浅谈数据挖掘中的关联规则挖掘
数据挖掘是指以某种方式分析数据源,从中发现一些潜在的有用的信息,所以数据挖掘又称作知识发现,而关联规则挖掘则是数据挖掘中的一个很重要的课题,顾名思义,它是从数据背后发现事物之间可能存在的关联或者联系。举个最简单的例子,比如通过调查商场里顾客买的东西发现,30%的顾客会同时购买床单和枕套,而购买床单的人中有80%购买了枕套,这里面就隐藏了一条关联:床单—>枕套,也就是说很大一部分顾客会同时购买床单和枕套,那么对于商场来说,可以把床单和枕套放在同一个购物区,那样就方便顾客进行购物了。下面来讨论一下关联规则中的一些重要概念以及如何从数据中挖掘出关联规则。
一.关联规则挖掘中的几个概念
先看一个简单的例子,假如有下面数据集,每一组数据ti表示不同的顾客一次在商场购买的商品的集合:
假如有一条规则:牛肉—>鸡肉,那么同时购买牛肉和鸡肉的顾客比例是3/7,而购买牛肉的顾客当中也购买了鸡肉的顾客比例是3/4。这两个比例参数是很重要的衡量指标,它们在关联规则中称作支持度(support)和置信度(confidence)。对于规则:牛肉—>鸡肉,它的支持度为3/7,表示在所有顾客当中有3/7同时购买牛肉和鸡肉,其反应了同时购买牛肉和鸡肉的顾客在所有顾客当中的覆盖范围;它的置信度为3/4,表示在买了牛肉的顾客当中有3/4的人买了鸡肉,其反应了可预测的程度,即顾客买了牛肉的话有多大可能性买鸡肉。其实可以从统计学和集合的角度去看这个问题, 假如看作是概率问题,则可以把“顾客买了牛肉之后又多大可能性买鸡肉”看作是条件概率事件,而从集合的角度去看,可以看下面这幅图:
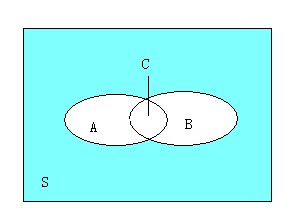
上面这副图可以很好地描述这个问题,S表示所有的顾客,而A表示买了牛肉的顾客,B表示买了鸡肉的顾客,C表示既买了牛肉又买了鸡肉的顾客。那么C.count/S.count=3/7,C.count/A.count=3/4。
在数据挖掘中,例如上述例子中的所有商品集合I={牛肉,鸡肉,牛奶,奶酪,靴子,衣服}称作项目集合,每位顾客一次购买的商品集合ti称为一个事务,所有的事务T={t1,t2,....t7}称作事务集合,并且满足ti是I的真子集。一条关联规则是形如下面的蕴含式:
X—>Y,X,Y满足:X,Y是I的真子集,并且X和Y的交集为空集
其中X称为前件,Y称为后件。
对于规则X—>Y,根据上面的例子可以知道它的支持度(support)=(X,Y).count/T.count,置信度(confidence)=(X,Y).count/X.count 。其中(X,Y).count表示T中同时包含X和Y的事务的个数,X.count表示T中包含X的事务的个数。
关联规则挖掘则是从事务集合中挖掘出满足支持度和置信度最低阈值要求的所有关联规则,这样的关联规则也称强关联规则。
对于支持度和置信度,我们需要正确地去看待这两个衡量指标。一条规则的支持度表示这条规则的可能性大小,如果一个规则的支持度很小,则表明它在事务集合中覆盖范围很小,很有可能是偶然发生的;如果置信度很低,则表明很难根据X推出Y。根据条件概率公式P(Y|X)=P(X,Y)/P(X),即P(X,Y)=P(Y|X)*P(X)
P(Y|X)代表着置信度,P(X,Y)代表着支持度,所以对于任何一条关联规则置信度总是大于等于支持度的。并且当支持度很高时,此时的置信度肯定很高,它所表达的意义就不是那么有用了。这里要注意的是支持度和置信度只是两个参考值而已,并不是绝对的,也就是说假如一条关联规则的支持度和置信度很高时,不代表这个规则之间就一定存在某种关联。举个最简单的例子,假如X和Y是最近的两个比较热门的商品,大家去商场都要买,比如某款手机和某款衣服,都是最新款的,深受大家的喜爱,那么这条关联规则的支持度和置信度都很高,但是它们之间没有必然的联系。然而当置信度很高时,支持度仍然具有参考价值,因为当P(Y|X)很高时,可能P(X)很低,此时P(X,Y)也许会很低。
二.关联规则挖掘的原理和过程
从上面的分析可知,关联规则挖掘是从事务集合中挖掘出这样的关联规则:它的支持度和置信度大于最低阈值(minsup,minconf),这个阈值是由用户指定的。根据支持度=(X,Y).count/T.count,置信度=(X,Y).count/X.count ,要想找出满足条件的关联规则,首先必须找出这样的集合F=X U Y ,它满足F.count/T.count ≥ minsup,其中F.count是T中包含F的事务的个数,然后再从F中找出这样的蕴含式X—>Y,它满足(X,Y).count/X.count ≥ minconf,并且X=F-Y。我们称像F这样的集合称为频繁项目集,假如F中的元素个数为k,我们称这样的频繁项目集为k-频繁项目集,它是项目集合I的子集。所以关联规则挖掘可以大致分为两步:
1)从事务集合中找出频繁项目集;
2)从频繁项目集合中生成满足最低置信度的关联规则。
最出名的关联规则挖掘算法是Apriori算法,它主要利用了向下封闭属性:如果一个项集是频繁项目集,那么它的非空子集必定是频繁项目集。它先生成1-频繁项目集,再利用1-频繁项目集生成2-频繁项目集。。。然后根据2-频繁项目集生成3-频繁项目集。。。依次类推,直至生成所有的频繁项目集,然后从频繁项目集中找出符合条件的关联规则。
下面来讨论一下频繁项目集的生成过程,它的原理是根据k-频繁项目集生成(k+1)-频繁项目集。因此首先要做的是找出1-频繁项目集,这个很容易得到,只要循环扫描一次事务集合统计出项目集合中每个元素的支持度,然后根据设定的支持度阈值进行筛选,即可得到1-频繁项目集。下面证明一下为何可以通过k-频繁项目集生成(k+1)-频繁项目集:
假设某个项目集S={s1,s2...,sn}是频繁项目集,那么它的(n-1)非空子集{s1,s2,...sn-1},{s1,s2,...sn-2,sn}...{s2,s3,...sn}必定都是频繁项目集,通过观察,任何一个含有n个元素的集合A={a1,a2,...an},它的(n-1)非空子集必行包含两项{a1,a2,...an-2,an-1}和 {a1,a2,...an-2,an},对比这两个子集可以发现,它们的前(n-2)项是相同的,它们的并集就是集合A。对于2-频繁项目集,它的所有1非空子集也必定是频繁项目集,那么根据上面的性质,对于2-频繁项目集中的任一个,在1-频繁项目集中必定存在2个集合的并集与它相同。因此在所有的1-频繁项目集中找出只有最后一项不同的集合,将其合并,即可得到所有的包含2个元素的项目集,得到的这些包含2个元素的项目集不一定都是频繁项目集,所以需要进行剪枝。剪枝的办法是看它的所有1非空子集是否在1-频繁项目集中,如果存在1非空子集不在1-频繁项目集中,则将该2项目集剔除。经过该步骤之后,剩下的则全是频繁项目集,即2-频繁项目集。依次类推,可以生成3-频繁项目集。。直至生成所有的频繁项目集。
得到频繁项目集之后,则需要从频繁项目集中找出符合条件的关联规则。最简单的办法是:遍历所有的频繁项目集,然后从每个项目集中依次取1、2、...k个元素作为后件,该项目集中的其他元素作为前件,计算该规则的置信度进行筛选即可。这样的穷举效率显然很低。假如对于一个频繁项目集f,可以生成下面这样的关联规则:
(f-β)—>β
那么这条规则的置信度=f.count/(f-β).count
根据这个置信度计算公式可知,对于一个频繁项目集f.count是不变的,而假设该规则是强关联规则,则(f-βsub)—>βsub也是强关联规则,其中βsub是β的子集,因为(f-βsub).count肯定小于(f-β).count。即给定一个频繁项目集f,如果一条强关联规则的后件为β,那么以β的非空子集为后件的关联规则都是强关联规则。所以可以先生成所有的1-后件(后件只有一项)强关联规则,然后再生成2-后件强关联规则,依次类推,直至生成所有的强关联规则。
下面举例说明Apiori算法的具体流程:
假如有项目集合I={1,2,3,4,5},有事务集T:
1,2,3
1,2,4
1,3,4
1,2,3,5
1,3,5
2,4,5
1,2,3,4
设定minsup=3/7,misconf=5/7。
首先:生成频繁项目集:
1-频繁项目集:{1},{2},{3},{4},{5}
生成2-频繁项目集:
根据1-频繁项目集生成所有的包含2个元素的项目集:任意取两个只有最后一个元素不同的1-频繁项目集,求其并集,由于每个1-频繁项目集元素只有一个,所以生成的项目集如下:
{1,2},{1,3},{1,4},{1,5}
{2,3},{2,4},{2,5}
{3,4},{3,5}
{4,5}
计算它们的支持度,发现只有{1,2},{1,3},{1,4},{2,3},{2,4},{2,5}的支持度满足要求,因此求得2-频繁项目集:
{1,2},{1,3},{1,4},{2,3},{2,4}
生成3-频繁项目集:
因为{1,2},{1,3},{1,4}除了最后一个元素以外都相同,所以求{1,2},{1,3}的并集得到{1,2,3}, {1,2}和{1,4}的并集得到{1,2,4},{1,3}和{1,4}的并集得到{1,3,4}。但是由于{1,3,4}的子集{3,4}不在2-频繁项目集中,所以需要把{1,3,4}剔除掉。然后再来计算{1,2,3}和{1,2,4}的支持度,发现{1,2,3}的支持度为3/7 ,{1,2,4}的支持度为2/7,所以需要把{1,2,4}剔除。同理可以对{2,3},{2,4}求并集得到{2,3,4} ,但是{2,3,4}的支持度不满足要求,所以需要剔除掉。
因此得到3-频繁项目集:{1,2,3}。
到此频繁项目集生成过程结束。注意生成频繁项目集的时候,频繁项目集中的元素个数最大值为事务集中事务中含有的最大元素个数,即若事务集中事务包含的最大元素个数为k,那么最多能生成k-频繁项目集,这个原因很简单,因为事务集合中的所有事务都不包含(k+1)个元素,所以不可能存在(k+1)-频繁项目集。在生成过程中,若得到的频繁项目集个数小于2,生成过程也可以结束了。
现在需要生成强关联规则:
这里只说明3-频繁项目集生成关联规则的过程:
对于集合{1,2,3}
先生成1-后件的关联规则:
(1,2)—>3, 置信度=3/4
(1,3)—>2, 置信度=3/5
(2,3)—>1 置信度=3/3
(1,3)—>2的置信度不满足要求,所以剔除掉。因此得到1后件的集合{1},{3},然后再以{1,3}作为后件
2—>1,3 置信度=3/5不满足要求,所以对于3-频繁项目集生成的强关联规则为:(1,2)—>3和(2,3)—>1。
算法实现:
/*Apriori算法 2012.10.31*/
#include <iostream>
#include <vector>
#include <map>
#include <string>
#include <algorithm>
#include <cmath>
using namespace std;
vector<string> T; //保存初始输入的事务集
double minSup,minConf; //用户设定的最小支持度和置信度
map<string,int> mp; //保存项目集中每个元素在事务集中出现的次数
vector< vector<string> > F; //存放频繁项目集
vector<string> R; //存放关联规则
void initTransactionSet() //获取事务集
{
int n;
cout<<"请输入事务集的个数:"<<endl;
cin>>n;
getchar();
cout<<"请输入事务集:"<<endl;
while(n--)
{
string str;
getline(cin,str); //输入的事务集中每个元素以空格隔开,并且只能输入数字
T.push_back(str);
}
cout<<"请输入最小支持度和置信度:"<<endl; //支持度和置信度为小数表示形式
cin>>minSup>>minConf;
}
vector<string> split(string str,char ch)
{
vector<string> v;
int i,j;
i=0;
while(i<str.size())
{
if(str[i]==ch)
i++;
else
{
j=i;
while(j<str.size())
{
if(str[j]!=ch)
j++;
else
break;
}
string temp=str.substr(i,j-i);
v.push_back(temp);
i=j+1;
}
}
return v;
}
void genarateOneFrequenceSet() //生成1-频繁项目集
{
int i,j;
vector<string> f; //存储1-频繁项目集
for(i=0;i<T.size();i++)
{
string t = T[i];
vector<string> v=split(t,' '); //将输入的事务集进行切分,如输入1 2 3,切分得到"1","2","3"
for(j=0;j<v.size();j++) //统计每个元素出现的次数,注意map默认按照key的升序排序
{
mp[v[j]]++;
}
}
for(map<string,int>::iterator it=mp.begin();it!=mp.end();it++) //剔除不满足最小支持度要求的项集
{
if( (*it).second >= minSup*T.size())
{
f.push_back((*it).first);
}
}
F.push_back(T); //方便用F[1]表示1-频繁项目集
if(f.size()!=0)
{
F.push_back(f);
}
}
bool judgeItem(vector<string> v1,vector<string> v2) //判断v1和v2是否只有最后一项不同
{
int i,j;
i=0;
j=0;
while(i<v1.size()-1&&j<v2.size()-1)
{
if(v1[i]!=v2[j])
return false;
i++;
j++;
}
return true;
}
bool judgeSubset(vector<string> v,vector<string> f) //判断v的所有k-1子集是否在f中
{
int i,j;
bool flag=true;
for(i=0;i<v.size();i++)
{
string str;
for(j=0;j<v.size();j++)
{
if(j!=i)
str+=v[j]+" ";
}
str=str.substr(0,str.size()-1);
vector<string>::iterator it=find(f.begin(),f.end(),str);
if(it==f.end())
flag=false;
}
return flag;
}
int calculateSupportCount(vector<string> v) //计算支持度计数
{
int i,j;
int count=0;
for(i=0;i<T.size();i++)
{
vector<string> t=split(T[i],' ');
for(j=0;j<v.size();j++)
{
vector<string>::iterator it=find(t.begin(),t.end(),v[j]);
if(it==t.end())
break;
}
if(j==v.size())
count++;
}
return count;
}
bool judgeSupport(vector<string> v) //判断一个项集的支持度是否满足要求
{
int count=calculateSupportCount(v);
if(count >= ceil(minSup*T.size()))
return true;
return false;
}
void generateKFrequenceSet() //生成k-频繁项目集
{
int k;
for(k=2;k<=mp.size();k++)
{
if(F.size()< k) //如果Fk-1为空,则退出
break;
else //根据Fk-1生成Ck候选项集
{
int i,j;
vector<string> c;
vector<string> f=F[k-1];
for(i=0;i<f.size()-1;i++)
{
vector<string> v1=split(f[i],' ');
for(j=i+1;j<f.size();j++)
{
vector<string> v2=split(f[j],' ');
if(judgeItem(v1,v2)) //如果v1和v2只有最后一项不同,则进行连接
{
vector<string> tempVector=v1;
tempVector.push_back(v2[v2.size()-1]);
sort(tempVector.begin(),tempVector.end()); //对元素排序,方便判断是否进行连接
//剪枝的过程
//判断 v1的(k-1)的子集是否都在Fk-1中以及是否满足最低支持度
if(judgeSubset(tempVector,f)&&judgeSupport(tempVector))
{
int p;
string tempStr;
for(p=0;p<tempVector.size()-1;p++)
tempStr+=tempVector[p]+" ";
tempStr+=tempVector[p];
c.push_back(tempStr);
}
}
}
}
if(c.size()!=0)
F.push_back(c);
}
}
}
vector<string> removeItemFromSet(vector<string> v1,vector<string> v2) //从v1中剔除v2
{
int i;
vector<string> result=v1;
for(i=0;i<v2.size();i++)
{
vector<string>::iterator it= find(result.begin(),result.end(),v2[i]);
if(it!=result.end())
result.erase(it);
}
return result;
}
string getStr(vector<string> v1,vector<string> v2) //根据前件和后件得到规则
{
int i;
string rStr;
for(i=0;i<v1.size();i++)
rStr+=v1[i]+" ";
rStr=rStr.substr(0,rStr.size()-1);
rStr+="->";
for(i=0;i<v2.size();i++)
rStr+=v2[i]+" ";
rStr=rStr.substr(0,rStr.size()-1);
return rStr;
}
void ap_generateRules(string fs)
{
int i,j,k;
vector<string> v=split(fs,' ');
vector<string> h;
vector< vector<string> > H; //存放所有的后件
int fCount=calculateSupportCount(v); //f的支持度计数
for(i=0;i<v.size();i++) //先生成1-后件关联规则
{
vector<string> temp=v;
temp.erase(temp.begin()+i);
int aCount=calculateSupportCount(temp);
if( fCount >= ceil(aCount*minConf)) //如果满足置信度要求
{
h.push_back(v[i]);
string tempStr;
for(j=0;j<v.size();j++)
{
if(j!=i)
tempStr+=v[j]+" ";
}
tempStr=tempStr.substr(0,tempStr.size()-1);
tempStr+="->"+v[i];
R.push_back((tempStr));
}
}
H.push_back(v);
if(h.size()!=0)
H.push_back(h);
for(k=2;k<v.size();k++) //生成k-后件关联规则
{
h=H[k-1];
vector<string> addH;
for(i=0;i<h.size()-1;i++)
{
vector<string> v1=split(h[i],' ');
for(j=i+1;j<h.size();j++)
{
vector<string> v2=split(h[j],' ');
if(judgeItem(v1,v2))
{
vector<string> tempVector=v1;
tempVector.push_back(v2[v2.size()-1]); //得到后件集合
sort(tempVector.begin(),tempVector.end());
vector<string> filterV=removeItemFromSet(v,tempVector); //得到前件集合
int aCount=calculateSupportCount(filterV); //计算前件支持度计数
if(fCount >= ceil(aCount*minConf)) //如果满足置信度要求
{
string rStr=getStr(filterV,tempVector); //根据前件和后件得到规则
string hStr;
for(int s=0;s<tempVector.size();s++)
hStr+=tempVector[s]+" ";
hStr=hStr.substr(0,hStr.size()-1);
addH.push_back(hStr); //得到一个新的后件集合
R.push_back(rStr);
}
}
}
}
if(addH.size()!=0) //将所有的k-后件集合加入到H中
H.push_back(addH);
}
}
void generateRules() //生成关联规则
{
int i,j,k;
for(k=2;k<F.size();k++)
{
vector<string> f=F[k];
for(i=0;i<f.size();i++)
{
string str=f[i];
ap_generateRules(str);
}
}
}
void outputFrequenceSet() //输出频繁项目集
{
int i,k;
if(F.size()==1)
{
cout<<"无频繁项目集!"<<endl;
return;
}
for(k=1;k<F.size();k++)
{
cout<<k<<"-频繁项目集:"<<endl;
vector<string> f=F[k];
for(i=0;i<f.size();i++)
cout<<f[i]<<endl;
}
}
void outputRules() //输出关联规则
{
int i;
cout<<"关联规则:"<<endl;
for(i=0;i<R.size();i++)
{
cout<<R[i]<<endl;
}
}
void Apriori()
{
initTransactionSet();
genarateOneFrequenceSet();
generateKFrequenceSet();
outputFrequenceSet();
generateRules();
outputRules();
}
int main(int argc, char *argv[])
{
Apriori();
return 0;
}
测试数据:
7
1 2 3
1 4
4 5
1 2 4
1 2 6 4 3
2 6 3
2 3 6
0.3 0.8
运行结果:
1-频繁项目集:
1
2
3
4
6
2-频繁项目集:
1 2
1 4
2 3
2 6
3 6
3-频繁项目集:
2 3 6
关联规则:
3->2
2->3
6->2
6->3
3 6->2
2 6->3
6->2 3
请按任意键继续. . .
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330