关联规则挖掘在电商、零售、大气物理、生物医学已经有了广泛的应用,本篇文章将介绍一些基本知识和Aprori算法。
啤酒与尿布的故事已经成为了关联规则挖掘的经典案例,还有人专门出了一本书《啤酒与尿布》,虽然说这个故事是哈弗商学院杜撰出来的,但确实能很好的解释关联规则挖掘的原理。我们这里以一个超市购物篮迷你数据集来解释关联规则挖掘的基本概念:
| TID | Items |
| T1 | {牛奶,面包} |
| T2 | {面包,尿布,啤酒,鸡蛋} |
| T3 | {牛奶,尿布,啤酒,可乐} |
| T4 | {面包,牛奶,尿布,啤酒} |
| T5 | {面包,牛奶,尿布,可乐} |
表中的每一行代表一次购买清单(注意你购买十盒牛奶也只计一次,即只记录某个商品的出现与否)。数据记录的所有项的集合称为总项集,上表中的总项集S={牛奶,面包,尿布,啤酒,鸡蛋,可乐}。
一、关联规则、自信度、自持度的定义
关联规则就是有关联的规则,形式是这样定义的:两个不相交的非空集合X、Y,如果有X-->Y,就说X-->Y是一条关联规则。举个例子,在上面的表中,我们发现购买啤酒就一定会购买尿布,{啤酒}-->{尿布}就是一条关联规则。关联规则的强度用支持度(support)和自信度(confidence)来描述,
支持度的定义:support(X-->Y) = |X交Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数。例如:support({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/数据记录数 = 3/5=60%。
自信度的定义:confidence(X-->Y) = |X交Y|/|X| = 集合X与集合Y中的项在一条记录中同时出现的次数/集合X出现的个数 。例如:confidence({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/啤酒出现的次数=3/3=100%;confidence({尿布}-->{啤酒}) = 啤酒和尿布同时出现的次数/尿布出现的次数 = 3/4 = 75%。
这里定义的支持度和自信度都是相对的支持度和自信度,不是绝对支持度,绝对支持度abs_support = 数据记录数N*support。
支持度和自信度越高,说明规则越强,关联规则挖掘就是挖掘出满足一定强度的规则。
二、关联规则挖掘的定义与步骤
关联规则挖掘的定义:给定一个交易数据集T,找出其中所有支持度support >= min_support、自信度confidence >= min_confidence的关联规则。
有一个简单而粗鲁的方法可以找出所需要的规则,那就是穷举项集的所有组合,并测试每个组合是否满足条件,一个元素个数为n的项集的组合个数为2^n-1(除去空集),所需要的时间复杂度明显为O(2^N),对于普通的超市,其商品的项集数也在1万以上,用指数时间复杂度的算法不能在可接受的时间内解决问题。怎样快速挖出满足条件的关联规则是关联挖掘的需要解决的主要问题。
仔细想一下,我们会发现对于{啤酒-->尿布},{尿布-->啤酒}这两个规则的支持度实际上只需要计算{尿布,啤酒}的支持度,即它们交集的支持度。于是我们把关联规则挖掘分两步进行:
1)生成频繁项集
这一阶段找出所有满足最小支持度的项集,找出的这些项集称为频繁项集。
2)生成规则
在上一步产生的频繁项集的基础上生成满足最小自信度的规则,产生的规则称为强规则。
关联规则挖掘所花费的时间主要是在生成频繁项集上,因为找出的频繁项集往往不会很多,利用频繁项集生成规则也就不会花太多的时间,而生成频繁项集需要测试很多的备选项集,如果不加优化,所需的时间是O(2^N)。
三、Apriori定律
为了减少频繁项集的生成时间,我们应该尽早的消除一些完全不可能是频繁项集的集合,Apriori的两条定律就是干这事的。
Apriori定律1):如果一个集合是频繁项集,则它的所有子集都是频繁项集。举例:假设一个集合{A,B}是频繁项集,即A、B同时出现在一条记录的次数大于等于最小支持度min_support,则它的子集{A},{B}出现次数必定大于等于min_support,即它的子集都是频繁项集。
Apriori定律2):如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。举例:假设集合{A}不是频繁项集,即A出现的次数小于min_support,则它的任何超集如{A,B}出现的次数必定小于min_support,因此其超集必定也不是频繁项集。
利用这两条定律,我们抛掉很多的候选项集,Apriori算法就是利用这两个定理来实现快速挖掘频繁项集的。
四、Apriori算法
Apriori是由a priori合并而来的,它的意思是后面的是在前面的基础上推出来的,即先验推导,怎么个先验法,其实就是二级频繁项集是在一级频繁项集的基础上产生的,三级频繁项集是在二级频繁项集的基础上产生的,以此类推。
Apriori算法属于候选消除算法,是一个生成候选集、消除不满足条件的候选集、并不断循环直到不再产生候选集的过程。
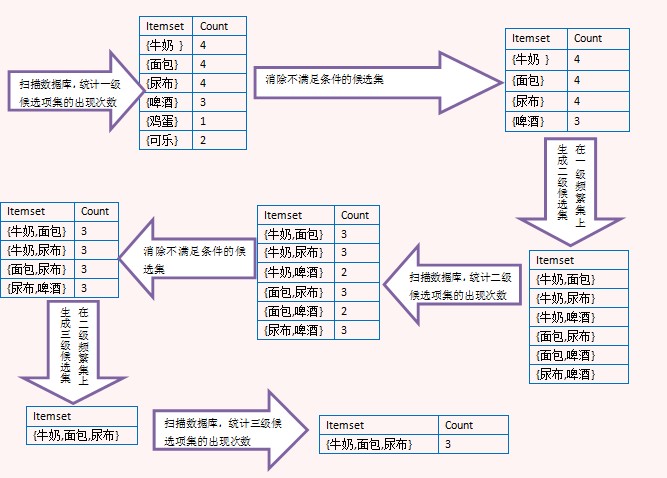
上面的图演示了Apriori算法的过程,注意看由二级频繁项集生成三级候选项集时,没有{牛奶,面包,啤酒},那是因为{面包,啤酒}不是二级频繁项集,这里利用了Apriori定理。最后生成三级频繁项集后,没有更高一级的候选项集,因此整个算法结束,{牛奶,面包,尿布}是最大频繁子集。
算法的思想知道了,这里也就不上伪代码了,我认为理解了算法的思想后,子集去构思实现才能理解更深刻,这里贴一下我的关键代码:

如果想看完整的代码,可以查看我的github,数据集的格式跟本文所述的略有不通,但不影响对算法的理解。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27






