Python增量循环删除MySQL表数据的方法
有一业务数据库,使用MySQL 5.5版本,每天会写入大量数据,需要不定期将多表中“指定时期前“的数据进行删除,在SQL SERVER中很容易实现,写几个WHILE循环就搞定,虽然MySQL中也存在类似功能,怎奈自己不精通,于是采用Python来实现
话不多少,上脚本:
# coding: utf-8
import MySQLdb
import time
# delete config
DELETE_DATETIME = '2016-08-31 23:59:59'
DELETE_ROWS = 10000
EXEC_DETAIL_FILE = 'exec_detail.txt'
SLEEP_SECOND_PER_BATCH = 0.5
DATETIME_FORMAT = '%Y-%m-%d %X'
# MySQL Connection Config
Default_MySQL_Host = 'localhost'
Default_MySQL_Port = 3358
Default_MySQL_User = "root"
Default_MySQL_Password = 'roo@01239876'
Default_MySQL_Charset = "utf8"
Default_MySQL_Connect_TimeOut = 120
Default_Database_Name = 'testdb001'
def get_time_string(dt_time):
"""
获取指定格式的时间字符串
:param dt_time: 要转换成字符串的时间
:return: 返回指定格式的字符串
"""
global DATETIME_FORMAT
return time.strftime(DATETIME_FORMAT, dt_time)
def print_info(message):
"""
将message输出到控制台,并将message写入到日志文件
:param message: 要输出的字符串
:return: 无返回
"""
print(message)
global EXEC_DETAIL_FILE
new_message = get_time_string(time.localtime()) + chr(13) + str(message)
write_file(EXEC_DETAIL_FILE, new_message)
def write_file(file_path, message):
"""
将传入的message追加写入到file_path指定的文件中
请先创建文件所在的目录
:param file_path: 要写入的文件路径
:param message: 要写入的信息
:return:
"""
file_handle = open(file_path, 'a')
file_handle.writelines(message)
# 追加一个换行以方便浏览
file_handle.writelines(chr(13))
file_handle.close()
def get_mysql_connection():
"""
根据默认配置返回数据库连接
:return: 数据库连接
"""
conn = MySQLdb.connect(
host=Default_MySQL_Host,
port=Default_MySQL_Port,
user=Default_MySQL_User,
passwd=Default_MySQL_Password,
connect_timeout=Default_MySQL_Connect_TimeOut,
charset=Default_MySQL_Charset,
db=Default_Database_Name
)
return conn
def mysql_exec(sql_script, sql_param=None):
"""
执行传入的脚本,返回影响行数
:param sql_script:
:param sql_param:
:return: 脚本最后一条语句执行影响行数
"""
try:
conn = get_mysql_connection()
print_info("在服务器{0}上执行脚本:{1}".format(
conn.get_host_info(), sql_script))
cursor = conn.cursor()
if sql_param is not None:
cursor.execute(sql_script, sql_param)
row_count = cursor.rowcount
else:
cursor.execute(sql_script)
row_count = cursor.rowcount
conn.commit()
cursor.close()
conn.close()
except Exception, e:
print_info("execute exception:" + str(e))
row_count = 0
return row_count
def mysql_query(sql_script, sql_param=None):
"""
执行传入的SQL脚本,并返回查询结果
:param sql_script:
:param sql_param:
:return: 返回SQL查询结果
"""
try:
conn = get_mysql_connection()
print_info("在服务器{0}上执行脚本:{1}".format(
conn.get_host_info(), sql_script))
cursor = conn.cursor()
if sql_param != '':
cursor.execute(sql_script, sql_param)
else:
cursor.execute(sql_script)
exec_result = cursor.fetchall()
cursor.close()
conn.close()
return exec_result
except Exception, e:
print_info("execute exception:" + str(e))
def get_id_range(table_name):
"""
按照传入的表获取要删除数据最大ID、最小ID、删除总行数
:param table_name: 要删除的表
:return: 返回要删除数据最大ID、最小ID、删除总行数
"""
global DELETE_DATETIME
sql_script = """
SELECT
MAX(ID) AS MAX_ID,
MIN(ID) AS MIN_ID,
COUNT(1) AS Total_Count
FROM {0}
WHERE create_time <='{1}';
""".format(table_name, DELETE_DATETIME)
query_result = mysql_query(sql_script=sql_script, sql_param=None)
max_id, min_id, total_count = query_result[0]
# 此处有一坑,可能出现total_count不为0 但是max_id 和min_id 为None的情况
# 因此判断max_id和min_id 是否为NULL
if (max_id is None) or (min_id is None):
max_id, min_id, total_count = 0, 0, 0
return max_id, min_id, total_count
def delete_data(table_name):
max_id, min_id, total_count = get_id_range(table_name)
temp_id = min_id
while temp_id <= max_id:
sql_script = """
DELETE FROM {0}
WHERE id <= {1}
and id >= {2}
AND create_time <='{3}';
""".format(table_name, temp_id + DELETE_ROWS, temp_id, DELETE_DATETIME)
temp_id += DELETE_ROWS
print(sql_script)
row_count = mysql_exec(sql_script)
print_info("影响行数:{0}".format(row_count))
current_percent = (temp_id - min_id) * 1.0 / (max_id - min_id)
print_info("当前进度{0}/{1},剩余{2},进度为{3}%".format(temp_id, max_id, max_id - temp_id, "%.2f" % current_percent))
time.sleep(SLEEP_SECOND_PER_BATCH)
print_info("当前表{0}已无需要删除的数据".format(table_name))
delete_data('TB001')
delete_data('TB002')
delete_data('TB003')
执行效果:
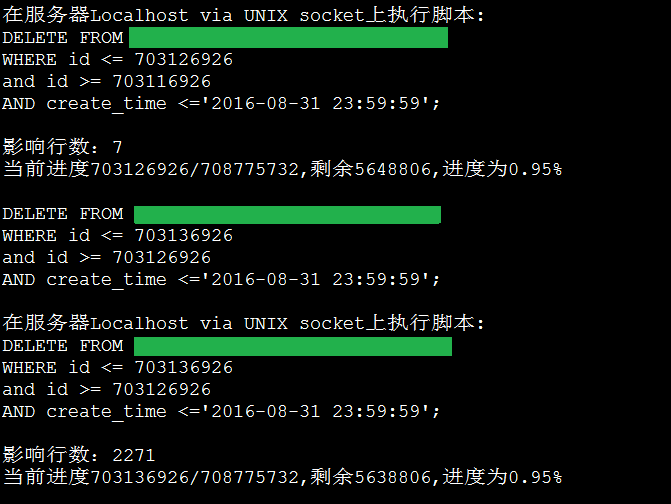
实现原理:
由于表存在自增ID,于是给我们增量循环删除的机会,查找出满足删除条件的最大值ID和最小值ID,然后按ID 依次递增,每次小范围内(如10000条)进行删除。
实现优点:
实现“小斧子砍大柴”的效果,事务小,对线上影响较小,打印出当前处理到的“ID”,可以随时关闭,稍微修改下代码便可以从该ID开始,方便。
实现不足:
为防止主从延迟太高,采用每次删除SLEEP1秒的方式,相对比较糙,最好的方式应该是周期扫描这条复制链路,根据延迟调整SLEEP的周期,反正都脚本化,再智能化点又何妨!

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师 今天我将为大家带来一个关于用户私域用户质量数据分析 ...
2025-04-18一、CDA持证人介绍 在数字化浪潮席卷商业领域的当下,数据分析已成为企业发展的关键驱动力。为助力大家深入了解数据分析在电商行 ...
2025-04-17CDA持证人简介:居瑜 ,CDA一级持证人,国企财务经理,13年财务管理运营经验,在数据分析实践方面积累了丰富的行业经验。 一、 ...
2025-04-16持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27






