文本挖掘 指的是用来从不同文字来源提取信息的技术。它为何如此重要呢?据普遍估计,在所有与业务有关的信息中,有 80% 的信息是非结构化文本数据和半结构化文本数据。换言之,如果不对这 80% 的信息所代表的大量数据应用文本分析,所有嵌入的业务信息和消费者行为数据都会被浪费。术语文本挖掘 常常被称为文本分析 具有很多的实际意义,比如垃圾过滤、从电子商务网站上的意见和建议中提取信息、在博客和评论网站中进行社交收听和意见挖掘、增强客户服务和电子邮件支持、业务文档的自动化处理、法律领域的电子发现、衡量消费者的偏好、索赔分析和欺诈检测,以及网络犯罪和国家安全应用程序。
文本挖掘类似于数据挖掘,因为它也针对的识别出数据内的有趣模式。虽然手动(而且是高度劳动密集)文本挖掘出现于二十世纪八十年代。在近些年来,对于通过定义搜索引擎结果算法和筛选数据源来发现未知信息而言,文本挖掘领域十分重要。诸如机器学习、数据统计、计算语言学和数据挖掘这样的技术均在这个过程中发挥了重要作用。例如,文本的知识发现目标是使用自然语言处理 (NLP) 从文本、内容和暗示的上下文中检测底层的语义关系。这个过程旨在使用 NLP 进行复制,然后衡量相同类型的语言区别、模式识别以及阅读和处理文本时的理解。
文本挖掘领域中有各种方法。下面将介绍文本挖掘所涉及到的一系列常见步骤和后续步骤。
文本挖掘的第一个步骤是识别出想要分析的基于文本的源,并通过信息检索或选择包含这组文本文件和感兴趣内容的语法库来收集这种材料。扩展 NLP 的部署可以调用 “部分词类标注” 和文本顺序来解析语法(即语汇单元化 文本),并应用 Named Entity Recognition(即确认品牌、人的姓名、地点、常见缩略语等内容的提及)。而迭代的 Filter Stopwords 步骤则涉及禁用词的删除,从而提炼出所需的主题内容。Pattern Identified Entities 能识别电子邮件地址和电话号码,Coreference 则能识别文本内的名词短语以及相关对象,后跟 Relationship, Fact and Event Extraction。通常会生成 N-Grams,它创建一系列连续单词作为术语。最后,执行语义分析,社交媒体侦听和分类工具如今广泛使用采用这种方式来提取对某个对象或主题的态度信息。很多时候,各种映射和绘制功能还提供了可视化,以便进行进一步的准确验证。
文本挖掘软件和应用程序有很多商业和开源选项。IBM 提供了种类繁多且强健的文本挖掘解决方案。利用了 IBM® InfoSphere® BigInsights™ 大数据功能的一种功能强大的方案提供了附加文本分析模块,能够从 InfoSphere BigInsights 集群运行文本分析提取。IBM SPSS® 方案规模和范围都很广泛。对于搜索文档并将它分配给一个主题非常有效的一个工具是 IBM SPSS Modeler,它能提供一个图形界面来执行通常的文本文档分类和分析。另一个产品 IBM SPSS Text Analytics for Surveys 则使用了 NLP,对于分析文档内开放的调查问题非常有用。IBM SPSS Modeler Premium 与 SPSS Text Analytics for Surveys 运行在同一个引擎上,但是可伸缩性更高,能处理一个有助于结构化和非结构化数据集成的综合工作台内文档(PDF、Web 页面、博客、电子邮件、Twitter 提要等)的整个语料库。面向 Facebook 的一个相关的自定义代码节点扩展了 SPSS Modeler Premium 的功能,以便能够直接从 Facebook wall 直接读取数据,并与 SPSS Modeler 内的 Twitter 提要相集成,从而获得多社交媒体渠道观点。
在开源文本挖掘工具中,RapidMiner 和 R 这两个工具最为流行。R 有更大的用户群,它是一种需要源代码的编程语言,有许多算法选择。但可伸缩性一直是 R 的一个问题,所以,对于大型数据集,如果没有变通方案,R 不是一个理想选择。RapidMiner 的用户群较小,但它不要求源代码,并且有一个强大的用户界面 (UI)。而且它是高度可伸缩的,能够处理集群和数据库内编程。IBM 提供了一个将查询内的 R 项目集成在一起的 Jaql R 模块,它允许 MapReduce 作业并行运行 R 计算。
现在我们将简要介绍 NoSQL 和 Structured Query Language (SQL) 选项和技术堆栈的选择过程。当数据源变得难以处理时,正如社交媒体数据中经常出现的情形那样,能够有效集成 Hadoop 和其他功能扩展的开源工具的商业 NoSQL 选项(比如 IBM InfoSphere BigInsights)组合就显得十分必要。图形数据库、关键值和文档存储都是可用的,可基于主要用例做出最佳选择。对文本挖掘和分析感兴趣的公司通常会选择将 Hadoop 并与其他的开源工具相集成,比如 Apache Mahout,这是一种可提供分类、集群和协作过滤的机器学习引擎。Storm 的元组和流可以管理实时分析,操纵 Hadoop 的高延迟性。
在将文本挖掘应用于社交媒体数据时,有一些独特的挑战。社交网络站点、博客和论坛生成的数据属于通常所说的大数据 范畴。数据是未结构化或半结构化的数据,每天会围绕较大品牌生成数千兆字节的数据,而传统的数据库无法有效扩展来支持基于这些数据的实时分析。因此需要提供大数据和 NoSQL 数据库解决方案。
如果没有定期收集并充分存储社交媒体数据,这些数据是很容易遭到破坏。大多数开源社交侦听工具仅存储社交媒体评论历史记录的几天内的记录。Twitter 也是最近才宣布会保存整个数据历史记录,但仅限于由帐户持有人明确发布的评论。通过之前提及的一些更大型的社交数据提供商,比如 Gnip 和 DataSift,以及基于量和调用的应用程序编程接口(API)和其他工具,可以获得这类数据。但是,虽然可以获得这类数据(对于 Twitter),除了那些最大的品牌之外,价格对于一般人而言显得尤为昂贵。
每个社交媒体网站对这个问题的处理方式都是大相径庭的。根据数据的量和数据的特性,可以使用搜索请求和提供 JavaScript Object Notation (JSON) 格式响应,这些响应包含未解析的数据,以便立即包含在一个 MySQL 或 NoSQL 数据库中。
回页首
品牌为文本挖掘提供了不同的目标:
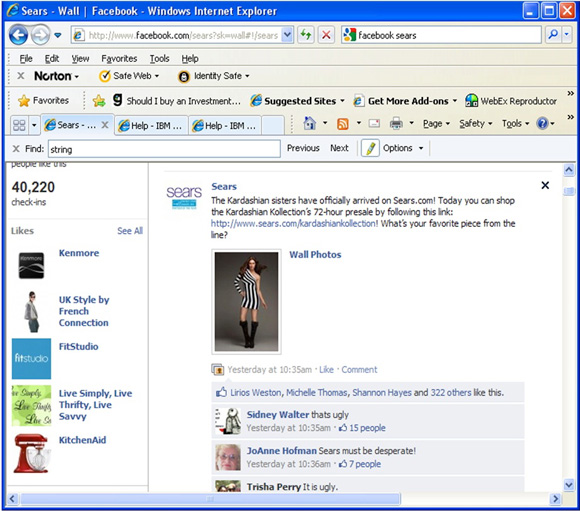
像 Sears 这样的公司,如 示例 1 所示,可能有兴趣在新产品线启动后通过社交媒体评论和 Facebook 页面粉丝的交互来直接跟踪消费者的观点。这样一来,更容易理解围绕图片、产品和启动产品而引起的对话集群的基本反响。通过这种实时的反馈可以实现快速的消息更新和非流行内容的删除,并且 Facebook 的粉丝们成为了实时焦点群,提供了产品特性的即时反馈。
JACT Media 公司的任务是构建品牌和视频游戏玩家之间的关系。该公司提供了一个游戏内的临时设施,在玩家玩常玩游戏的同时向玩家展示各种具有针对性的、已安排好的内容。玩家赢得 JACT 虚拟货币,而这些 JACT BUX 可兑换奖品,包括虚拟的和可下载的商品。玩家在 Facebook 页面或 Twitter 上与 JACT 交互,并频繁在游戏论坛经常提及 JACT BUX。这种原始的评论数据可从各种来源获取,并且可以存储个人级别的评论和偏好。比如,如果玩家对某个视频游戏特别感兴趣,或是在 tweet 上提到了自己的奖品,那么基于特定游戏的游戏内目标锁定和奖品类型可能比随机的奖励更能促进忠诚度的增加。
超市也能够使用社交媒体数据来识别更为有价值的购物者、对客服的印象、商店的环境、产品的偏好、包装的偏好和定价。将这类信息与 Twitter 或移动设备提供的位置数据汇总在一起,超市就能从某个角度进行定位,量身定制购物体验。而这对于库存、定价、广告、个人数字和邮寄优惠券等都有影响。
第一个示例是一个 SPSS Modeler Premium 用例。在此场景中,启动了一个新的产品线,该公司有兴趣跟踪社会媒体数据中的消费者反应。SPSS Modeler Premium Facebook 节点被用来跟踪 Sears Facebook 页面上的新 Kardashian 产品线,如 图 1 所示。
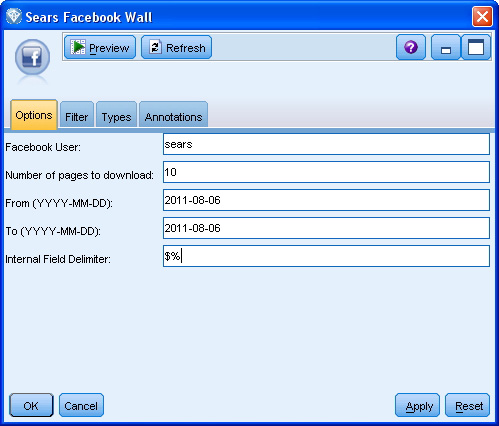
在跟踪和分析评论数据的第一个步骤中,涉及到要求用户指定用户名以及在 SPSS Modeler Premium Facebook 节点中用于评论的页面和线程的数量,如 图 2 所示。
然后,会从 Sears Facebook 页面提取评论数据,并在 SPSS Modeler 中使用它,如 图 3 所示。
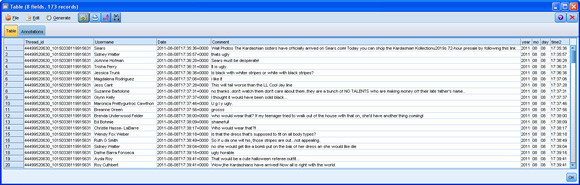
(请查看 图 3 的大图。)
下一个步骤涉及到添加过滤器和执行概念提取,从而形象地描述围绕该品牌的内容类别。这个用户友好的图形 UI 可在整个过程中引导用户,并且不需要使用 API 从 Twitter 或 Facebook 中提取社交数据。其结果是获得一个容易理解的概念地图,并了解连接线的厚度所代表的概念集群的敏感性,如 图 4 所示。
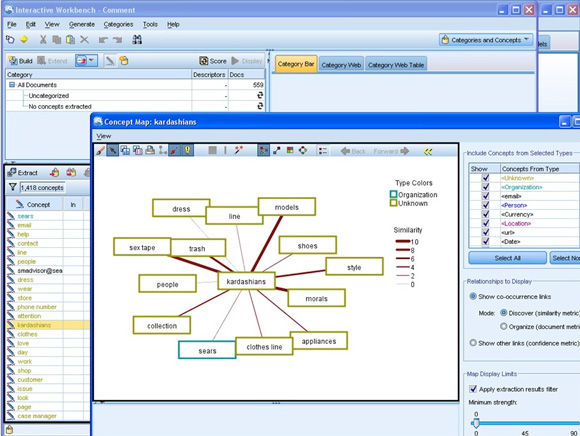
(请查看图 4 的大图。)
下列的社交媒体数据集市组装过程描述了一个简单的手动文本挖掘过程。在这个示例中,我们希望使用借助了 SPSS Statistics Base 的文本挖掘来获取和存储来自社交媒体数据的各种产品偏好。本例包括一个从 Twitter 和 Facebook 提取超市品牌数据的分步指南。过程架构如 图 5 所示。
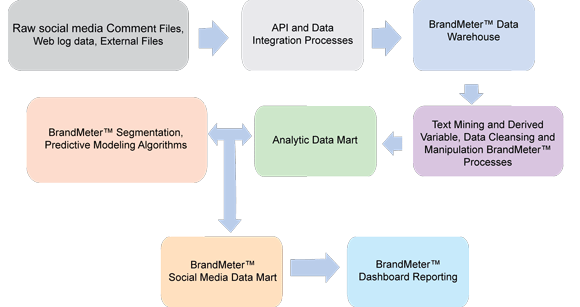
(请查看 图 5 的大图。)
第一步是确定感兴趣的品牌。设置一个例程来通过一个 API 过程收集与品牌相关的提及。这是通过 图 6 中所示的搜索请求来完成的,结果是以 JSON 格式返回的。一个 JSON 库会解析数据,并将每个记录分成多个字段,这些字段包含了像用户 ID、数据和未处理的文本消息评论这样的信息。然后,此数据会存储在一个数据库中,并且可供文本挖掘使用。

(请查看 图 6 的大图。)
这个简化的文本挖掘练习的目标是确定特定消费者产品偏好和消费模式。然后,此信息会存储在社交媒体数据集市在。对于这个特定示例,假设您想要确定蔬菜玉米的所有消费者。图 7 显示了 Character Index 函数的使用情况,该函数可识别原始评论数据中使用了单词 corn 的所有实例。
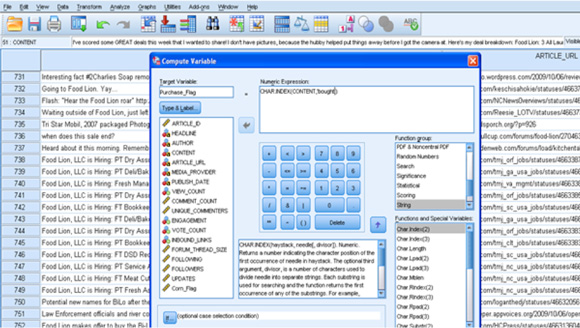
(请查看 图 7 的大图。)
这些结果还需要进一步的过滤,并且需要通过各种迭代来应用禁止词,从而提高分类的准确性。通过应用像 popcorn、candy corn、corndog 和 corn syrup 这样的禁止词,并限制实例为四个字符的组合,可以让玉米产品的识别更准确一些。然后可以使用 'corn_consumer_flag'=1 在数据库中标记这些用户名,并在未来市场营销活动中,为特定于玉米的产品和食品而选中它们。(请查看 图 8。)
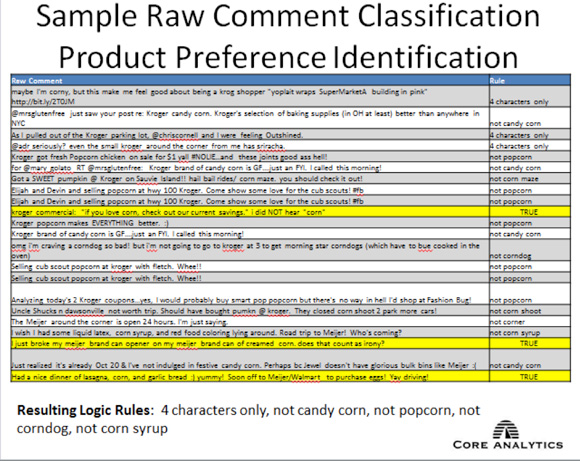
在获得详尽的列表之后,您就可以执行用户 ID 聚合,并填充表来捕获产品购买、包装方面的评论和其他存储了个人级别消费者行为的变量。在本例中,原始社交媒体数据存储在一个 NoSQL 数据库内,而所得到的产品偏好标志则存储在一个 MySQL 数据集市内,其中用户 ID 是一个主匹配键(参见 图 9)。
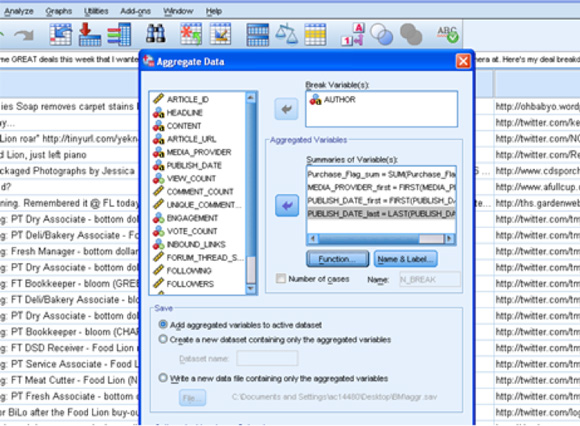
文本挖掘愈来愈流行,因为很多公司评估使用社交媒体作为一种市场营销和品牌交互渠道的潜在回报。许多公司都急于实现大数据存储方案,以便存储未结构化的数据,并将这些数据与传统的交易类型数据相集成。社交媒体评论和与品牌相关的交互数据提供了对消费者偏好的洞察,可以利用这些偏好信息来设计相关的产品特性,并采用与消费者需求和预期相吻合的方式进行市场营销。如果为了获得更深入的品牌体验定制而将这类个人级别的行为和偏好数据存储在社交媒体数据集市中,那么这将会将信息置于公司的手中,公司可以使用这些信息来充实消费者与品牌的关系,促使消费者参与其品牌体验的自我管理。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27






