R语言使用boosting方法对数据分类与交叉验证
数据分类说明
与bagging方法类似,boosting算法也是先获得简单的分类器,然后通过调整错分样本的权重逐步改进分类器,使得后续分类器能够学习前一轮分类器,adabag实现了AdaBoost.M1和SAMME两个算法,因此用户能够使用adabag包实施集成学习。
数据分类操作
导入包
library(rpart)
library(adabag)
调用adabag包的boosting函数分类器:
churn.boost = boosting(churn ~ .,data = trainset,mfinal = 10,coeflearn = "Freund",boos = FALSE,control = rpart.control(maxdepth = 3))
使用boosting训练模型对测试数据集进行分类预测:
churn.boost.pred = predict.boosting(churn.boost,newdata = testset)
基于预测结果生成分类表:
churn.boost.pred$confusion
Observed Class
Predicted Class yes no
no 41 858
yes 100 19
根据分类结果计算平均误差:
churn.boost.pred$error
[1] 0.0589391
数据分类原理
boosting算法的思想是通过对弱分类器(单一决策树)的“逐步优化”,使之成为强分类器。假定当前在训练集中存在n个点,对其权重分别赋值Wj(0<= j < n),在迭代的学习过程中(假定迭代次数为m),我们将根据每次迭代的分类结果,不断调整这些点的权重,如果当前这些点分类是正确的,则调低其权值,否则,增加样例点的权值。这样,当整个迭代过程结束时,算法将得到m个合适的模型,最终,通过对每棵决策树加权平均得到最后的预测结果,权值b由每棵决策树的分类质量决定。
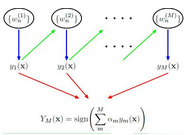
bagging和boosting都采用了集成学习的思想,即将多个弱分类器组成强分类器,两者的不同在于,bagging是组合独立的模型,而boosting则通过在迭代的过程学习的过程中尽可能用正确的分类模型来降低预测误差。与bagging类似,用户也需要指定用于分类的模型的公式与分类数据集,用户还要自己指定诸如迭代次数(mfinal),权重更新系数(coeflearn)、观测值权重(boos)以及rpart的控制方法(单一决策树)等参数,本例中迭代次数为设置为10,采用Freund(AdaBoost.M1算法实现的方法)作为系数(coeflearn),设置boos的值是“false”,最大深度为3。
交叉验证说明
adabag包支持对boosting方法的交叉验证,该功能可以通过boosting.cv实现。
交叉验证操作
获得boosting方法交叉验证后的最小估计错误:
调用boosting.cv对训练数据集实施交叉验证:
churn.boost.cv = boosting.cv(churn ~ .,v = 10,data = trainset,mfinal = 5,control=rpart.control(cp = 0.01))
从boosting结果生成混淆矩阵
churn.boost.cv$confusion
Observed Class
Predicted Class yes no
no 103 1936
yes 239 37
得到boosting的平均误差:
churn.boost.cv$error
[1] 0.06047516
交叉验证原理
函数参数v值设置为10,mfinal的值设置为5,boosting算法会执行一个5次迭代的10折交叉验证,另外可以设置参数进行rpart的匹配控制。我们将复杂度参数设置为0.01。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330