用python-pandas作图矩阵
我们在采用机器学习算法对数据进行分析时,首先要对数据进行了解,而了解数据最快速的方式就是可视化。但是作者可视化采用的方法对很多data都通用,且采用的是各种图形的图矩阵,如直方图、散点图矩阵等等。本文就根据作者的分析来介绍如何运用pandas作各种矩阵图。
(1)数据
数据为PimaIndians dataset,在作者的代码中包含该数据来源网址,即皮马印第安人糖尿病数据集,样本个数有768个,包含变量有:
Preg:怀孕次数
Plas:口服葡萄糖耐量试验中血浆葡萄糖浓度为2小时
Pres:舒张压(mm Hg)
Skin:三头肌皮褶厚度(mm)
test :2小时血清胰岛素(μU/ml)
mass:体重指数(kg /(身高(m))^ 2)
pedi:糖尿病血统功能
age:年龄(岁)
class:类变量(0或1),估计是性别。
(2)Histograms(直方图矩阵)
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] #设置变量名
data = pandas.read_csv(url, names=names) #采用pandas读取csv数据
data.hist()
plt.show()


但是,我们看到图形并不协调,存在变量与坐标重叠的情况,我们可以调整hist()的参数来解决,包括对x轴、y轴标签大小的调节((xlabelsize,ylabelsize),整个图形布局大小的调节figsize:
data.hist(xlabelsize=7,ylabelsize=7,figsize=(8,6)) #
plt.show()


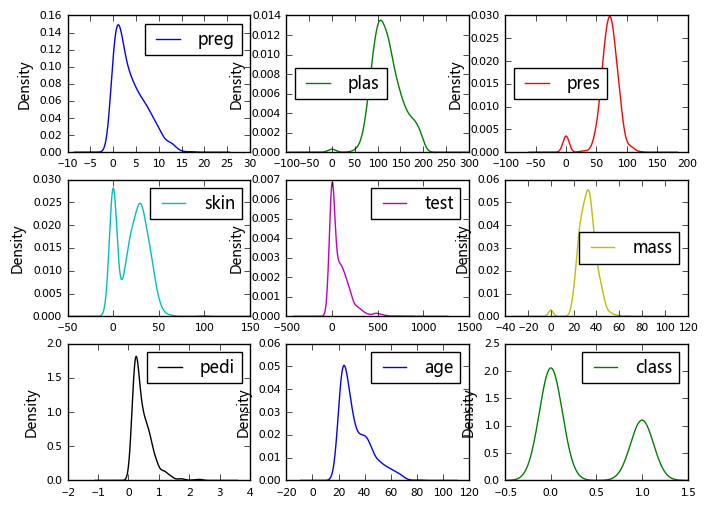
可以看到每一个变量的分布情况,其中mass、plas、pres呈现一定的正态分布,其他除了class之外,基本上左偏。
(3)Density Plots(密度图矩阵)
data.plot(kind='density', subplots=True, layout=(3,3), sharex=False,fontsize=8,figsize=(8,6))
plt.show()
原始代码输出后仍然存在重叠的地方,在这里加入了对图中坐标文字fontsize,以及整体布局大小figsize。

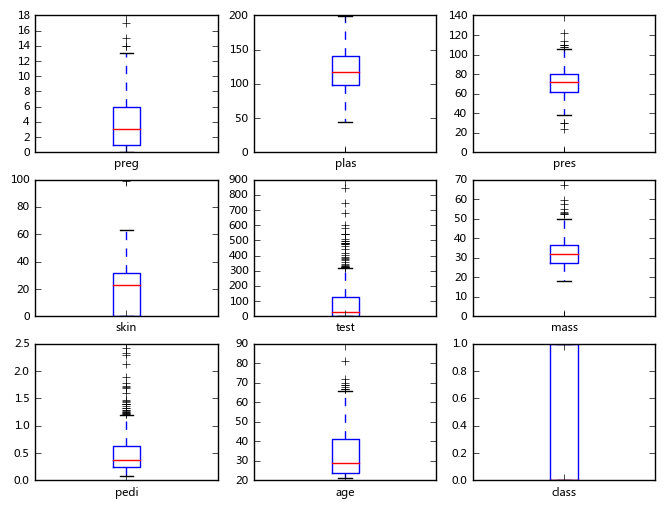
(4)箱线图矩阵(Box and Whisker Plots)
data.plot(kind='box', subplots=True, layout=(3,3), sharex=False, sharey=False, fontsize=8,figsize=(8,6))
plt.show()
与(3)类似,在这里注意可以共享x轴和y轴,用了sharex=False, sharey=False的命令。

(5)相关系数矩阵图(Correlation Matrix Plot)
import numpy correlations = data.corr() #计算变量之间的相关系数矩阵 # plot correlation matrix fig = plt.figure() #调用figure创建一个绘图对象 ax = fig.add_subplot(111) cax = ax.matshow(correlations, vmin=-1, vmax=1) #绘制热力图,从-1到1 fig.colorbar(cax) #将matshow生成热力图设置为颜色渐变条 ticks = numpy.arange(0,9,1) #生成0-9,步长为1 ax.set_xticks(ticks) #生成刻度 ax.set_yticks(ticks) ax.set_xticklabels(names) #生成x轴标签 ax.set_yticklabels(names) plt.show()

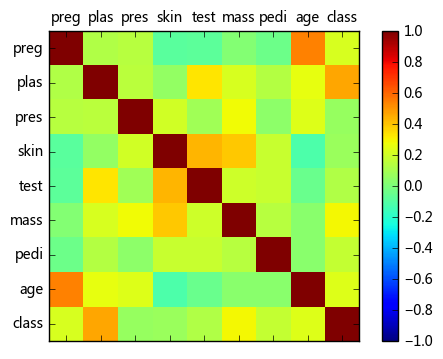 颜色越深表明二者相关性越强。
颜色越深表明二者相关性越强。
(6)散布图矩阵(Scatterplot Matrix)
from pandas.tools.plotting import scatter_matrix
scatter_matrix(data,figsize=(10,10))
plt.show()

CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330