R语言的三种聚类方法
对于R语言,相信做数据分析的来说,一定不陌生,那么对于R语言的三种聚类方法你是否应用的全面,下面就说一下?
一、层次聚类
r语言中使用dist(x, method = “euclidean”,diag = FALSE, upper = FALSE, p = 2) 来计算距离。其中x是样本矩阵或者数据框。method表示计算哪种距离。method的取值有:
euclidean 欧几里德距离,就是平方再开方。
maximum 切比雪夫距离
manhattan 绝对值距离
canberra Lance 距离
minkowski 明科夫斯基距离,使用时要指定p值
binary 定性变量距离.
定性变量距离: 记m个项目里面的 0:0配对数为m0 ,1:1配对数为m1,不能配对数为m2,距离=m1/(m1+m2);
diag 为TRUE的时候给出对角线上的距离。upper为TURE的时候给出上三角矩阵上的值。
r语言中使用scale(x, center = TRUE, scale = TRUE) 对数据矩阵做中心化和标准化变换。
如只中心化 scale(x,scale=F) ,
r语言中使用sweep(x, MARGIN, STATS, FUN=”-“, …) 对矩阵进行运算。MARGIN为1,表示行的方向上进行运算,为2表示列的方向上运算。STATS是运算的参数。FUN为运算函数,默认是减法。下面利用sweep对矩阵x进行极差标准化变换

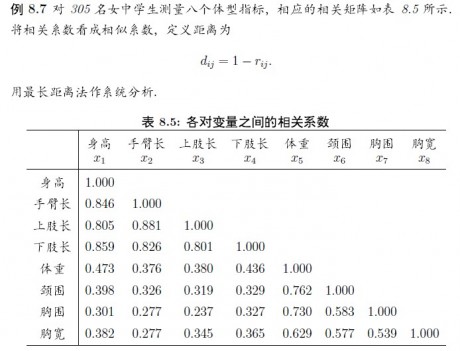
有时候我们不是对样本进行分类,而是对变量进行分类。这时候,我们不计算距离,而是计算变量间的相似系数。常用的有夹角和相关系数。
r语言计算两向量的夹角余弦:

相关系数用cor函数
2)层次聚类法
层次聚类法。先计算样本之间的距离。每次将距离最近的点合并到同一个类。然后,再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并,直到合成了一个类。其中类与类的距离的计算方法有:最短距离法,最长距离法,中间距离法,类平均法等。比如最短距离法,将类与类的距离定义为类与类之间样本的最段距离。。。
r语言中使用hclust(d, method = “complete”, members=NULL) 来进行层次聚类。
其中d为距离矩阵。
method表示类的合并方法,有:
single 最短距离法
complete 最长距离法
median 中间距离法
mcquitty 相似法
average 类平均法
centroid 重心法
ward 离差平方和法


然后可以用rect.hclust(tree, k = NULL, which = NULL, x = NULL, h = NULL,border = 2, cluster = NULL)来确定类的个数。 tree就是求出来的对象。k为分类的个数,h为类间距离的阈值。border是画出来的颜色,用来分类的。

result=cutree(model,k=3) 该函数可以用来提取每个样本的所属类别
层次聚类,在类形成之后就不再改变。而且数据比较大的时候更占内存。
动态聚类,先抽几个点,把周围的点聚集起来。然后算每个类的重心或平均值什么的,以算出来的结果为分类点,不断的重复。直到分类的结果收敛为止。r语言中主要使用kmeans(x, centers, iter.max = 10, nstart = 1,algorithm =c(“Hartigan-Wong”, “Lloyd”,”Forgy”, “MacQueen”))来进行聚类。centers是初始类的个数或者初始类的中心。iter.max是最大迭代次数。nstart是当centers是数字的时候,随机集合的个数。algorithm是算法,默认是第一个。
使用knn包进行Kmean聚类分析
将数据集进行备份,将列newiris$Species置为空,将此数据集作为测试数据集
> newiris <- iris
> newiris$Species <- NULL
Cluster means: 每个聚类中各个列值生成的最终平均值
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.006000 3.428000 1.462000 0.246000
2 5.901613 2.748387 4.393548 1.433871
3 6.850000 3.073684 5.742105 2.071053
Clustering vector: 每行记录所属的聚类(2代表属于第二个聚类,1代表属于第一个聚类,3代表属于第三个聚类)
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[37] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[73] 2 2 2 2 2 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 2 3 3 3 3 2 3
[109] 3 3 3 3 3 2 2 3 3 3 3 2 3 2 3 2 3 3 2 2 3 3 3 3 3 2 3 3 3 3 2 3 3 3 2 3
[145] 3 3 2 3 3 2
Within cluster sum of squares by cluster: 每个聚类内部的距离平方和
[1] 15.15100 39.82097 23.87947
(between_SS / total_SS = 88.4 %) 组间的距离平方和占了整体距离平方和的的88.4%,也就是说各个聚类间的距离做到了最大
Available components: 运行kmeans函数返回的对象所包含的各个组成部分
[1] “cluster” “centers” “totss” “withinss”
[5] “tot.withinss” “betweenss” “size”
(“cluster”是一个整数向量,用于表示记录所属的聚类
“centers”是一个矩阵,表示每聚类中各个变量的中心点
“totss”表示所生成聚类的总体距离平方和
“withinss”表示各个聚类组内的距离平方和
“tot.withinss”表示聚类组内的距离平方和总量
“betweenss”表示聚类组间的聚类平方和总量
“size”表示每个聚类组中成员的数量)
创建一个连续表,在三个聚类中分别统计各种花出现的次数
> table(iris$Species, kc$cluster)
1 2 3
setosa 0 50 0
versicolor 2 0 48
virginica 36 0 14
根据最后的聚类结果画出散点图,数据为结果集中的列”Sepal.Length”和”Sepal.Width”,颜色为用1,2,3表示的缺省颜色
> plot(newiris[c(“Sepal.Length”, “Sepal.Width”)], col = kc$cluster)
在图上标出每个聚类的中心点
〉points(kc$centers[,c(“Sepal.Length”, “Sepal.Width”)], col = 1:3, pch = 8, cex=2)
动态聚类往往聚出来的类有点圆形或者椭圆形。基于密度扫描的算法能够解决这个问题。思路就是定一个距离半径,定最少有多少个点,然后把可以到达的点都连起来,判定为同类。在r中的实现
dbscan(data, eps, MinPts, scale, method, seeds, showplot, countmode)
其中eps是距离的半径,minpts是最少多少个点。 scale是否标准化(我猜) ,method 有三个值raw,dist,hybird,分别表示,数据是原始数据避免计算距离矩阵,数据就是距离矩阵,数据是原始数据但计算部分距离矩阵。showplot画不画图,0不画,1和2都画。countmode,可以填个向量,用来显示计算进度。用鸢尾花试一试


数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27TensorFlow Datasets(TFDS)是一个用于下载、管理和预处理机器学习数据集的库。它提供了易于使用的API,允许用户从现有集合中 ...
2025-03-26"不谋全局者,不足谋一域。"在数据驱动的商业时代,战略级数据分析能力已成为职场核心竞争力。《CDA二级教材:商业策略数据分析 ...
2025-03-26当你在某宝刷到【猜你喜欢】时,当抖音精准推来你的梦中情猫时,当美团外卖弹窗刚好是你想吃的火锅店…… 恭喜你,你正在被用户 ...
2025-03-26当面试官问起随机森林时,他到底在考察什么? ""请解释随机森林的原理""——这是数据分析岗位面试中的经典问题。但你可能不知道 ...
2025-03-25在数字化浪潮席卷的当下,数据俨然成为企业的命脉,贯穿于业务运作的各个环节。从线上到线下,从平台的交易数据,到门店的运营 ...
2025-03-25在互联网和移动应用领域,DAU(日活跃用户数)是一个耳熟能详的指标。无论是产品经理、运营,还是数据分析师,DAU都是衡量产品 ...
2025-03-24ABtest做的好,产品优化效果差不了!可见ABtest在评估优化策略的效果方面地位还是很高的,那么如何在业务中应用ABtest? 结合企业 ...
2025-03-21在企业数据分析中,指标体系是至关重要的工具。不仅帮助企业统一数据标准、提升数据质量,还能为业务决策提供有力支持。本文将围 ...
2025-03-20解锁数据分析师高薪密码,CDA 脱产就业班助你逆袭! 在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的 ...
2025-03-19在 MySQL 数据库中,查询一张表但是不包含某个字段可以通过以下两种方法实现:使用 SELECT 子句以明确指定想要的字段,或者使 ...
2025-03-17在当今数字化时代,数据成为企业发展的关键驱动力,而用户画像作为数据分析的重要成果,改变了企业理解用户、开展业务的方式。无 ...
2025-03-172025年是智能体(AI Agent)的元年,大模型和智能体的发展比较迅猛。感觉年初的deepseek刚火没多久,这几天Manus又成为媒体头条 ...
2025-03-14以下的文章内容来源于柯家媛老师的专栏,如果您想阅读专栏《小白必备的数据思维课》,点击下方链接 https://edu.cda.cn/goods/sh ...
2025-03-13






