利用Python代码实现数据可视化的5种方法详解
数据科学家并不逊色于艺术家。他们用数据可视化的方式绘画,试图展现数据内隐藏的模式或表达对数据的见解。更有趣的是,一旦接触到任何可视化的内容、数据时,人类会有更强烈的知觉、认知和交流。
数据可视化是数据科学家工作中的重要组成部分。在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data
Analysis,EDA)以获取对数据的一些理解。创建可视化方法确实有助于使事情变得更加清晰易懂,特别是对于大型、高维数据集。在项目结束时,以清晰、简洁和引人注目的方式展现最终结果是非常重要的,因为你的受众往往是非技术型客户,只有这样他们才可以理解。
Matplotlib 是一个流行的 Python
库,可以用来很简单地创建数据可视化方案。但每次创建新项目时,设置数据、参数、图形和排版都会变得非常繁琐和麻烦。在这篇博文中,我们将着眼于 5
个数据可视化方法,并使用 Python Matplotlib
为他们编写一些快速简单的函数。与此同时,这里有一个很棒的图表,可用于在工作中选择正确的可视化方法!

散点图
散点图非常适合展示两个变量之间的关系,因为你可以直接看到数据的原始分布。
如下面第一张图所示的,你还可以通过对组进行简单地颜色编码来查看不同组数据的关系。想要可视化三个变量之间的关系? 没问题!
仅需使用另一个参数(如点大小)就可以对第三个变量进行编码,如下面的第二张图所示。
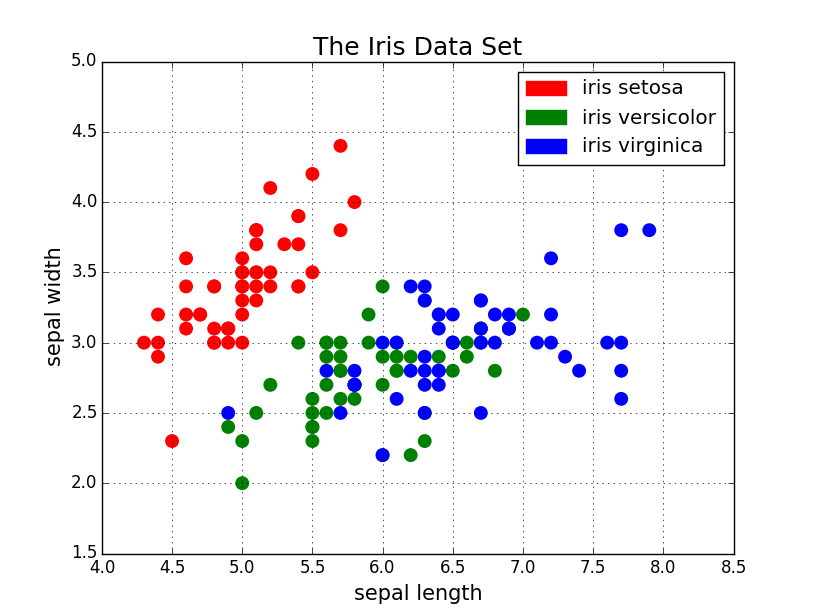

现在开始讨论代码。我们首先用别名 “plt” 导入 Matplotlib 的 pyplot 。要创建一个新的点阵图,我们可调用
plt.subplots() 。我们将 x 轴和 y 轴数据传递给该函数,然后将这些数据传递给 ax.scatter()
以绘制散点图。我们还可以设置点的大小、点颜色和 alpha 透明度。你甚至可以设置 Y
轴为对数刻度。标题和坐标轴上的标签可以专门为该图设置。这是一个易于使用的函数,可用于从头到尾创建散点图!
import matplotlib.pyplot as pltimport numpy as npdef scatterplot(x_data, y_data, x_label="", y_label="", title="", color = "r", yscale_log=False):
# Create the plot object
_, ax = plt.subplots() # Plot the data, set the size (s), color and transparency (alpha)
# of the points
ax.scatter(x_data, y_data, s = 10, color = color, alpha = 0.75) if yscale_log == True:
ax.set_yscale('log') # Label the axes and provide a title
ax.set_title(title)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
折线图
当你可以看到一个变量随着另一个变量明显变化的时候,比如说它们有一个大的协方差,那最好使用折线图。让我们看一下下面这张图。我们可以清晰地看到对于所有的主线随着时间都有大量的变化。使用散点绘制这些将会极其混乱,难以真正明白和看到发生了什么。折线图对于这种情况则非常好,因为它们基本上提供给我们两个变量(百分比和时间)的协方差的快速总结。另外,我们也可以通过彩色编码进行分组。

这里是折线图的代码。它和上面的散点图很相似,只是在一些变量上有小的变化。
def lineplot(x_data, y_data, x_label="", y_label="", title=""):
# Create the plot object
_, ax = plt.subplots() # Plot the best fit line, set the linewidth (lw), color and
# transparency (alpha) of the line
ax.plot(x_data, y_data, lw = 2, color = '#539caf', alpha = 1) # Label the axes and provide a title
ax.set_title(title)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
直方图
直方图对于查看(或真正地探索)数据点的分布是很有用的。查看下面我们以频率和 IQ
做的直方图。我们可以清楚地看到朝中间聚集,并且能看到中位数是多少。我们也可以看到它呈正态分布。使用直方图真得能清晰地呈现出各个组的频率之间的相对差别。组的使用(离散化)真正地帮助我们看到了“更加宏观的图形”,然而当我们使用所有没有离散组的数据点时,将对可视化可能造成许多干扰,使得看清真正发生了什么变得困难。
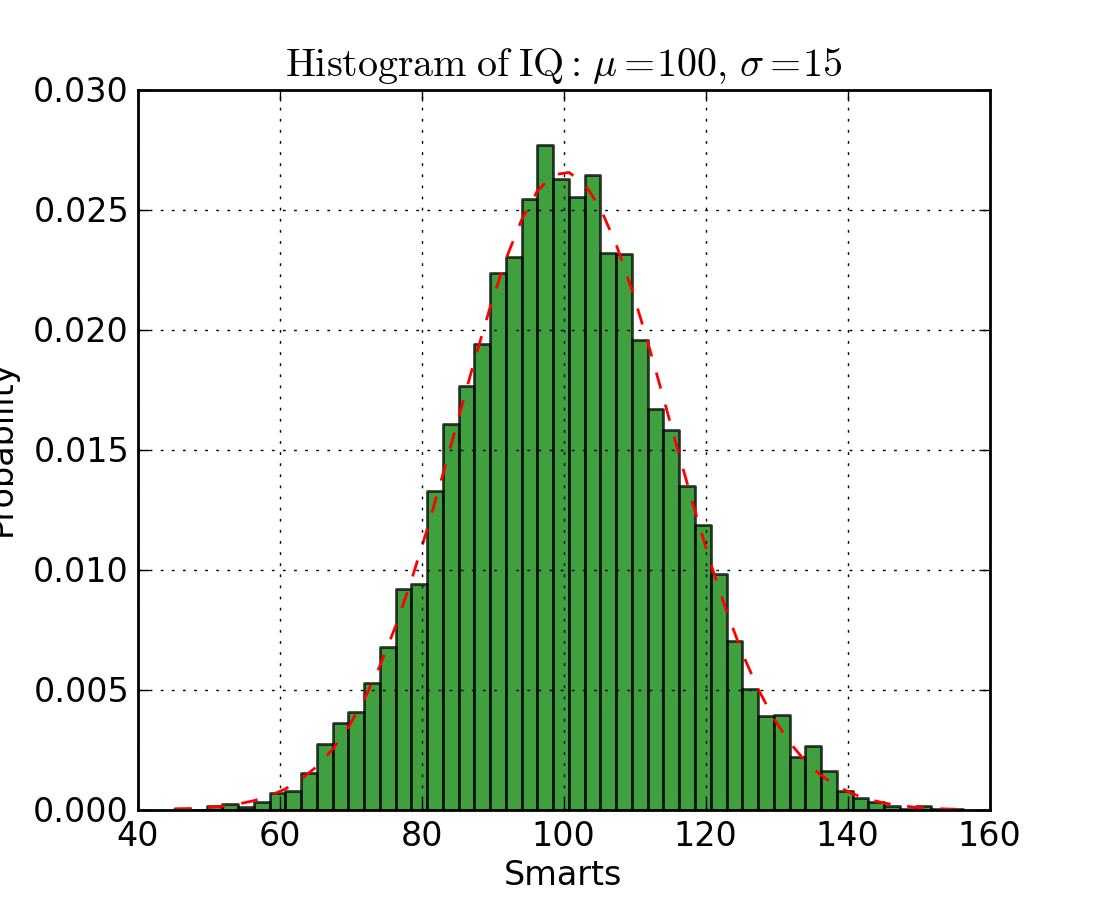
下面是在 Matplotlib 中的直方图代码。有两个参数需要注意一下:首先,参数 n_bins
控制我们想要在直方图中有多少个离散的组。更多的组将给我们提供更加完善的信息,但是也许也会引进干扰,使得我们远离全局;另一方面,较少的组给我们一种更多的是“鸟瞰图”和没有更多细节的全局图。其次,参数
cumulative 是一个布尔值,允许我们选择直方图是否为累加的,基本上就是选择是 PDF(Probability Density
Function,概率密度函数)还是 CDF(Cumulative Density Function,累积密度函数)。
defhistogram(data, n_bins, cumulative=False, x_label="", y_label = "", title = ""):
_, ax=plt.subplots()
ax.hist(data, n_bins=n_bins, cumulative=cumulative, color='#539caf')
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
想象一下我们想要比较数据中两个变量的分布。有人可能会想你必须制作两张直方图,并且把它们并排放在一起进行比较。然而,实际上有一种更好的办法:我们可以使用不同的透明度对直方图进行叠加覆盖。看下图,均匀分布的透明度设置为
0.5 ,使得我们可以看到他背后的图形。这样我们就可以直接在同一张图表里看到两个分布。
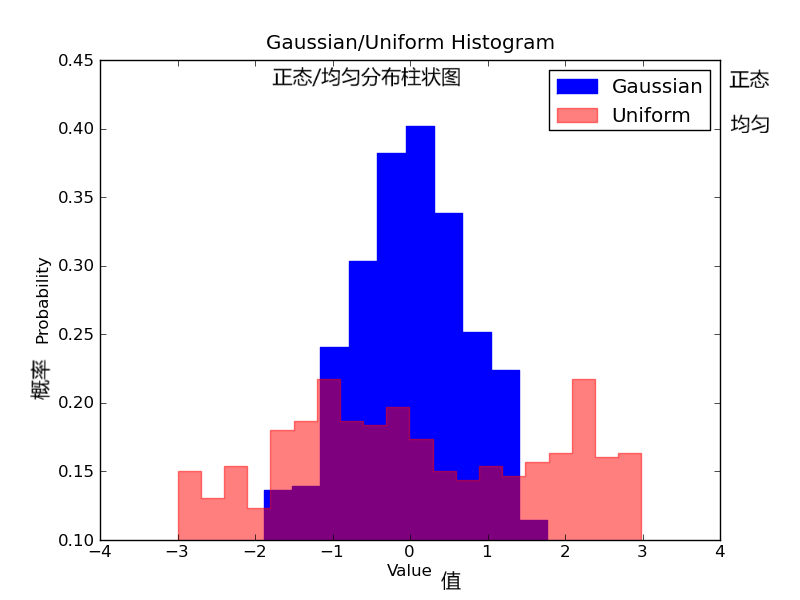
对于重叠的直方图,需要设置一些东西。首先,我们设置可同时容纳不同分布的横轴范围。根据这个范围和期望的组数,我们可以真正地计算出每个组的宽度。最后,我们在同一张图上绘制两个直方图,其中有一个稍微更透明一些。
# Overlay 2 histograms to compare themdef overlaid_histogram(data1, data2, n_bins = 0, data1_name="", data1_color="#539caf", data2_name="", data2_color="#7663b0", x_label="", y_label="", title=""):
# Set the bounds for the bins so that the two distributions are fairly compared
max_nbins = 10
data_range = [min(min(data1), min(data2)), max(max(data1), max(data2))]
binwidth = (data_range[1] - data_range[0]) / max_nbins if n_bins == 0
bins = np.arange(data_range[0], data_range[1] + binwidth, binwidth) else:
bins = n_bins # Create the plot
_, ax = plt.subplots()
ax.hist(data1, bins = bins, color = data1_color, alpha = 1, label = data1_name)
ax.hist(data2, bins = bins, color = data2_color, alpha = 0.75, label = data2_name)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = 'best')
柱状图
当你试图将类别很少(可能小于10)的分类数据可视化的时候,柱状图是最有效的。如果我们有太多的分类,那么这些柱状图就会非常杂乱,很难理解。柱状图对分类数据很好,因为你可以很容易地看到基于柱的类别之间的区别(比如大小);分类也很容易划分和用颜色进行编码。我们将会看到三种不同类型的柱状图:常规的,分组的,堆叠的。在我们进行的过程中,请查看图形下面的代码。
常规的柱状图如下面的图1。在 barplot() 函数中,xdata 表示 x 轴上的标记,ydata 表示 y 轴上的杆高度。误差条是一条以每条柱为中心的额外的线,可以画出标准偏差。
分组的柱状图让我们可以比较多个分类变量。看看下面的图2。我们比较的第一个变量是不同组的分数是如何变化的(组是G1,G2,……等等)。我们也在比较性别本身和颜色代码。看一下代码,y_data_list
变量实际上是一个 y 元素为列表的列表,其中每个子列表代表一个不同的组。然后我们对每个组进行循环,对于每一个组,我们在 x
轴上画出每一个标记;每个组都用彩色进行编码。
堆叠柱状图可以很好地观察不同变量的分类。在图3的堆叠柱状图中,我们比较了每天的服务器负载。通过颜色编码后的堆栈图,我们可以很容易地看到和理解哪些服务器每天工作最多,以及与其他服务器进行比较负载情况如何。此代码的代码与分组的条形图相同。我们循环遍历每一组,但这次我们把新柱放在旧柱上,而不是放在它们的旁边。

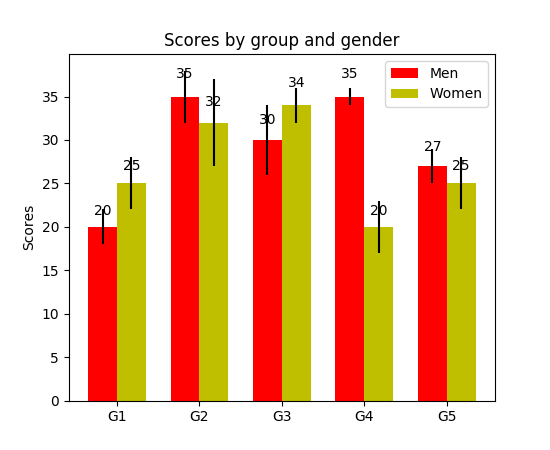
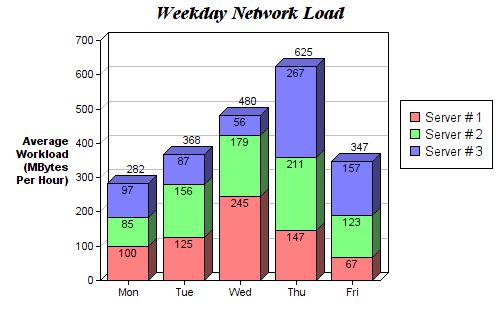
def barplot(x_data, y_data, error_data, x_label="", y_label="", title=""):
_, ax = plt.subplots()
# Draw bars, position them in the center of the tick mark on the x-axis
ax.bar(x_data, y_data, color = '#539caf', align = 'center')
# Draw error bars to show standard deviation, set ls to 'none'
# to remove line between points
ax.errorbar(x_data, y_data, yerr = error_data, color = '#297083', ls = 'none', lw = 2, capthick = 2)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
def stackedbarplot(x_data, y_data_list, colors, y_data_names="", x_label="", y_label="", title=""):
_, ax = plt.subplots()
# Draw bars, one category at a time
for i in range(0, len(y_data_list)):
if i == 0:
ax.bar(x_data, y_data_list[i], color = colors[i], align = 'center', label = y_data_names[i])
else:
# For each category after the first, the bottom of the
# bar will be the top of the last category
ax.bar(x_data, y_data_list[i], color = colors[i], bottom = y_data_list[i - 1], align = 'center', label = y_data_names[i])
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = 'upper right')
def groupedbarplot(x_data, y_data_list, colors, y_data_names="", x_label="", y_label="", title=""):
_, ax = plt.subplots()
# Total width for all bars at one x location
total_width = 0.8
# Width of each individual bar
ind_width = total_width / len(y_data_list)
# This centers each cluster of bars about the x tick mark
alteration = np.arange(-(total_width/2), total_width/2, ind_width)
# Draw bars, one category at a time
for i in range(0, len(y_data_list)):
# Move the bar to the right on the x-axis so it doesn't
# overlap with previously drawn ones
ax.bar(x_data + alteration[i], y_data_list[i], color = colors[i], label = y_data_names[i], width = ind_width)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = 'upper right')
箱形图
我们之前看了直方图,它很好地可视化了变量的分布。但是如果我们需要更多的信息呢?也许我们想要更清晰的看到标准偏差?也许中值与均值有很大不同,我们有很多离群值?如果有这样的偏移和许多值都集中在一边呢?
这就是箱形图所适合干的事情了。箱形图给我们提供了上面所有的信息。实线框的底部和顶部总是第一个和第三个四分位(比如 25% 和 75% 的数据),箱体中的横线总是第二个四分位(中位数)。像胡须一样的线(虚线和结尾的条线)从这个箱体伸出,显示数据的范围。
由于每个组/变量的框图都是分别绘制的,所以很容易设置。xdata 是一个组/变量的列表。Matplotlib 库的 boxplot()
函数为 ydata 中的每一列或每一个向量绘制一个箱体。因此,xdata 中的每个值对应于 ydata
中的一个列/向量。我们所要设置的就是箱体的美观。
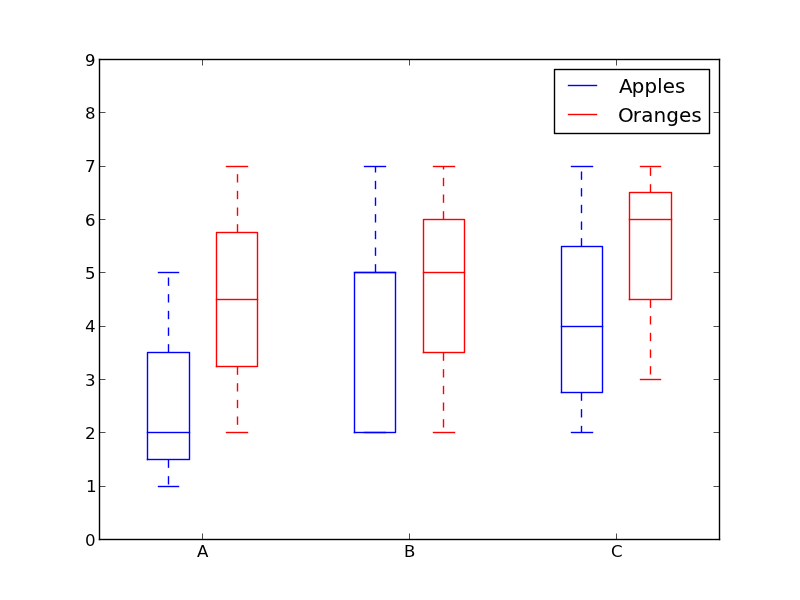
def boxplot(x_data, y_data, base_color="#539caf", median_color="#297083", x_label="", y_label="", title=""):
_, ax = plt.subplots()
# Draw boxplots, specifying desired style
ax.boxplot(y_data
# patch_artist must be True to control box fill
, patch_artist = True
# Properties of median line
, medianprops = {'color': median_color}
# Properties of box
, boxprops = {'color': base_color, 'facecolor': base_color}
# Properties of whiskers
, whiskerprops = {'color': base_color}
# Properties of whisker caps
, capprops = {'color': base_color})
# By default, the tick label starts at 1 and increments by 1 for
# each box drawn. This sets the labels to the ones we want
ax.set_xticklabels(x_data)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
结语使用 Matplotlib 有 5 个快速简单的数据可视化方法。将相关事务抽象成函数总是会使你的代码更易于阅读和使用!我希望你喜欢这篇文章,并且学到了一些新的有用的技巧
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330