8个经过证实的方法:提高机器学习模型的准确率
提升一个模型的表现有时很困难。如果你们曾经纠结于相似的问题,那我相信你们中很多人会同意我的看法。你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善。你会觉得无助和困顿,这是90%的数据科学家开始放弃的时候。
不过,这才是考验真本领的时候!这也是普通的数据科学家跟大师级数据科学家的差距所在。你是否曾经梦想过成为大师级的数据科学家呢?
如果是的话,你需要这 8 个经过证实的方法来重构你的模型。建立预测模型的方法不止一种。这里没有金科玉律。但是,如果你遵循我的方法(见下文),(在提供的数据足以用来做预测的前提下)你的模型会拥有较高的准确率。
我从实践中学习了到这些方法。相对于理论,我一向更热衷于实践。这种学习方式也一直在激励我。本文将分享 8 个经过证实的方法,使用这些方法可以建立稳健的机器学习模型。希望我的知识可以帮助大家获得更高的职业成就。.
模型的开发周期有多个不同的阶段,从数据收集开始直到模型建立。
不过,在通过探索数据来理解(变量的)关系之前,建议进行假设生成(hypothesis generation)步骤(如果想了解更多有关假设生成的内容,推荐阅读 why-and-when-is-hypothesis-generation-important )。我认为,这是预测建模过程中最被低估的一个步骤。
花时间思考要回答的问题以及获取领域知识也很重要。这有什么帮助呢?它会帮助你随后建立更好的特征集,不被当前的数据集误导。这是改善模型正确率的一个重要环节。
在这个阶段,你应该对问题进行结构化思考,即进行一个把此问题相关的所有可能的方面纳入考虑范围的思考过程。
现在让我们挖掘得更深入一些。让我们看看这些已被证实的,用于改善模型准确率的方法。
持有更多的数据永远是个好主意。相比于去依赖假设和弱相关,更多的数据允许数据进行“自我表达”。数据越多,模型越好,正确率越高。
我明白,有时无法获得更多数据。比如,在数据科学竞赛中,训练集的数据量是无法增加的。但对于企业项目,我建议,如果可能的话,去索取更多数据。这会减少由于数据集规模有限带来的痛苦。
训练集中缺失值与异常值的意外出现,往往会导致模型正确率低或有偏差。这会导致错误的预测。这是由于我们没能正确分析目标行为以及与其他变量的关系。所以处理好缺失值和异常值很重要。
仔细看下面一幅截图。在存在缺失值的情况下,男性和女性玩板球的概率相同。但如果看第二张表(缺失值根据称呼“Miss”被填补以后),相对于男性,女性玩板球的概率更高。
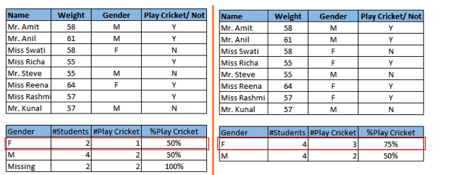
从上面的例子中,我们可以看出缺失值对于模型准确率的不利影响。所幸,我们有各种方法可以应对缺失值和异常值:
这一步骤有助于从现有数据中提取更多信息。新信息作为新特征被提取出来。这些特征可能会更好地解释训练集中的差异变化。因此能改善模型的准确率。
假设生成对特征工程影响很大。好的假设能带来更好的特征集。这也是我一直建议在假设生成上花时间的原因。特征工程能被分为两个步骤:
A) 把变量的范围从原始范围变为从 0 到 1 。这通常被称作数据标准化。比如,某个数据集中第一个变量以米计算,第二个变量是厘米,第三个是千米,在这种情况下,在使用任何算法之前,必须把数据标准化为相同范围。
B) 有些算法对于正态分布的数据表现更好。所以我们需要去掉变量的偏向。对数,平方根,倒数等方法可用来修正偏斜。
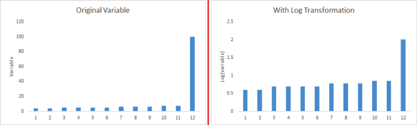
C) 有些时候,数值型的数据在分箱后表现更好,因为这同时也处理了异常值。数值型数据可以通过把数值分组为箱变得离散。这也被称为数据离散化。
创建新特征:从现有的变量中衍生出新变量被称为特征创建。这有助于释放出数据集中潜藏的关系。比如,我们想通过某家商店的交易日期预测其交易量。在这个问题上日期可能和交易量关系不大,但如果研究这天是星期几,可能会有更高的相关。在这个例子中,某个日期是星期几的信息是潜在的。我们可以把这个信息提取为新特征,优化模型。
特征选择是寻找众多属性的哪个子集合,能够最好的解释目标变量与各个自变量的关系的过程。
你可以根据多种标准选取有用的特征,例如:
所在领域知识:根据在此领域的经验,可以选出对目标变量有更大影响的变量。
可视化:正如这名字所示,可视化让变量间的关系可以被看见,使特征选择的过程更轻松。
统计参数:我们可以考虑 p 值,信息价值(information values)和其他统计参数来选择正确的参数。
PCA:这种方法有助于在低维空间表现训练集数据。这是一种降维技术。 降低数据集维度还有许多方法:如因子分析、低方差、高相关、前向后向变量选择及其他。
使用正确的机器学习算法是获得更高准确率的理想方法。但是说起来容易做起来难。
这种直觉来自于经验和不断尝试。有些算法比其他算法更适合特定类型数据。因此,我们应该使用所有有关的模型,并检测其表现。
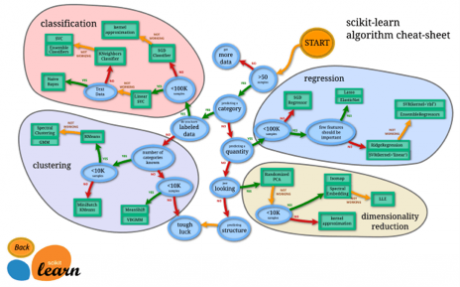
来源:Scikit-Learn 算法选择图
我们都知道机器学习算法是由参数驱动的。这些参数对学习的结果有明显影响。参数调整的目的是为每个参数寻找最优值,以改善模型正确率。要调整这些参数,你必须对它们的意义和各自的影响有所了解。你可以在一些表现良好的模型上重复这个过程。
例如,在随机森林中,我们有 max_features, number_trees, random_state, oob_score 以及其他参数。优化这些参数值会带来更好更准确的模型。
想要详细了解调整参数带来的影响,可以查阅《Tuning the parameters of your Random Forest model》。下面是随机森林算法在scikit learn中的全部参数清单:
RandomForestClassifier(n_estimators=10,criterion='gini',max_depth=None,min_samples_split=2,min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features='auto',max_leaf_nodes=None,bootstrap=True,oob_score=False,n_jobs=1,random_state=None,verbose=0,warm_start=False,class_weight=None)
在数据科学竞赛获胜方案中最常见的方法。这个技术就是把多个弱模型的结果组合在一起,获得更好的结果。它能通过许多方式实现,如:
Bagging (Bootstrap Aggregating)
Boosting
想了解更多这方面内容,可以查阅《Introduction to ensemble learning》。
使用集成方法改进模型正确率永远是个好主意。主要有两个原因:
1)集成方法通常比传统方法更复杂;
2)传统方法提供好的基础,在此基础上可以建立集成方法。
到目前为止,我们了解了改善模型准确率的方法。但是,高准确率的模型不一定(在未知数据上)有更好的表现。有时,模型准确率的改善是由于过度拟合。
如果想解决这个问题,我们必须使用交叉验证技术(cross validation)。交叉验证是数据建模领域最重要的概念之一。它是指,保留一部分数据样本不用来训练模型,而是在完成模型前用来验证。
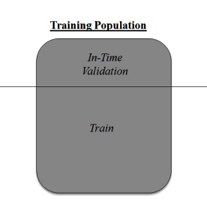
这种方法有助于得出更有概括性的关系。想了解更多有关交叉检验的内容,建议查阅《Improve model performance using cross validation》。
预测建模的过程令人疲惫。但是,如果你能灵活思考,就可以轻易胜过其他人。简单地说,多考虑上面这8个步骤。获得数据集以后,遵循这些被验证过的方法,你就一定会得到稳健的机器学习模型。不过,只有当你熟练掌握了这些步骤,它们才会真正有帮助。比如,想要建立一个集成模型,你必须对多种机器学习算法有所了解。
本文分享了 8 个经过证实的方法。这些方法用来改善模型的预测表现。它们广为人知,但不一定要按照文中的顺序逐个使用。

数据分析咨询请扫描二维码
CDA持证人Louis CDA持证人基本情况 我大学是在一个二线城市的一所普通二本院校读的,专业是旅游管理,非计算机非统计学。毕业之 ...
2024-12-18最近,知乎上有个很火的话题:“一个人为何会陷入社会底层”? 有人说,这个世界上只有一个分水岭,就是“羊水”;还有人说,一 ...
2024-12-18在这个数据驱动的时代,数据分析师的技能需求快速增长。掌握适当的编程语言不仅能增强分析能力,还能帮助分析师从海量数据中提取 ...
2024-12-17在当今信息爆炸的时代,数据分析已经成为许多行业中不可或缺的一部分。想要在这个领域脱颖而出,除了热情和毅力外,你还需要掌握 ...
2024-12-17数据分析,是一项通过科学方法处理数据以获取洞察并支持决策的艺术。无论是在商业环境中提升业绩,还是在科研领域推动创新,数据 ...
2024-12-17在数据分析领域,图表是我们表达数据故事的重要工具。它们不仅让数据变得更加直观,也帮助我们更好地理解数据中的趋势和模式。相 ...
2024-12-16在当今社会,我们身处着一个飞速发展、变化迅猛的时代。不同行业在科技进步、市场需求和政策支持的推动下蓬勃发展,呈现出令人瞩 ...
2024-12-16在现代商业世界中,数据分析师扮演着至关重要的角色。他们通过解析海量数据,为企业战略决策提供有力支持。要有效完成这项任务, ...
2024-12-16在当今数据爆炸的时代,数据分析师是组织中不可或缺的导航者。他们通过从大量数据中提取可操作的洞察力,帮助企业在竞争激烈的市 ...
2024-12-16在现代企业中,数据分析师扮演着至关重要的角色。他们不仅负责处理和分析大量的数据,还需要将这些分析结果转化为切实可行的商业 ...
2024-12-16在当今的大数据时代,数据分析已经成为推动企业战略的重要组成部分。无论是金融、医疗、零售,还是制造业,各个行业对数据分析的 ...
2024-12-16在当今这个以数据为驱动力的时代,数据分析领域正在迅速扩展与发展。随着大数据、人工智能和机器学习技术的不断进步,数据分析已 ...
2024-12-16在信息爆炸和数据驱动的时代,数据分析专业是否值得一选成为许多人思考的议题。无论是刚刚迈入大学校门的新生,还是考虑职业转型 ...
2024-12-16适合数据分析专业学生的实习岗位有很多,以下是一些推荐: 阿里巴巴数据分析岗位实习:适合经济、统计学、数学及计算机专业的 ...
2024-12-16在数据科学领域,探索实习机会是一个理想的学习和成长方式。实习不仅可以提供宝贵的实践经验,还能帮助学生发展关键的数据分析技 ...
2024-12-16在当今信息驱动的时代,数据分析不仅成为了企业决策的重要一环,还催生了各种职业机会。从技术到业务,数据分析专业的就业岗位种 ...
2024-12-16在现代企业中,数据分析师被誉为“数据探险家”,他们通过揭示隐藏在数据背后的故事,帮助公司优化业务策略和做出明智的决策。然 ...
2024-12-16在大数据崛起的时代,数据分析师被誉为企业的“幕后英雄”。他们通过解读数据,揭示隐藏的真相,为企业战略提供重要的指导。这份 ...
2024-12-16在这个信息大爆炸的时代,数据分析师成为了企业中的“福尔摩斯”,他们能够从庞杂的数据中提取关键洞察,为业务发展提供坚实支持 ...
2024-12-16在这个数据为王的现代社会,数据分析师如同企业的导航员,洞悉数据背后所隐藏的商业机会和战略优势。然而,成为一名优秀的数据分 ...
2024-12-16






