大数据驱动下的微博社会化推荐
不同于搜索,“推荐”通常不是独立的互联网产品,而是互联网产品的核心组件,为该产品的核心目标服务,比如电商网站的推荐是为了达成更多商品交易。微博推荐同样如此,其存在价值就是通过梳理和优化用户关系网络、打通内容传播链条、引爆信息定向传播,从而实现加速高价值用户关系构建、优质内容传播和商业化营收等微博核心目标。
明确了推荐的角色和定位后,设计一个合适的推荐系统还需要系统了解微博的数据特点。因为只有清楚数据的特点,才能更有针对性地设计推荐系统产品、架构和算法。


微博是一个以内容消费为核心的偏弱关系社交网络,关系的构建多是依托于兴趣。它是半开放的,用户看到的大部分内容,来自于2层关注构建的网络。而对社交网络而言,用户关系网络结构、内容信息、用户是其数据三要素,因此下文也主要会围绕这3个要素对微博数据特点进行阐述。
用户关系网络结构:呈现海量、社会化、兴趣弱关系、半开放等4个方面的特点。微博关系网络拥有超过6亿个节点、1000多亿条边,每天有海量信息通过这张网络传输。它就像一个虚拟社会,带着社会化分工、去中心化、非对等性的属性;每个用户都有自己的真实身份和角色,比如橙V、蓝V、普通用户,承担不同的职责并具备不同的话语权,在内容的生产、传播、消费的过程中,扮演着不同角色。
内容信息:微博的信息是简短、丰富而碎片化的,同时存在着UGC和媒体内容,具备极快的传播速度。微博由点及面和Timeline的Feed流设计,使其具备极好的信息传播能力,这是微博的优势,但同样也会引发问题——飞速的传播让旧信息很快被淹没掉,不管其价值多寡。因此对于推荐系统来说,其主要目标就是让优质信息沉淀下来并获得更多的曝光机会,这也是之所以要做“错过的微博”的原因。
用户:微博用户具备个性化的行为和偏好,承担着良好的社会化分工角色。同时,微博通过基于UID的账号体系来识别用户,记录历史数据并存储关系数据,从而精确地了解每一个用户,也为后面个性化推荐打下良好的基础。
微博推荐的设计主要包括产品、架构、算法3个方面,下面首先了解产品的设计思路。
产品设计
微博自然推荐分为用户和内容推荐两个部分。
用户推荐

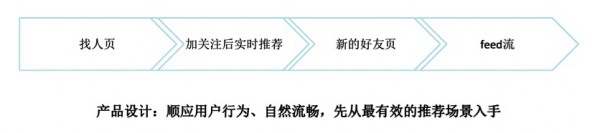
用户推荐的产品目标是优化用户关系网络结构,在用户推荐产品设计实践中主要有两点经验值得和大家分享。
效果衡量指标。效果衡量指标是连接产品定位和算法优化方向的桥梁,而这也是产品设计中不断思考和摸索的方向。初始时我们直观地认为,如果用户喜欢推荐结果就会产生较高的点击率,从而将CTR作为衡量指标,但随后这个思路就被否定。用户推荐的初衷是关系达成而不是即时愉悦用户,于是衡量指标被调整为RPM(Relation per Thousand Impression,即千次曝光的用户关系达成量)。在一段时间后我们开始反思一个问题:用户关系达成的意义是什么,用户关系量是否是越多越好呢?答案显然是否定的,受限于精力,推荐必须帮助用户梳理关系网络结构,让用户可以简单地构建高价值的用户关系,从而让用户可以更好地消费内容以及更容易地进行社交互动,因此衡量指标衍生为关系达成后的互动率和用户行为量。
产品设计原则。推荐是用户预期之外的非自然流量,应该顺应用户的行为,以自然流畅的方式展现给用户。因此,推荐必须从最有效的主动场景入手,比如微博找人页用户带有明显关注新用户的意图,而这里展示用户推荐正好满足需求;而Feed流的浏览目的是内容消费,推荐新用户会打断内容消费的流畅性,效果很差。
内容推荐
内容推荐的产品目标是加速优质信息传播以满足内容消费需求,“错过的微博、赞过的微博、正文页相关推荐、热点话题”则是其中具有代表性的内容推荐产品,这里会重点介绍下“错过的微博”的设计思路。
“错过的微博”前身是一个叫做“智能排序“的推荐产品,主要用于解决信息过载情况下的排序问题。正常情况下,微博用户平均每天会接收到2000+条Feed,而真正阅读的内容不超过200条,那么怎样才能让用户看到更多高价值信息,减少低质内容曝光,从而提升内容消费体验,这正是产品的设计目的。“智能排序”采用了简单直接的设计思路:Feed流按价值高低整体排序,这样做存在两个问题:
定义及量化信息对用户的价值。因为用户对信息价值的理解方式千奇百怪,因此不论如何调整算法总会让部分用户不满意。
信息价值和时间顺序的平衡。整体重排序会让微博丢失Timeline的排列属性,从而新的信息有可能排在旧的后面,而时间序是保证微博传播能力和信息新鲜度的关键。
所以“智能排序”不是一个优雅的解决方案,而后通过数据分析发现:用户错过的90+%信息中,只有部分内容是对用户具有极高价值且不容错过的,所以这里无需对未读Feed全排序,只需要将最高价值的信息找出来并推荐给用户,其它的Feed仍按正常时间序排列。这样做一方面可以让Feed流整体上符合Timeline的排序,用户感觉自然流畅;另一方面,与用户对最高价值的信息认知上比较接近,算法效果比较理想。产品推出后,用户认可度很高,互动率远远高于普通Feed。
架构设计
推荐系统的架构设计,包含在线服务,以及数据存储、传输、计算两个部分。
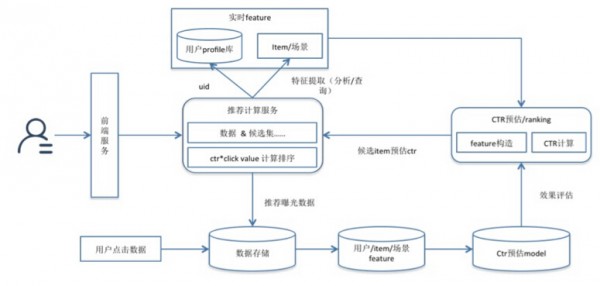
首先看数据部分,整体架构分为Online和Offline两个部分,其中Online部分通过Kafka/Scribe把用户的即时行为和发布内容传输到流式计算系统Storm中做即时处理,处理的结构化数据存储到Redis中。而Offline的数据,主要通过Hadoop平台做基础的存储,然后通过Spark/MapReduce等分布式计算后,将直接应用到在线服务的数据存储到HBase/Lushan/Redis等数据库中,亦或是存放到在线服务的本地文件。
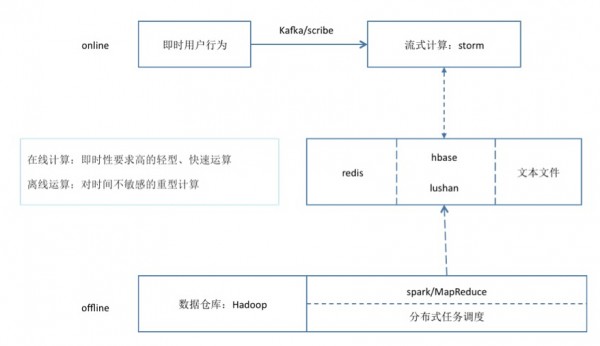
接下来看在线服务的架构设计,如图所示,这里通过UVE(Uniform Value Estimate)来分发非自然流量——广告、运营、推荐。推荐经过应用层接入后,会进入在线服务的核心处理模块lab_common_so,这个模块主要实现了3项功能。
微博推荐候选集非常庞大,架构设计中分为初选与精选两个模块,精选模块位于lab_common_so中,而初选由独立的功能模块来承担,来源于3个维度:
用于精选排序的ctr预估模型,基于Hadoop平台数据,通过Spark来分布式训练。

算法设计
微博推荐的算法体系如图所示,包含4层:数据挖掘、基础算法、核心算法、混合算法技术。
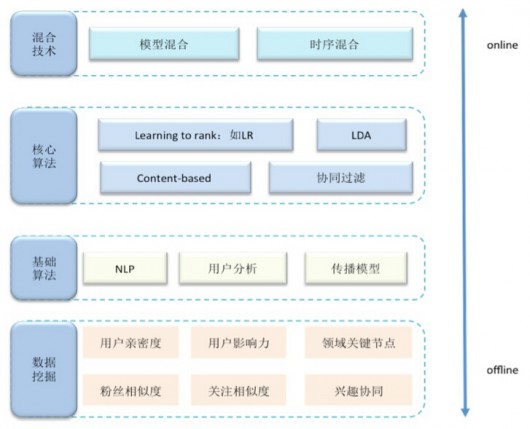
先看数据挖掘部分,这里基于微博社交数据建模来完成用户亲密度、用户影响力、领域关键节点、粉丝相似度、关注相似度、兴趣协同的量化计算,从而数据化地描述微博社交网络、用户关系、用户兴趣和能力,并将其作为在线推荐计算的中间结果数据。
基础算法中,都是大家比较熟知的NLP、用户分析、传播模型等算法,不做过多介绍。算法设计和实践的重点是核心算法和混合技术,接下来会逐个介绍:
协同过滤是经典的推荐算法,在微博中广泛应用,共使用过如下4种:
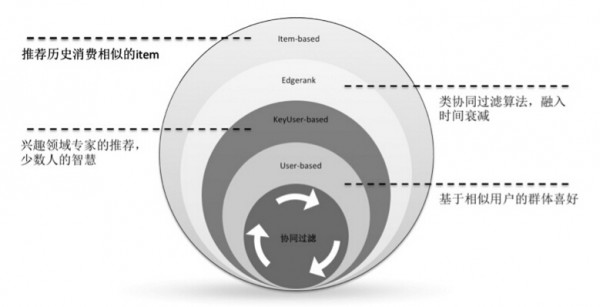
其中,user-based协同的应用最为广泛。微博借助UID账号体系,经过多年积累,存储了充足的用户数据,user-based CF结果精确,且有良好的推荐理由;相对而言,微博信息的时效性很强,item-based协同效果不太理想。此外,微博具有良好的社会化属性,拥有大量各个领域的专家和关键节点,从而在一些对专业知识要求较高的场景,基于keyUser-based的协同具有良好的效果。在智能排序研发时曾借鉴Facebook的经验,实践过Edgerank算法(加一些公式描述),是相对经典的协同过滤,引入了时间衰减因素,来提升推荐结果的时效性。
相关性推荐content-based
Content-based算法广泛应用在内容推荐中,这里将以微博正文页相关推荐为例进行介绍,如图所示分为在线和离线两个部分。
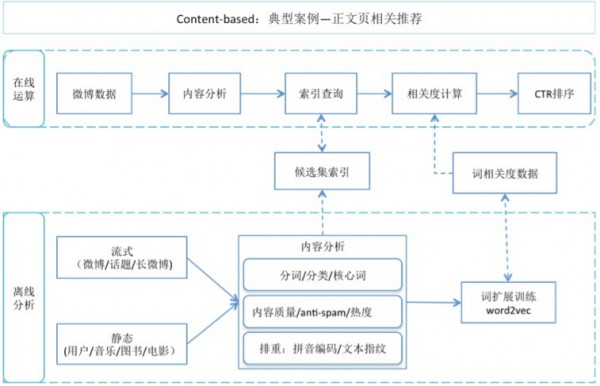
离线部分,多种候选物料(如微博、电影)经过NLP结构化处理后选取优质候选,以关键词、分类为key构建索引。其中微博、话题、长微博的候选集索引通过流式计算产生,可以做到分钟级的实时更新。此外,由于微博内容简短,可提取的有效关键词数量有限,为了提升推荐的覆盖率和准确度会以优质微博、长微博、话题为训练语料,离线开展词扩展、词聚类计算(基于word2vec)则用于在线相关性计算的辅助。
在线计算,用户访问正文页后,推荐服务会基于Storm流式计算的分类、关键词向量结果查询索引获取推荐候选集,并计算微博正文同各个推荐候选集的相关度,选择相关而不相似的候选集开展ctr/RPM计算,并由此排序得到推荐推荐结果呈现给用户。
排序模型
基于机器学习的Learning to ranking是推荐中常用解决排序问题的算法技术,微博推荐的排序模型采用经典的LR模型。
在线计算时的feature向量会随着推荐服务日志记录下来,尤其是场景相关的feature,并通过特征工程的ETL框架将各类产品汇集和处理以生成训练样本,开展模型训练。基础feature分为用户、item、场景3个维度,而实际应用的feature多为交叉特征。
另外,对于多种推荐候选集共存的场景,这里通过ctr*click_value的方式来解决综合排序问题,click_value的计算主要考虑候选集结果对用户产生的长远影响,如用户阅读一篇长文章、关注一个新用户的click_value要远高于点击一个相关微博。
时序混合
微博推荐会随着用户行为而实时调整推荐结果,这里通过时序混合算法策略来达成这一目的,在不同的阶段采用不同的算法。如图是一个正文页的例子。
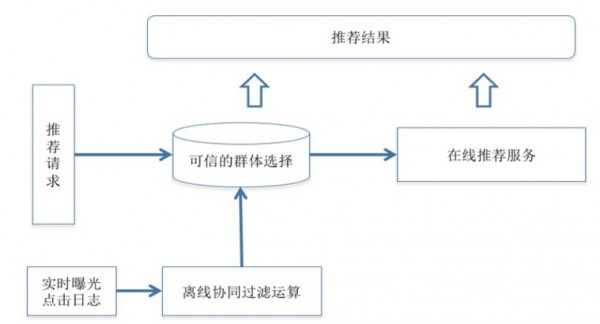
在实际场景中,很多用户会先后访问同一个正文页,在初始曝光阶段,系统会采用content-based 算法给出推荐结果,而正文页得到了充分曝光和足够多可信用户的互动行为后,会采用协同过滤的算法计算推荐结果,并呈现给后续访问的用户。这个算法思路基于一个朴素的假设:访问同一个正文页的用户存在相似的即时兴趣,从而这里可以采用user-based CF并结合贝叶斯平滑来选择点击率最好的item做好推荐结果,计算方式如下。

其中为用户i的历史点击率,用以消除不同用户的点击率偏差。
单一的算法模型都存在局限性,为了解决复杂的社会化推荐问题,通常会采用模型融合的方法来实现模型间的优势互补,提供最佳的推荐结果。分层模型融合和分片线性模型是微博推荐中应用较多的。
分层模型融合,即上一层模型的输出作为下一层模型的feature输入,通常采用多层LR或LR+GBDT的方式,如图所示。
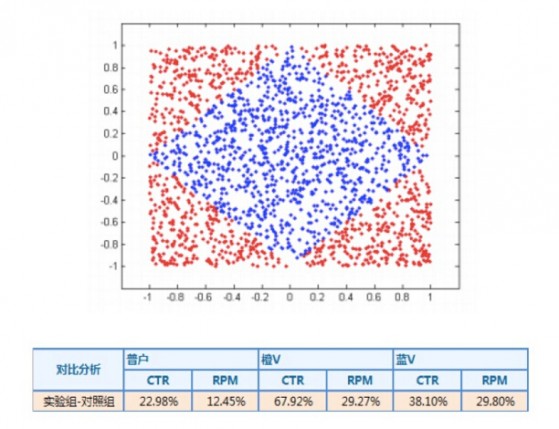
分片线性模型:由于线性模型的局限性,很多时候无法学到泛化效果好的非线性关系,为了应对各类跨平台、分场景的推荐问题,我们引入了分片拟合、分而治之的分片线性模型,即多个模型解决同一个问题,每个模型应用于其效果最好的条件流量。以微博用户推荐为例,我们从用户类型维度将空间/流量划分为3个局部区域——蓝V、橙V和普通用户,它们各有一个线性预测模型来分片融合给出推荐结果,取得了很好的效果。另外在微博广告实践中也从平台维度划分流量空间并采用了分片线性模型,从而大幅提升了CTR预估的精准性。
商业化设计—商业推荐
经过多年的发展,微博积累了大量高价值用户,如明星、领域专家,他们都积累了丰富的社交资产,具有一呼百应的社交影响力。同时,微博上又有大量的企业用户,希望通过微博平台推广和营销,但自身用户关系网络狭小,从而内容缺乏自我传播能力,希望能快速构建粉丝关系网络,借助高价值用户的关系网络来推广自己的产品。另外,很多用户都存在偶发的自我推广诉求,希望自己的信息被所有的粉丝看到,甚至能曝光给潜在粉丝,但微博信息更新速度快,信息又很容易被淹没掉。
推荐可以很好地解决上述问题,满足企业和个人的推广需求,来通过“连接”实现商业化变现。粉丝头条和涨粉助手是两个最有代表性的微博商业推荐产品。
涨粉助手重点解决高价值粉丝关系网络的快速构建问题,而粉丝头条专注于企业推广信息的精准触达和有效曝光,并通过将名人、关键节点转化为企业的产品代言人,来达成高影响力用户的社交资产变现和企业用户的营销需求,进而将名人的影响力引渡到品牌上,拉近明星、品牌、用户的距离。在社交网络中,广告的效果与信息发布者有着重要的关系,因为用户影响力不同带来的信任度也就不同。
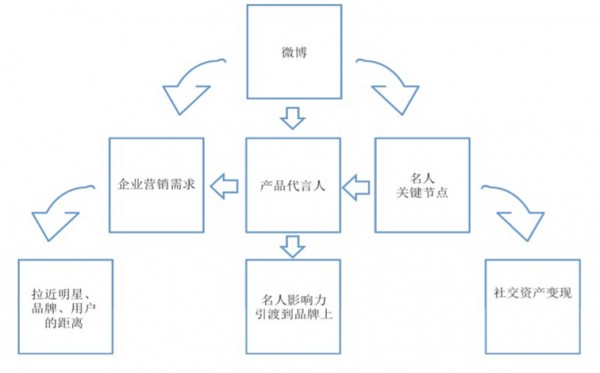
通过系统性的产品设计来实现特定微博信息的爆炸性定向传播,其实现机制如图所示。
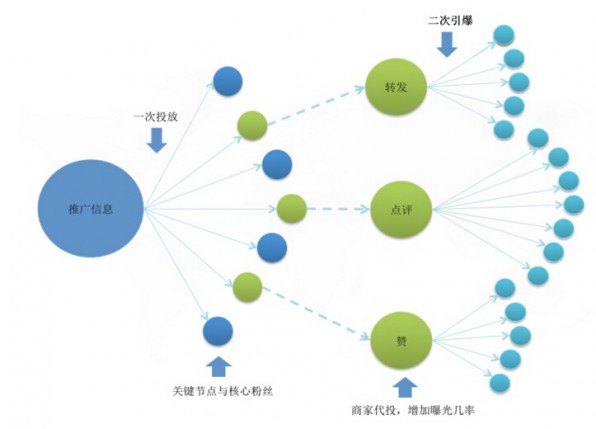
引爆过程包含两次粉丝头条投放:第一次将推广内容投放给关键节点与核心粉丝,等他们产生转、评、赞等行为后,再代投这些互动内容,借助关键节点的粉丝资产来定向推广自己的产品以实现二级粉丝关系网络中的扩散传播,星火燎原。
在算法实现维度会重点介绍最关键的算法模块:个性化定价与分包。这里主要为客户提供了4个档位的粉丝头条投放包,而算法需要解决的是提升用户的购买率和总体收入,并保障平台流量变现效率和客户ROI之间的均衡。
算法设计的关键是先定价、后分包,首先通过客户心理价格和购买力建模,计算不同用户在面对不同价格时的购买概率,进而计算最佳的呈现价格:
而分包是在特定价格下需要推广给多少潜在粉丝,即综合考虑订单复购率、客户ROI的最优eCPM计算:max{eCPM*(1+P(复购率|eCPM,ROI))。
推荐技术诞生于上世纪80年代,而真正的繁荣却源自于大数据的推动。本文从推荐的定位、微博的数据特点、数据驱动的系统(产品/架构/算法)设计、推荐的商业化等4个方面全面阐述微博的社会化推荐实践。在这个过程中,架构设计和数据存储建立在成熟的大数据工具和解决方案上,产品和算法设计则大量应用了大数据的思路和技术。通过挖掘社会化数据宝藏,量化“连接”价值,寻找高价值“连接”,为用户呈现优质的个性化推荐结果。最后详细描述了微博推荐商业化变现的构想和实践,证明推荐在社交网络中依然具备良好的商业价值,而不仅仅是电商网站。微博是社会化资产变现的开拓者,希望我们的经验能够对读者有所启发和帮助,并欢迎大家为我们提出宝贵的建议。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
CDA持证人简介 刘伟,美国 NAU 大学计算机信息技术硕士, CDA数据分析师三级持证人,现任职于江苏宝应农商银行数据治理岗。 学 ...
2025-04-21持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28






