Python中的缺失值及其处理
缺失值处理用到的主要工具为 Numpy 库和 Pandas库中的有关函数,要导入 Numpy 和 Pandas:
>>>import numpy as np
>>>import pandas as pd
在 Python 中,特殊的常量 None 通常被理解为缺失值的一种,我们构建了一个包含有 None 的 Numpy 数组 vals1:
>>>vals1 = np.array([1, None, 3, 4])
>>>vals1
array([1, None, 3, 4], dtype=object)
>>>for dtype in ['object', 'int']:
print("dtype =", dtype)
%timeit np.arange(1E6, dtype=dtype).sum()
print()for dtype in ['object', 'int']:
print("dtype =", dtype)
%timeit np.arange(1E6, dtype=dtype).sum()
print()
dtype = object10 loops, best of 3: 78.2 ms per loopdtype = int100 loops, best of 3: 3.06 ms per loop
>>>vals1.sum()
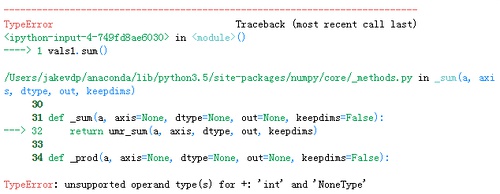
可以看到,当我们的数组中存在缺失值 None 时,我们无法完成简单的求和运算,并且会出现程序报错。
运用 Numpy 库,我们可以用另一种方式生成缺失值,即使用 np.nan:
>>>vals2 = np.array([1, np.nan, 3, 4])
>>>vals2.dtype
dtype('float64')
>>>1 + np.nan
nan
>>>0 * np.nan
nan
可以发现,np.nan 虽然也不能参与简单的计算,但不会出现程序报错的情况,我们得到的结果将为 nan。
同时,Numpy 库还专门为我们准备了用于处理 nan 值的特殊函数 nansum、nanmin 以及 nanmax 等:
>>>vals2.sum(), vals2.min(), vals2.max()
(nan, nan, nan)
>>>np.nansum(vals2), np.nanmin(vals2), np.nanmax(vals2)
(8.0, 1.0, 4.0)
在 Pandas 序列中,不论我们生成的缺失值是 None 还是 nan,都会被转化为 NaN 的形式:
>>>pd.Series([1, np.nan, 2, None])
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330