python数据结构之链表详解
数据结构是计算机科学必须掌握的一门学问,之前很多的教材都是用C语言实现链表,因为c有指针,可以很方便的控制内存,很方便就实现链表,其他的语言,则没那么方便,有很多都是用模拟链表,不过这次,我不是用模拟链表来实现,因为python是动态语言,可以直接把对象赋值给新的变量。
好了,在说我用python实现前,先简单说说链表吧。在我们存储一大波数据时,我们很多时候是使用数组,但是当我们执行插入操作的时候就是非常麻烦,看下面的例子,有一堆数据1,2,3,5,6,7我们要在3和5之间插入4,如果用数组,我们会怎么做?当然是将5之后的数据往后退一位,然后再插入4,这样非常麻烦,但是如果用链表,我就直接在3和5之间插入4就行,听着就很方便。
那么链表的结构是怎么样的呢?顾名思义,链表当然像锁链一样,由一节节节点连在一起,组成一条数据链。
链表的节点的结构如下:

data为自定义的数据,next为下一个节点的地址。
链表的结构为,head保存首位节点的地址:
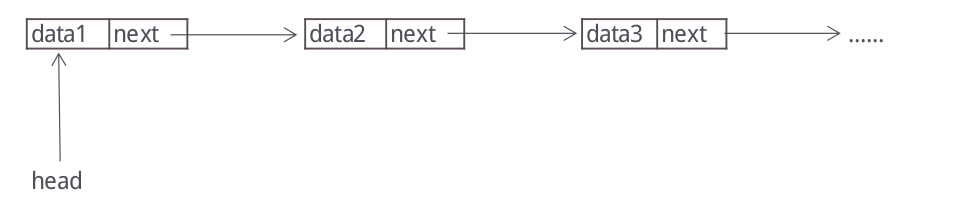
接下来我们来用python实现链表
python实现链表
首先,定义节点类Node:
class Node:
'''
data: 节点保存的数据
_next: 保存下一个节点对象
'''
def __init__(self, data, pnext=None):
self.data = data
self._next = pnext
def __repr__(self):
'''
用来定义Node的字符输出,
print为输出data
'''
return str(self.data)
然后,定义链表类:
链表要包括:
属性:
链表头:head
链表长度:length
方法:
判断是否为空: isEmpty()
def isEmpty(self):
return (self.length == 0
增加一个节点(在链表尾添加): append()
def append(self, dataOrNode):
item = None
if isinstance(dataOrNode, Node):
item = dataOrNode
else:
item = Node(dataOrNode)
if not self.head:
self.head = item
self.length += 1
else:
node = self.head
while node._next:
node = node._next
node._next = item
self.length += 1
删除一个节点: delete()
#删除一个节点之后记得要把链表长度减一
def delete(self, index):
if self.isEmpty():
print "this chain table is empty."
return
if index < 0 or index >= self.length:
print 'error: out of index'
return
#要注意删除第一个节点的情况
#如果有空的头节点就不用这样
#但是我不喜欢弄头节点
if index == 0:
self.head = self.head._next
self.length -= 1
return
#prev为保存前导节点
#node为保存当前节点
#当j与index相等时就
#相当于找到要删除的节点
j = 0
node = self.head
prev = self.head
while node._next and j < index:
prev = node
node = node._next
j += 1
if j == index:
prev._next = node._next
self.length -= 1
修改一个节点: update()
def update(self, index, data):
if self.isEmpty() or index < 0 or index >= self.length:
print 'error: out of index'
return
j = 0
node = self.head
while node._next and j < index:
node = node._next
j += 1
if j == index:
node.data = data
查找一个节点: getItem()
def getItem(self, index):
if self.isEmpty() or index < 0 or index >= self.length:
print "error: out of index"
return
j = 0
node = self.head
while node._next and j < index:
node = node._next
j += 1
return node.data
查找一个节点的索引: getIndex()
def getIndex(self, data):
j = 0
if self.isEmpty():
print "this chain table is empty"
return
node = self.head
while node:
if node.data == data:
return j
node = node._next
j += 1
if j == self.length:
print "%s not found" % str(data)
return
插入一个节点: insert()
def insert(self, index, dataOrNode):
if self.isEmpty():
print "this chain tabale is empty"
return
if index < 0 or index >= self.length:
print "error: out of index"
return
item = None
if isinstance(dataOrNode, Node):
item = dataOrNode
else:
item = Node(dataOrNode)
if index == 0:
item._next = self.head
self.head = item
self.length += 1
return
j = 0
node = self.head
prev = self.head
while node._next and j < index:
prev = node
node = node._next
j += 1
if j == index:
item._next = node
prev._next = item
self.length += 1
清空链表: clear()
def clear(self):
self.head = None
self.length = 0
以上就是链表类的要实现的方法。
执行的结果:
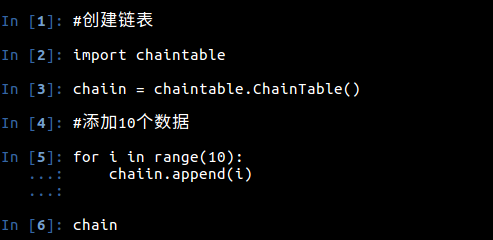
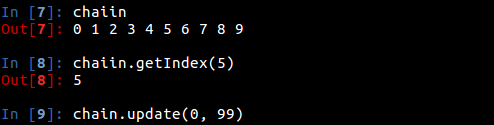
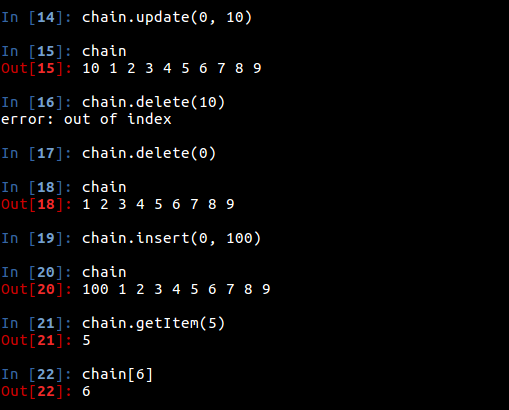
接下来是完整代码:# -*- coding:utf8 -*-
#/usr/bin/env python
class Node(object):
def __init__(self, data, pnext = None):
self.data = data
self._next = pnext
def __repr__(self):
return str(self.data)
class ChainTable(object):
def __init__(self):
self.head = None
self.length = 0
def isEmpty(self):
return (self.length == 0)
def append(self, dataOrNode):
item = None
if isinstance(dataOrNode, Node):
item = dataOrNode
else:
item = Node(dataOrNode)
if not self.head:
self.head = item
self.length += 1
else:
node = self.head
while node._next:
node = node._next
node._next = item
self.length += 1
def delete(self, index):
if self.isEmpty():
print "this chain table is empty."
return
if index < 0 or index >= self.length:
print 'error: out of index'
return
if index == 0:
self.head = self.head._next
self.length -= 1
return
j = 0
node = self.head
prev = self.head
while node._next and j < index:
prev = node
node = node._next
j += 1
if j == index:
prev._next = node._next
self.length -= 1
def insert(self, index, dataOrNode):
if self.isEmpty():
print "this chain tabale is empty"
return
if index < 0 or index >= self.length:
print "error: out of index"
return
item = None
if isinstance(dataOrNode, Node):
item = dataOrNode
else:
item = Node(dataOrNode)
if index == 0:
item._next = self.head
self.head = item
self.length += 1
return
j = 0
node = self.head
prev = self.head
while node._next and j < index:
prev = node
node = node._next
j += 1
if j == index:
item._next = node
prev._next = item
self.length += 1
def update(self, index, data):
if self.isEmpty() or index < 0 or index >= self.length:
print 'error: out of index'
return
j = 0
node = self.head
while node._next and j < index:
node = node._next
j += 1
if j == index:
node.data = data
def getItem(self, index):
if self.isEmpty() or index < 0 or index >= self.length:
print "error: out of index"
return
j = 0
node = self.head
while node._next and j < index:
node = node._next
j += 1
return node.data
def getIndex(self, data):
j = 0
if self.isEmpty():
print "this chain table is empty"
return
node = self.head
while node:
if node.data == data:
return j
node = node._next
j += 1
if j == self.length:
print "%s not found" % str(data)
return
def clear(self):
self.head = None
self.length = 0
def __repr__(self):
if self.isEmpty():
return "empty chain table"
node = self.head
nlist = ''
while node:
nlist += str(node.data) + ' '
node = node._next
return nlist
def __getitem__(self, ind):
if self.isEmpty() or ind < 0 or ind >= self.length:
print "error: out of index"
return
return self.getItem(ind)
def __setitem__(self, ind, val):
if self.isEmpty() or ind < 0 or ind >= self.length:
print "error: out of index"
return
self.update(ind, val)
def __len__(self):
return self.length
以上就是本文的全部内容,希望对大家的学习有所帮助
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330