机器学习常用算法(LDA,CNN,LR)原理简述
1.LDA
LDA是一种三层贝叶斯模型,三层分别为:文档层、主题层和词层。该模型基于如下假设:
1)整个文档集合中存在k个互相独立的主题;
2)每一个主题是词上的多项分布;
3)每一个文档由k个主题随机混合组成;
4)每一个文档是k个主题上的多项分布;
5)每一个文档的主题概率分布的先验分布是Dirichlet分布;
6)每一个主题中词的概率分布的先验分布是Dirichlet分布。
文档的生成过程如下:
1)对于文档集合M,从参数为β的Dirichlet分布中采样topic生成word的分布参数φ;
2)对于每个M中的文档m,从参数为α的Dirichlet分布中采样doc对topic的分布参数θ;
3)对于文档m中的第n个词语W_mn,先按照θ分布采样文档m的一个隐含的主题Z_m,再按照φ分布采样主题Z_m的一个词语W_mn。

因此整个模型的联合分布,如下:

对联合分布求积分,去掉部分隐变量后:

用间接计算转移概率可以消除中间参数θ和φ,所以主题的转移概率化为:

这样我们就可以通过吉布斯采样来进行每轮的迭代,迭代过程即:首先产生于一个均匀分布的随机数,然后根据上式计算每个转移主题的概率,通过累积概率判断随机数落在哪个new topic下,更新参数矩阵,如此迭代直至收敛。
2.CNN
2.1 多层感知器基础
单个感知器的结构示例如下:

其中函数f为激活函数,一般用sigmoid函数。
将多个单元组合起来并具有分层结构时,就形成了多层感知器模型(神经网络)。下图是一个具有一个隐含层(3个节点)和一个单节点输出层的神经网络。

2.2 卷积神经网络
2.2.1 结构特征
在图像处理中,往往把图像表示为像素的向量,比如一个1000×1000的图像,可以表示为一个〖10〗^6的向量。在上述的神经网络中,如果隐含层数目与输入层一样,即也是〖10〗^6时,那么输入层到隐含层的参数数据为〖10〗^12,这样就太多了,基本没法训练。因此需要减少网络的参数。
卷积网络就是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性。这些良好的性能是网络在有监督方式下学会的,网络的结构主要有稀疏连接和权值共享两个特点,包括如下形式的约束:
1)特征提取。每一个神经元从上一层的局部接受域得到输入,因而迫使它提取局部特征。一旦一个特征被提取出来,只要它相对于其他特征的位置被近似地保留下来,它的精确位置就变得没有那么重要了。
2)特征映射。网络的每一个计算层都是由多个特征映射组成的,每个特征映射都是平面形式的,平面中单独的神经元在约束下共享相同的权值集。
3)子抽样。每个卷积层后面跟着一个实现局部平均和子抽样的计算层,由此特征映射的分辨率降低。这种操作具有使特征映射的输出对平移和其他形式的变形的敏感度下降的作用。
在一个卷积网络的所有层中的所有权值都是通过有监督训练来学习的,此外,网络还能自动的在学习过程中提取特征。
一个卷积神经网络一般是由卷积层和子抽样层交替组成。下图是一个例子:

输入的图片经过卷积层,子抽样层,卷积层,子抽样层之后,再由一个全连接成得到输出。
2.2.2 卷积层
卷积层是通过权值共享实现的。共享权值的单元构成一个特征映射,如下图所示。

在图中,有3个隐层节点,他们属于同一个特征映射。同种颜色的链接的权值是相同的,这里仍然可以使用梯度下降的方法来学习这些权值,只需要对原始算法做一些小的改动,共享权值的梯度是所有共享参数的梯度的总和。
2.2.3 子抽样层
子抽样层通过局部感知实现。一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。如下图所示:左图为全连接,右图为局部连接。

3.LR
线性回归模型,一般表达为h_θ (x)= θ^T X 形式,输出域是整个实数域,可以用来进行二分类任务,但实际应用中对二分类问题人们一般都希望获的一个[0,1]范围的概率值,比如生病的概率是0.9或者0.1,sigmoid函数g(z)可以满足这一需求,将线性回归的输出转换到[0,1]。

利用g(z),可以获取样本x属于类别1和类别0的概率p(y = 1 |x,θ),p(y = 0|x,θ),变成逻辑回归的形式:

取分类阈值为0.5,相应的决策函数为:

取不同的分类阈值可以得到不同的分类结果,如果对正例的判别准确性要求高,可以选择阈值大一些,比如 0.6,对正例的召回要求高,则可以选择阈值小一些,比如0.3。
转换后的分类面(decision boundary)与原来的线性回归是等价的

3.1 参数求解
模型的数学形式确定后,剩下就是如何去求解模型中的参数。统计学中常用的一种方法是最大似然估计,即找到一组参数,使得在这组参数下,我们的数据的似然值(概率)越大。在逻辑回归模型中,似然值可表示为:

取对数可以得到对数似然值:

另一方面,在机器学习领域,我们更经常遇到的是损失函数的概念,其衡量的是模型预测的误差,值越小说明模型预测越好。常用的损失函数有0-1损失,log损失,hinge损失等。其中log损失在单个样本点的定义为:

定义整个数据集上的平均log损失,我们可以得到:

即在逻辑回归模型中,最大化似然函数和最小化log损失函数实际上是等价的。对于该优化问题,存在多种求解方法,这里以梯度下降的为例说明。梯度下降(Gradient Descent)又叫最速梯度下降,是一种迭代求解的方法,通过在每一步选取使目标函数变化最快的一个方向调整参数的值来逼近最优值。基本步骤如下:
选择下降方向(梯度方向, )
)
选择步长,更新参数
重复以上两步直到满足终止条件。
3.2 分类边界
知道如何求解参数后,我们来看一下模型得到的最后结果是什么样的。很容易可以从sigmoid函数看出,取0.5作为分类阈值,当  时,y=1,否则 y=0。
时,y=1,否则 y=0。 是模型隐含的分类平面(在高维空间中,一般叫做超平面)。所以说逻辑回归本质上是一个线性模型,但这不意味着只有线性可分的数据能通过LR求解,实际上,可以通过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。下面两个图的对比说明了线性分类曲线和非线性分类曲线(通过特征映射)。
是模型隐含的分类平面(在高维空间中,一般叫做超平面)。所以说逻辑回归本质上是一个线性模型,但这不意味着只有线性可分的数据能通过LR求解,实际上,可以通过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。下面两个图的对比说明了线性分类曲线和非线性分类曲线(通过特征映射)。
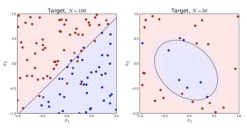
左图是一个线性可分的数据集,右图在原始空间中线性不可分,但是在特征转换 [x1,x2]=>[x1,x2,x21,x22,x1x2] 后的空间是线性可分的,对应的原始空间中分类边界为一条类椭圆曲线
3.3 Word2Vec
Word2Vec有两种网络模型,分别为CBOW模型(Continuous Bag-of-Words Model)和Sikp-gram模型(Continuous Skip-gram Model)。

两个模型都包含三层:输入层、投影层和输出层。其中,CBOW模型是在已知当前词w(t)的上下文w(t-2)、w(t-1)、w(t+1)、w(t+2)的情况下来预测词w(t),Skip-gram模型则恰恰相反,它是在已知当前词w(t)的情况下来预测当前词的上下文w(t-2)、w(t-1)、w(t+1)、w(t+2)。例如,“今天/天气/好/晴朗”,而当前词为“天气”。CBOW模型是预测“今天”、“好”、“晴朗”之间出现“天气”的概率,而Skip-gram模型是预测“天气”的周围出现“今天”、“好”、“晴朗”三个词的概率。
CBOW模型通过优化如下的目标函数来求解,目标函数为一个对数似然函数。

CBOW的输入为包含Context(w)中2c个词的词向量v(w),这2c个词向量在投影层累加得到输出层的输出记为X_w。输出层采用了Hierarchical Softmax的技术,组织成一棵根据训练样本集的所有词的词频构建的Huffman树,实际的词为Huffman树的叶子节点。通过长度为  的路径
的路径  可以找到词w,路径可以表示成由0和1组成的串,记为
可以找到词w,路径可以表示成由0和1组成的串,记为 。Huffman数的每个中间节点都类似于一个逻辑回归的判别式,每个中间节点的参数记为
。Huffman数的每个中间节点都类似于一个逻辑回归的判别式,每个中间节点的参数记为  。那么,对于CBOW模型来说,有:
。那么,对于CBOW模型来说,有:
那么,目标函数为:

那么通过随机梯度下降法更新目标函数的参数θ和X,使得目标函数的值最大即可。
与CBOW模型类似,Skip-gram通过优化如下的目标函数来求解。

其中:

那么,Skip-gram的目标函数为:

通过随机梯度下降法更新目标函数的参数θ和v(w),使得目标函数的值最大即可。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330