基于最小二乘法的异常行为分析模型设计
本文针对异常访问现状及问题进行简要描述,在此基础上提出基于一元线性回归的最小二乘法异常访问分析模型,通过该模型解决了异常访问中时间与访问间相关性问题。
异常访问是指网络行为偏离正常范围的访问情况。异常访问包含多种场景,如Web访问、数据库访问、操作系统访问、终端交互等。
异常访问一直是网络信息安全中备受困扰的。困扰主要体现在以下几个方面,通过某一个模型满足所有场景,模型缺少明确使用条件致使结果不明确,模型计算量大计算耗时长等方面。
基于以上的现状,本文仅针对系统登录异常访问进行分析,通过对系统登录事件与时间进行回归统计筛选出异常访问时间段。
下图为异常登录事件检测的时序图:
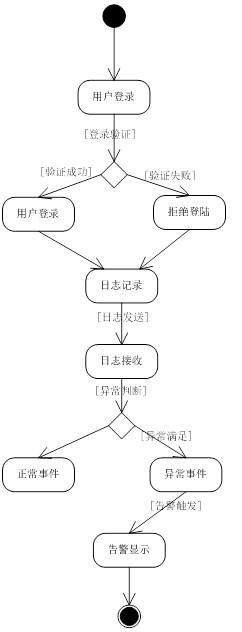
异常登录时序图
异常登录事件模型的活动图流程如下:
1)用户进行登录,输入相应的用户名及口令。
2)系统进行登录验证,判断是否为合法用户登录。
3)登录成功或失败均会将本次登录行为记录下来。
4)日志自动发送至分析系统。
5)分析系统对收到的日志进行分析,分析采用最小二乘法。
6)如果发现异常登录事件则触发告警事件。
7)最后工作人员可收到告警提示,并查看到相应的告警。
当触发告警后,工作人员需要在量化分析中进行进一步分系工作。通过日志的登录事件能够找到何人何时登录哪个系统。详细记录下这些信息后方可以进行后续的时间处置工作。
异常登录模型是分析系统的一个重要分析模型。这个分析模型中采用最小二乘法对登录事件进行异常判断。异常判断包括成功登录的异常判断,以及未成功登录的异常判断两类。
以下面的成功登录事件为例进行详细说明:

登录统计列表
上面的表格中描述的是以5分钟为单位时间内,系统登录成功的事件统计。
此时我们无法看出哪个时间单位内存在异常登录的情况。
如下图所示:
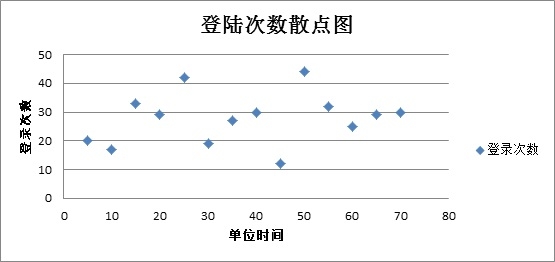
登陆次数散点图
首先采用“最小二乘法”对其求解。

最小二乘法
求解出直线与散点图叠加,如下所示:
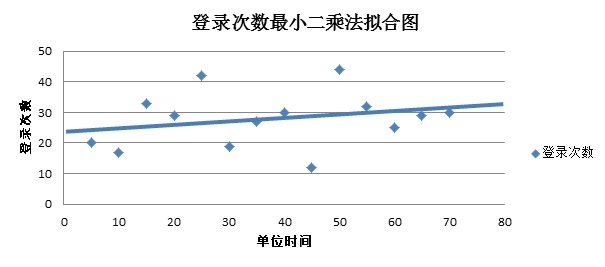
登录次数最小二乘法拟合图
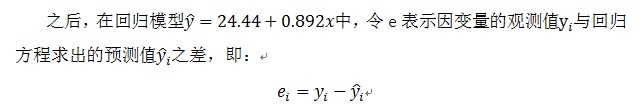
回归模型
经过逐一计算每个点的残差如下:

登陆次数残差结果表
通过上面的表格可以看到,序号为5、9、10的三个点残差值偏离相对比较大。同时,根据经验判断,正常的登录事件残差值通常在-10~+10之间。而这3个点的残差值偏离区间明显。残差值分别为“15.23967”,”-16.4549”,“15.098”。
针对此登录事件我们采用的置信区间为-10~+10,置信区间可根据不同的场景进行调整。
通过采用最小二乘法的方式进行异常登录事件查询,能够很好的解决传统统计表格中难以发现的问题。传统的方式都是采用TopN的方式对登录成功、登录失败的事件进行简单罗列。但在众多的登录事件中,哪些是值得工作人员关注的却难以得到体现。
最小二乘法的引用可以从众多的登录事件中分离出最为明显的异常行为,通过系统的初筛能够给工作人员提供可供量化分析能力。 工作人员通过量化分析模块能够对相应的事件进行分析工作。同时残差值的可定义为灵活应对分析需求提供便利条件。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330