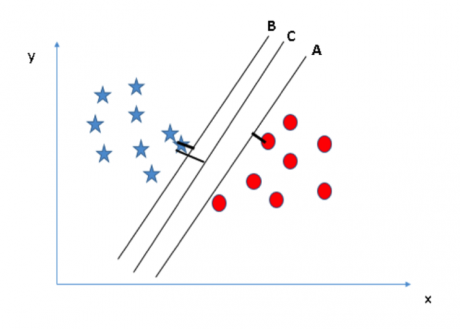
从上图中你可以看到超平面 C 的边际距离最大。因此,我们称 C 为最佳超平面。选择具有最大边际距离的超平面的做法是稳健的。如果我们选择其他超平面,将存在较高的错分率。
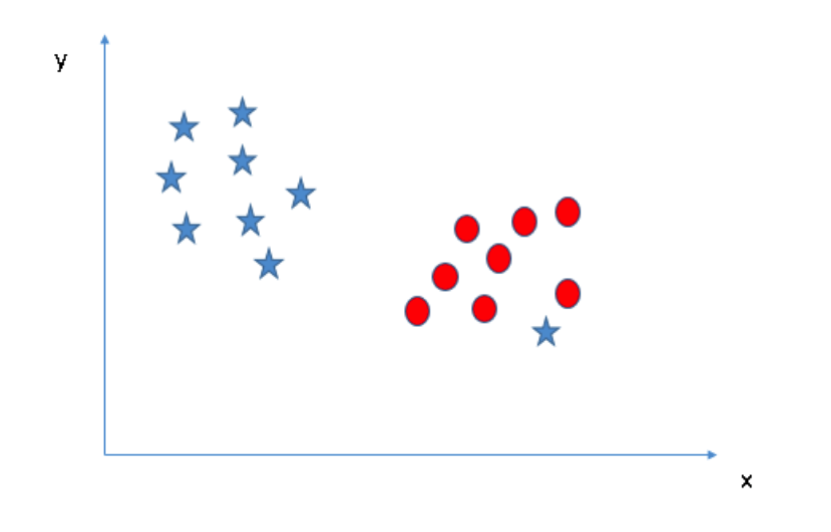
场景三:利用之前章节提到的规则来识别最佳超平面
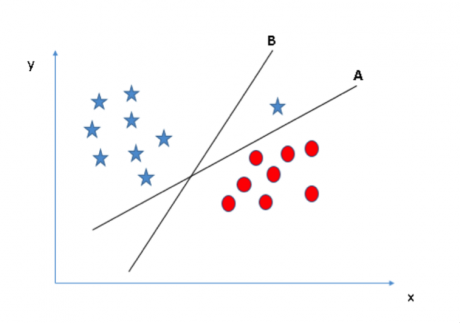
或许你们会选择具有较大边际距离的超平面 B。但是你们错了,SVM 选择超平面时更看重分类的准确度。在上图中,超平面 B 存在一个错分点而超平面 A 的分类则全部正确。因此,最佳超平面是 A。
场景四:由于存在异常值,我们无法通过一条直线将这两类数据完全区分开来。

正如我之前提到的,另一端的星星可以被视为异常值。SVM 可以忽略异常值并寻找具有最大边际距离的超平面。因此,我们可以说 SVM 模型在处理异常值时具有鲁棒性。
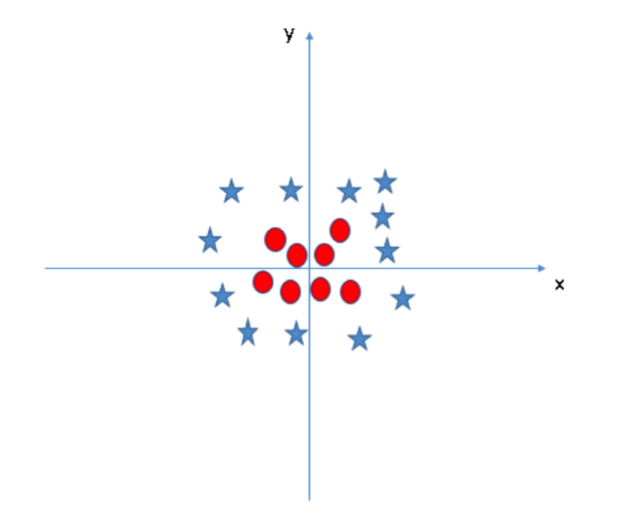
场景五:在这个场景中,我们无法通过线性超平面区分这两类数据,那么 SVM 是如何对这种数据进行分类的呢?
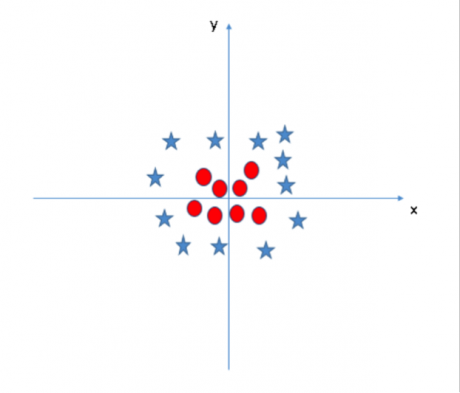
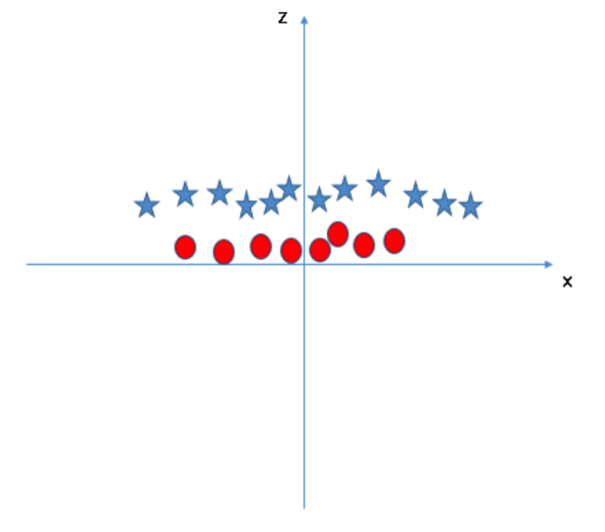
SVM 模型可以非常容易地解决这个问题。通过引入新的变量信息,我们可以很容易地搞定这个问题。比如我们引入新的变量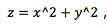 然后我们对 x 和 z 构建散点图:
然后我们对 x 和 z 构建散点图:
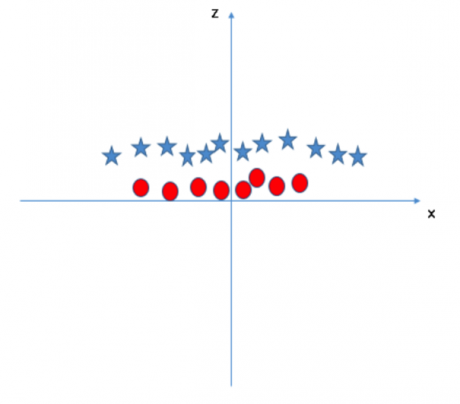
从上图中我们可以看出:
由于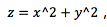 所以变量 z 恒大于零。
所以变量 z 恒大于零。
原始图中,红圈数据分布在原点附近,它们的 z 值比较小;而星星数据则远离原点区域,它们具有较大的 z 值。
在 SVM 模型中,我们可以很容易地找到分割两类数据的线性超平面。但是另外一个急需解决的问题是:我们应该手动增加变量信息从而获得该线性超平面分割吗?答案是否定的!SVM 模型有一个工具叫做 kernel trick。该函数可以将输入的低维空间信息转化为高维空间信息。在解决非线性分割问题时,我们经常用到这个函数。简单地说,该函数可以转换一些极其复杂的数据,然后根据自己所定义的标签或输出结果寻找区分数据的超平面。
我们可以在原始图中画出最佳超平面:

接下来,我们将学习如何将 SVM 模型应用到实际的数据科学案例中。
如何利用 Python 实现 SVM 模型?
在 Python 中,scikit-learn 是一个被广泛使用的机器学习算法库。我们可以通过 scikit-learn 库来构建 SVM 模型。

如何调整 SVM 模型的参数?
有效地调节机器学习算法的参数可以提高模型的表现力。让我们来看看 SVM 模型的可用参数列表:

接下来我将要讨论 SVM 模型中一些比较重要的参数:“kernel”,“gamma”和“C”。
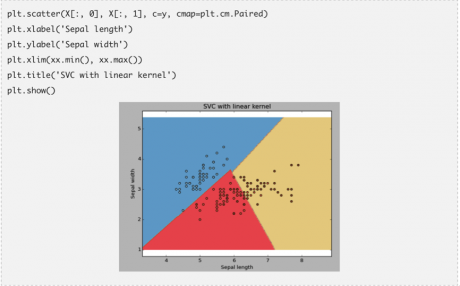
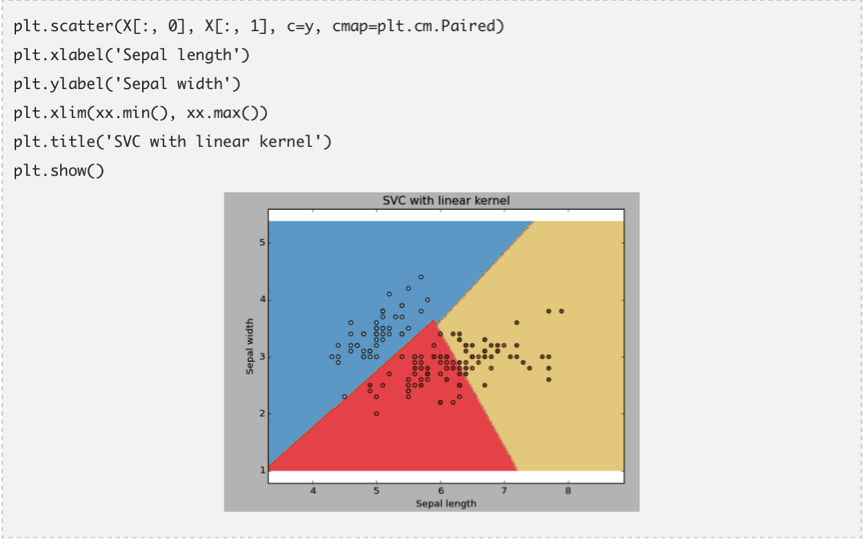
kernel:我们之前已经讨论过这个问题。Kernel参数中具有多个可选项:“linear”,“rbf”和“poly”等(默认值是“rbf”)。其中 “rbf”和“poly”通常用于拟合非线性超平面。下面是一个例子:我们利用线性核估计对鸢尾花数据进行分类。
例子:线性核估计

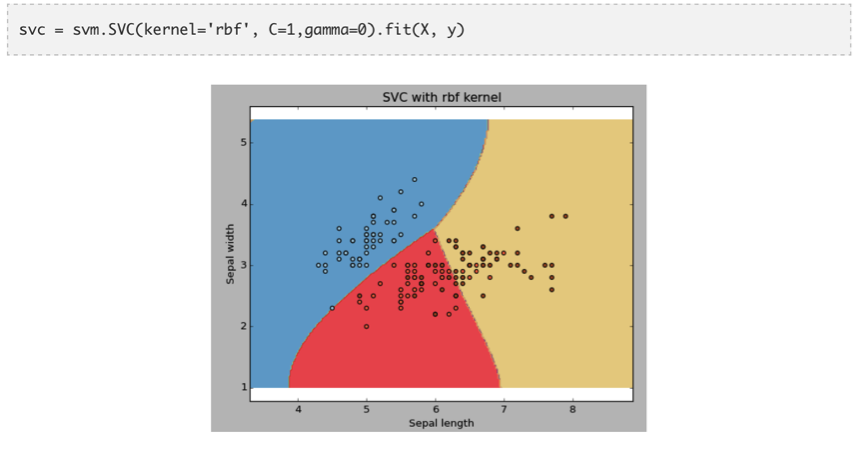
例子:rbf 核估计
我们可以通过下面的代码调用 rbf 核估计,并观察其拟合结果。
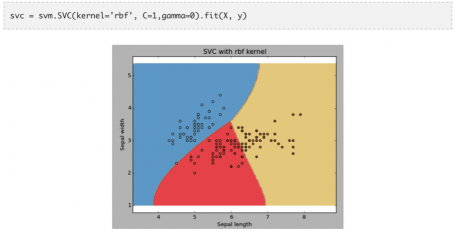
当变量个数比较大时(大于1000),我建议你最好使用线性核估计,因为在高维空间中数据大多是线性可分的。当然你也可以利用 rbf 核估计,不过你必须使用交叉验证调整参数从而避免过度拟合。
“gamma”:“rbf”,“poly”和“sigmoid”的核估计系数。gamma的取值越大,越容易出现过度拟合的问题。
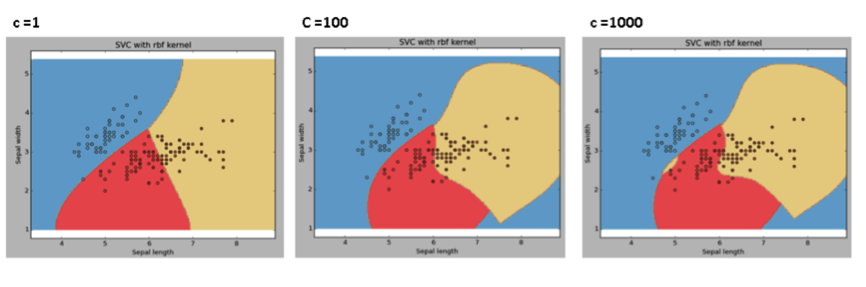
例子:比较不同gamma取值下模型的拟合结果
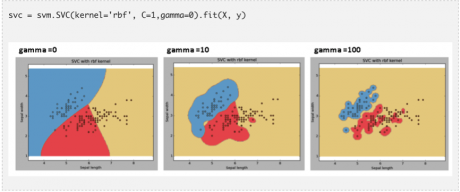
C:误差项的惩罚参数。我们可以通过调节该参数达到平衡分割边界的平滑程度和分类准确率的目的。
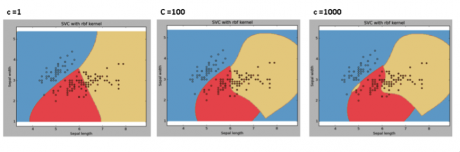
我们应该经常关注交叉验证结果从而有效地利用这些参数的组合避免过度拟合情况的问题。
SVM 模型的优缺点
优点:
-
它的分类效果非常好。
-
它可以有效地处理高维空间数据。
-
它可以有效地处理变量个数大于样本个数的数据。
-
它只利用一部分子集来训练模型,所以 SVM 模型不需要太大的内存。
-
-
缺点:
-
它无法很好地处理大规模数据集,因为此时它需要较长的训练时间。
-
同时它也无法处理包含太多噪声的数据集。
-
SVM 模型并没有直接提供概率估计值,而是利用比较耗时的五倍交叉验证估计量。
结语
在本文中,我们详细地介绍了机器学习算法——支持向量机模型。我介绍了它的工作原理,Python 的实现途径,使模型更有效参数调整技巧以及它的优缺点。我建议你使用 SVM 模型并通过调整参数值分析该模型的解释力。同时我还想了解你们使用 SVM 的经验,你在建模过程有通过调整参数来规避过度拟合问题和减少建模训练的时间吗?
CDA学员免费下载查看报告全文:
2026全球数智化人才指数报告【CDA数据科学研究院】.pdf
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;



















 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330