R语言(入门小练习篇)
问题:
一组学生参加了数学、科学和英语考试。为了给所有的学生确定一个单一的成绩衡量指标,需要将这些科目的成绩组合起来。另外,还想将前20%的学生评定为A,接下来20%的学生评定为B,以此类推。最后,希望按字母顺序对学生排序。
Excel中的数据表(自己一个个敲的,最讨厌做的事情TT)
|
StuId
|
StuName
|
Math
|
Science
|
English
|
|
1
|
John Davis
|
502
|
95
|
25
|
|
2
|
Angela Williams
|
465
|
67
|
12
|
|
3
|
Bull Jones
|
621
|
78
|
22
|
|
4
|
Cheryl Cushing
|
575
|
66
|
18
|
|
5
|
Reuven Ytzrhak
|
454
|
96
|
15
|
|
6
|
Joel Knox
|
634
|
89
|
30
|
|
7
|
Mary Rayburn
|
576
|
78
|
37
|
|
8
|
Greg England
|
421
|
56
|
12
|
|
9
|
Brad Tmac
|
599
|
68
|
22
|
|
10
|
Tracy Mcgrady
|
666
|
100
|
38
|
step1:输入数据——R语言导入xlsx
1 #1数据输入
2 install.packages("xlsx")
3 library(xlsx)
4 workbook<-"D:/R语言/code/R语言实战前五章小试身手/StuScore.xlsx"#也可用‘\\’注意转义字符
5 StuScore<-read.xlsx(workbook,1)#1表示sheet1
6 StuScore
step2:数据预处理——将变量进行标准化
因为数学,科学和英语考试的分值不同(均值和标准差均有较大差异),在组合之前要让他们变得可以比较
方法:变量标准化,把每科成绩都用单位标准差表示
tips:
所谓数据的标准化是指中心化之后的数据在除以数据集的标准差,即数据集中的各项数据减去数据集的均值再除以数据集的标准差。
例如有数据集1, 2, 3, 6, 3,其均值为3,其标准差为1.87,那么标准化之后的数据集为(1-3)/1.87,(2-3)/1.87,(3-3)/1.87,(6-3)/1.87,(3-3)/1.87,即:-1.069,-0.535,0,1.604,0
数据中心化和标准化的意义是一样的,为了消除量纲对数据结构的影响。
这里使用scale()可以直接实现
1 > #2数据预处理
2 > options(digits=2)#限定为2位小数
3 > afterscale<-scale(StuScore[,3:5])
4 > afterscale
5 Math Science English
6 [1,] -0.58 1.040 0.20
7 [2,] -1.02 -0.815 -1.17
8 [3,] 0.82 -0.086 -0.12
9 [4,] 0.28 -0.881 -0.54
10 [5,] -1.15 1.106 -0.86
11 [6,] 0.98 0.643 0.73
12 [7,] 0.29 -0.086 1.47
13 [8,] -1.54 -1.544 -1.17
14 [9,] 0.56 -0.749 -0.12
15 [10,] 1.35 1.372 1.57
16 attr(,"scaled:center")
17 Math Science English
18 551 79 23
19 attr(,"scaled:scale")
20 Math Science English
21 84.7 15.1 9.5
这里,有两个疑问:
1.说好的输出两位小数呢?Science那一栏输出的都是三位小数,怎么回事?
2.这是什么东东?
-
1 attr(,"scaled:center")
2 Math Science English
3 551 79 23
4 attr(,"scaled:scale")
5 Math Science English
6 84.7 15.1 9.5
scale方法中的两个参数center和scale的解释:
1.center和scale默认为真,即T或者TRUE
2.center为真表示数据中心化
3.scale为真表示数据标准化
也就是说:center表示一列数据的均值,scale则表示标准差(有兴趣的同学,可以用Excel的STDEV函数验证一下)
step3:通过函数mean()来计算各行的均值以及获得综合得分,并使用cbind()将其添加到花名册中
1 > #3在afterscale中计算标准差均值,并将其添加到StuScore
2 > score<-apply(afterscale,1,mean)#1表示行,mean表示均值函数
3 > StuScore<-cbind(StuScore,score)
4 > StuScore
5 StuId StuName Math Science English score
6 1 1 John Davis 502 95 25 0.22
7 2 2 Angela Williams 465 67 12 -1.00
8 3 3 Bull Jones 621 78 22 0.21
9 4 4 Cheryl Cushing 575 66 18 -0.38
10 5 5 Reuven Ytzrhak 454 96 15 -0.30
11 6 6 Joel Knox 634 89 30 0.78
12 7 7 Mary Rayburn 576 78 37 0.56
13 8 8 Greg England 421 56 12 -1.42
14 9 9 Brad Tmac 599 68 22 -0.10
15 10 10 Tracy Mcgrady 666 100 38 1.43
Step4:函数quantile()给出学生综合得分的百分位数
quantile(x,probs):求分位数,其中x为待求分位数的数值型向量,probs为一个由[0,1]之间的概率值组成的数值向量
1 > afterquantile<-quantile(score,c(.8,.6,.4,.2))
2 > afterquantile
3 80% 60% 40% 20%
4 0.60 0.21 -0.18 -0.50
step5:使用逻辑运算符,把score转为等级(离散型)
1 > #5使用逻辑运算符,把score转为等级(离散型)
2 > StuScore$grade[score>=afterquantile[1]]<-"A"
3 > StuScore$grade[score<afterquantile[1]&&score>=afterquantile[2]]<-"B"
4 > StuScore$grade[score<afterquantile[2]&&score>=afterquantile[3]]<-"C"
5 > StuScore$grade[score<afterquantile[3]&&score>=afterquantile[4]]<-"D"
6 > StuScore$grade[score<afterquantile[4]]<-"E"
7 > StuScore
8 StuId StuName Math Science English score grade
9 1 1 John Davis 502 95 25 0.22 B
10 2 2 Angela Williams 465 67 12 -1.00 E
11 3 3 Bull Jones 621 78 22 0.21 B
12 4 4 Cheryl Cushing 575 66 18 -0.38 E
13 5 5 Reuven Ytzrhak 454 96 15 -0.30 E
14 6 6 Joel Knox 634 89 30 0.78 B
15 7 7 Mary Rayburn 576 78 37 0.56 B
16 8 8 Greg England 421 56 12 -1.42 E
17 9 9 Brad Tmac 599 68 22 -0.10 E
18 10 10 Tracy Mcgrady 666 100 38 1.43 B
Step6:使用strsplit()以空格为界把学生姓名拆分为姓氏和名字
1 > #Step6:使用strsplit()以空格为界把学生姓名拆分为姓氏和名字
2 > name<-strsplit((StuScore$StuName)," ")
3Error in strsplit((StuScore$StuName), " ") : non-character argument4 > name
5 [1] "Jim" "Tony" "Lisa" "Tom"
这里出错了,原因很明确,没有字符型的参数传入,反应过来,原来是用execl导入的时候,StuName那一列默认的是什么类型的呢?我们来检测一下
1 > is.numeric(StuScore$StuName)
2 [1] FALSE
3 > is.logical(StuScore$StuName)
4 [1] FALSE
5 > is.character(StuScore$StuName)
6 [1] FALSE
7 > is.complex(StuScore$StuName)
8 [1] FALSE
9 > help(type)
10 > typeof(StuScore$StuName)
11 [1] "integer"
因此,我们把他改为字符型
1 > #Step6:使用strsplit()以空格为界把学生姓名拆分为姓氏和名字
2 > StuScore$StuName<-as.character(StuScore$StuName)
3 > is.character(StuScore$StuName)
4 [1] TRUE
5 > name<-strsplit(StuScore$StuName," ")
6 > name
7 [[1]]
8 [1] "John" "Davis"
9
10 [[2]]
11 [1] "Angela" "Williams"
12
13 [[3]]
14 [1] "Bull" "Jones"
15
16 [[4]]
17 [1] "Cheryl" "Cushing"
18
19 [[5]]
20 [1] "Reuven" "Ytzrhak"
21
22 [[6]]
23 [1] "Joel" "Knox"
24
25 [[7]]
26 [1] "Mary" "Rayburn"
27
28 [[8]]
29 [1] "Greg" "England"
30
31 [[9]]
32 [1] "Brad" "Tmac"
33
34 [[10]]
35 [1] "Tracy" "Mcgrady"
Step7:把name分成Firstname和LastName,加入到StuScore中
1 > #7把name分成Firstname和LastName,加入到StuScore中
2 > FirstName<-sapply(name,"[",1)
3 > LastName<-sapply(name,"[",2)
4 > StuScore<-cbind(FirstName,LastName,StuScore[,-1])
5 > StuScore
6 FirstName LastName LastName StuName Math Science English score grade
7 1 John Davis Davis John Davis 502 95 25 0.22 B
8 2 Angela Williams Williams Angela Williams 465 67 12 -1.00 E
9 3 Bull Jones Jones Bull Jones 621 78 22 0.21 B
10 4 Cheryl Cushing Cushing Cheryl Cushing 575 66 18 -0.38 E
11 5 Reuven Ytzrhak Ytzrhak Reuven Ytzrhak 454 96 15 -0.30 E
12 6 Joel Knox Knox Joel Knox 634 89 30 0.78 B
13 7 Mary Rayburn Rayburn Mary Rayburn 576 78 37 0.56 B
14 8 Greg England England Greg England 421 56 12 -1.42 E
15 9 Brad Tmac Tmac Brad Tmac 599 68 22 -0.10 E
16 10 Tracy Mcgrady Mcgrady Tracy Mcgrady 666 100 38 1.43 B
17 >
Step8:order排序
1 > #8order()排序
2 > StuScore[order(LastName,FirstName),]
3 FirstName LastName LastName StuName Math Science English score grade
4 4 Cheryl Cushing Cushing Cheryl Cushing 575 66 18 -0.38 E
5 1 John Davis Davis John Davis 502 95 25 0.22 B
6 8 Greg England England Greg England 421 56 12 -1.42 E
7 3 Bull Jones Jones Bull Jones 621 78 22 0.21 B
8 6 Joel Knox Knox Joel Knox 634 89 30 0.78 B
9 10 Tracy Mcgrady Mcgrady Tracy Mcgrady 666 100 38 1.43 B
10 7 Mary Rayburn Rayburn Mary Rayburn 576 78 37 0.56 B
11 9 Brad Tmac Tmac Brad Tmac 599 68 22 -0.10 E
12 2 Angela Williams Williams Angela Williams 465 67 12 -1.00 E
13 5 Reuven Ytzrhak Ytzrhak Reuven Ytzrhak 454 96 15 -0.30 E
14 >
虽然是照着书本上做的,但是,代码必须要自己敲一遍,过程中遇到的一些小问题也解决了,就算菜鸟简单入门。这样样例还可以继续拓展,把R语言实战前5章的内容尽可能用一边,可以绘制一些图,等等,本文还会继续更新。
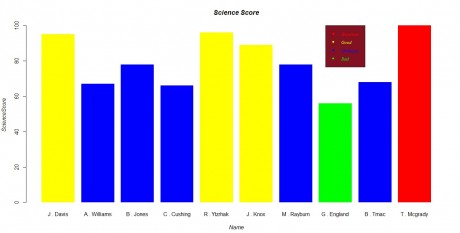
为ScienceScore绘制条形图
根据不同的分数等级,显示不同的颜色。
1 #为StuScore绘制分组条形图
2 install.packages("vcd")
3 library(vcd)
4 fill_colors<-c() #不同的等级,不同的颜色显示
5 for(i in 1:length(StuScore$Science)){
6 if(StuScore$Science[i]==100){
7 fill_colors<-c(fill_colors,"red")
8 }else if(StuScore$Science[i]<100&&StuScore$Science[i]>=80){
9 fill_colors<-c(fill_colors,"yellow")
10 }else if(StuScore$Science[i]<80&&StuScore$Science[i]>=60){
11 fill_colors<-c(fill_colors,"blue")
12 }else{
13 fill_colors<-c(fill_colors,"green")
14 }
15 }
16 barplot(StuScore$Science, #条形图
17 main="Science Score",
18 xlab="Name",ylab="ScienceScore",
19 col=fill_colors,
20 names.arg=(paste(substr(FirstName,1,1),".",LastName)), #设定横坐标名称
21 border=NA, #条形框不设置边界线
22 font.main=4,
23 font.lab=3,
24 beside=TRUE)
25 legend(x=8.8,y=100, #左上角点的坐标
26 cex=.8, #缩放比例
27 inset=5,
28 c("Excellent","Good","Ordinary","Bad"),
29 pch=c(15,16,17,19), #图例中的符号
30 col=c("red","yellow","blue","green"),
31 bg="#821122", #背景色
32 xpd=TRUE, #可以在绘图区之外显示
33 text.font=8,
34 text.width=.6,
35 text.col=c("red","yellow","blue","green")
36 )
遇到的问题说明:
起初在设置了20行的名称时,显示了全名,因此出现了一下情况:
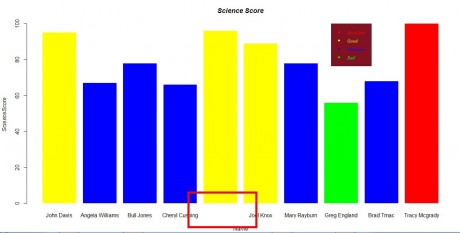
因为名称太挤,显示不出来。
解决办法有三:
-
保存img时,增大像素值;
-
把名词改为简写,即John Davis——>J.Davis
-
把名称倾斜,与水平线呈一定的夹角
-
利用cex.names=.8对条形图的表情进行微调(减小字号)
由于3没有找到相应的设置参数,所以这里采用了第二种方法。
最后的效果图:
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试详情;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试详情;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;








