
作者 | Rekhit Pachanekar来源 | CDA数据分析师
英国数学家,计算机科学家,逻辑学家和密码分析员艾伦·图灵(Alan Turing)推测未来机器会具有智能。
“这就像一个学生,他从老师那里学到了很多东西,但通过自己的工作又增加了很多的东西。当这种情况发生时,我觉得人们有义务将机器视为具有智能。”
为了举例说明机器学习的影响,Man group的AHL Dimension计划是一个51亿美元的对冲基金,部分由AI管理。 该基金开始运作后,到2015年,尽管其管理的资产远远少于该基金,但其机器学习算法却贡献了该基金一半以上的利润。
在阅读了这个博客之后,您将能够理解一些流行的和令人难以置信的机器学习算法背后的基本逻辑,这些算法已经被交易社区所使用,并且作为您踏上创建最佳机器学习算法的基石。他们是:
线性回归的方法最初是在统计学中发展的,用于研究输入和输出数值变量之间的关系,后来被机器学习社区用来基于线性回归方程进行预测。
线性回归的数学表示法是一个线性方程,它结合了一组特定的输入数据(x),以预测该组输入值的输出值(y)。线性方程式为每组输入值分配一个系数,这些系数用希腊字母Beta(β)表示。
下面提到的方程式表示具有两组输入值x1和x2的线性回归模型。y表示模型的输出,β0,β1和β_2是线性方程的系数。
y = β0+ β1x1+ β2x2
当只有一个输入变量时,线性方程式表示一条直线。为了简单起见,考虑β2是等于零,这将意味着,变量x2不会影响线性回归模型的输出。在这种情况下,线性回归将代表一条直线,其等式如下所示。
y = β0+ β1x1
线性回归方程模型的图形如下所示
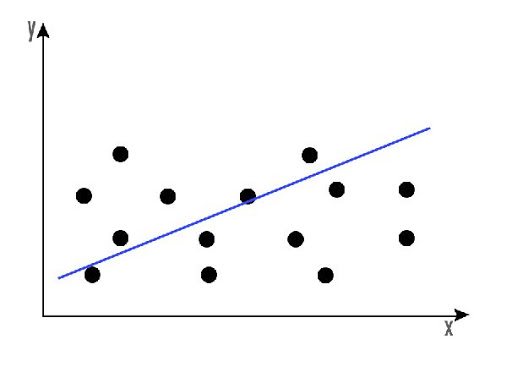
线性回归可以用来发现股票在一段时间内的总体价格趋势。这有助于我们了解价格变动是正向是负向的。
在逻辑回归中,我们的目标是产生一个离散值,即1或0。这有助于我们找到一种确定的方案答案。Logistic回归可以用数学表示为:

逻辑回归模型类似于线性回归来计算输入变量的加权和,但是它通过特殊的非线性函数,逻辑函数或S形函数运行结果,以产生输出y。
S形/逻辑函数由以下方程式给出。
y = 1 / (1+ e-x)
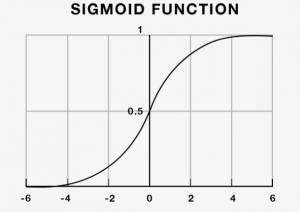
简单地说,logistic回归可以用来预测市场的走向。
K最近邻(KNN)分类的目的是将数据点分为不同的类别,以便我们可以基于相似性度量(例如距离函数)对它们进行分类。
从某种意义上说,KNN不需要一个明确的训练学习阶段,而是由相邻数据点的多数票决定来进行分类。从而将目标数据点分配给在其k个最近的相邻样本中某类别数量最多的类。
让我们考虑将下面图片中的绿色圆圈分为1类和2类的任务。考虑基于1个最近邻居的KNN的情况。在这种情况下,KNN将绿色圆圈分类为1类。现在,让我们将最近邻居的数量增加到3,即3最近邻居。正如您在图中看到的那样,圆圈内有“两个” 2类对象和“一个” 1类对象。KNN将绿色圆圈归为2类对象,因为它形成了大多数对象。

支持向量机(SVM)最初是用于数据分析。首先一组训练实例被输入到SVM算法中,它们分别属于一类别或另一个类别。然后,该算法可以构建一个模型,并开始将新的测试数据分配给它在训练阶段学习到的类别之一。
在支持向量机算法中,创建了一个超平面,该超平面用作类别之间的分界。当支持向量机算法处理一个新的数据点时,根据它出现的某一侧,它将被分类为一种类别。

当涉及到交易时,可以建立支持向量机算法,将股票数据分类为有利的买入、卖出或中性类,然后根据规则对测试数据进行分类。
决策树是一种类似于树的支持决策的工具,可以用来表示因果关系。由于一个原因可能会有多种影响,因此我们将其列出来,非常像带有分支的树。
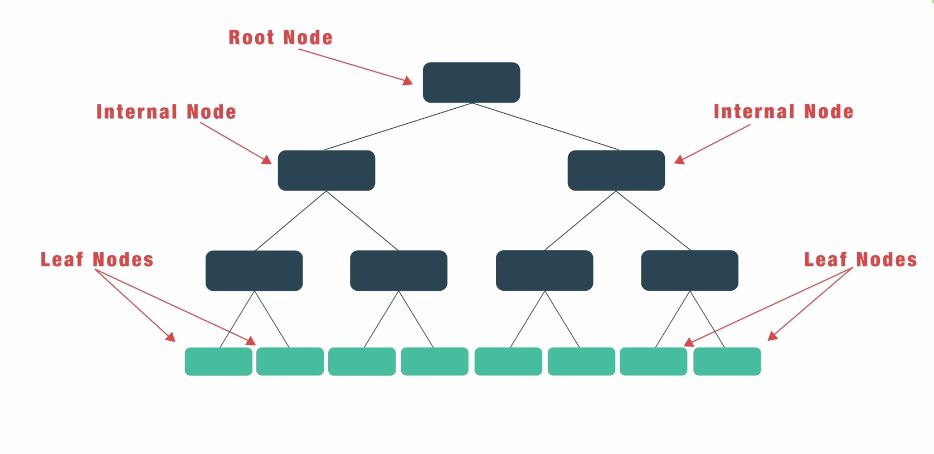
我们可以通过组织输入数据和预测变量,并根据我们指定的一些标准来构建决策树。
建立决策树的主要步骤是:
随机森林由决策树组成,决策树是代表决策过程或统计概率的决策图。这些多个树映射到单个树,称为分类或回归(CART)模型。
为了基于对象的属性对目标对象进行分类,每棵树都给出了一个分类,该分类被称为对该类“投票”。然后,森林选择投票数最多的类别。对于回归树来说,它考虑了不同树的输出的平均值来进行回归。
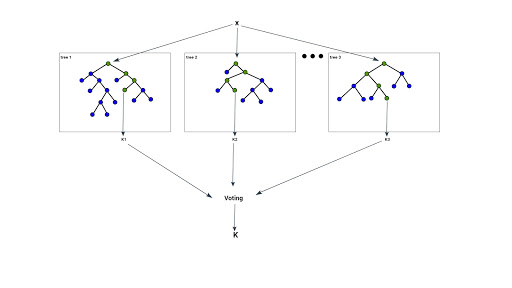
随机森林算法的工作方式如下:
在我们探索世界的过程中,人工神经网络是我们的最高成就之一。如图所示,我们已经创建了多个相互连接的节点,每个圆形节点代表一个人工神经元,箭头代表从一个神经元的输出到另一个神经元的输入的连接。它们模仿了我们大脑中的神经元。简单来说,每个神经元都通过另一个神经元来获取信息,对其进行处理,然后将其作为输出传递给另一个神经元。
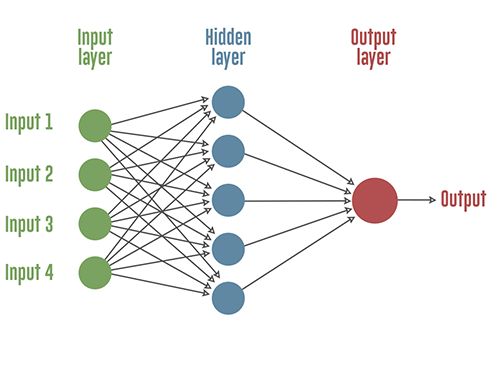
如果我们使用神经网络来发现各种资产类别之间的相互依赖关系,而不是尝试预测买入或卖出选择,则神经网络会更有用。
在这种机器学习算法中,目标是根据数据点的相似性对其进行标记(聚类)。因此,我们没有在算法之前定义聚类,而是算法在前进时找到了这些聚类。
一个简单的例子是,根据足球运动员的数据,我们将使用K-means聚类,并根据他们的相似性对其进行标记。因此,即使没有为算法提供预定义的标签,也可以基于前锋对任意球或成功铲球得分的偏好来对足球运动员进行聚类。
K均值聚类对那些认为不同资产之间可能存在表面上看不到的相似性的交易者是非常有用的。

现在,如果您还记得基本概率,您就会知道,贝叶斯定理的表述方式是,假定我们对与前一事件相关的任何事件都具有先验知识。 它是关于随机事件A和B的条件概率(或边缘概率)的一则定理。其中P(A|B)是在B发生的情况下A发生的可能性。 例如,要检查您到办公室迟到的可能性,您可能想知道您在途中是否会遇到任何形式的交通拥堵。
但是,朴素贝叶斯分类器算法假设两个事件是彼此独立的,这在很大程度上简化了计算。最初,朴素贝叶斯定理只是想被用于进行学术研究,但现在看来,它在现实世界中也表现出色。
朴素贝叶斯算法可以在无完整的数据的情况下,用于查找不同参数之间的简单关系。
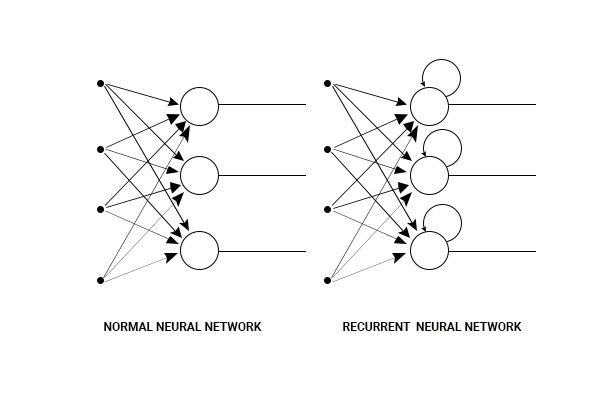
你知道Siri和Google助手在他们的编程中使用RNN吗?RNN本质上是一种神经网络,它在每个节点上都有一个存储器,这使得处理顺序数据变得容易,即一个数据单元依赖于前一个数据单元。
一种解释RNN优于常规神经网络的优势的方法是,我们应该逐个字符地处理一个单词。如果单词是“ trading”,则正常的神经网络节点会在移动到“ d”时忘记字符“ t”,而递归神经网络会记住该字符,因为它具有自己的记忆。
根据Preqin的一项研究,已知1,360种量化基金在其交易过程中使用计算机模型,占所有基金的9%。如果Quantopian这样的公司在测试阶段赚钱,并且实际上投资自己的钱并在实时交易阶段拿钱,则会为个人的机器学习策略组织现金奖励。因此,为了在竞争中领先一步,每个人,无论是数十亿美元的对冲基金还是个人交易,都在试图在其交易策略中理解和实施机器学习模型。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
在数据分析领域,Excel作为一种普及率极高且功能强大的工具,无疑为无数专业人士提供了便捷的解决方案。尽管Excel自带了丰富的功 ...
2025-01-17在这个瞬息万变的时代,许多人都在寻找能让他们脱颖而出的职业。而数据分析师,作为大数据和人工智能时代的热门职业,自然吸引了 ...
2025-01-14Python作为一门功能强大的编程语言,已经成为数据分析和可视化领域的重要工具。无论你是数据分析的新手,还是经验丰富的专业人士 ...
2025-01-10完全靠数据决策,真的靠谱吗? 最近几年,“数据驱动”成了商界最火的关键词之一,但靠数据就能走天下?其实不然!那些真正成功 ...
2025-01-09SparkSQL 结构化数据处理流程及原理是什么?Spark SQL 可以使用现有的Hive元存储、SerDes 和 UDF。它可以使用 JDBC/ODB ...
2025-01-09在如今这个信息爆炸的时代,数据已然成为企业的生命线。无论是科技公司还是传统行业,数据分析正在深刻地影响着商业决策以及未来 ...
2025-01-08“数据为王”相信大家都听说过。当前,数据信息不再仅仅是传递的媒介,它成为了驱动经济发展的新燃料。对于企业而言,数据指标体 ...
2025-01-07在职场中,当你遇到问题的时候,如果感到无从下手,或者抓不到重点,可能是因为你掌握的思维模型不够多。 一个好用的思维模型, ...
2025-01-06在现代企业中,数据分析师扮演着至关重要的角色。每天都有大量数据涌入,从社交媒体到交易平台,数据以空前的速度和规模生成。面 ...
2025-01-06在职场中,许多言辞并非表面意思那么简单,有时需要听懂背后的“潜台词”。尤其在数据分析的领域里,掌握常用术语就像掌握一门新 ...
2025-01-04在当今信息化社会,数据分析已成为各行各业的核心驱动力。它不仅仅是对数字进行整理与计算,而是在数据的海洋中探寻规律,从而指 ...
2025-01-03又到一年年终时,各位打工人也迎来了展示成果的关键时刻 —— 年终述职。一份出色的年终述职报告,不仅能全面呈现你的工作价值, ...
2025-01-03在竞争激烈的商业世界中,竞品分析对于企业的发展至关重要。今天,我们就来详细聊聊数据分析师写竞品分析的那些事儿。 一、明确 ...
2025-01-03在数据分析的江湖里,有两个阵营总是争论不休。一派信奉“大即是美”,认为数据越多越好;另一派坚守“小而精”,力挺质量胜于规 ...
2025-01-02数据分析是一个复杂且多维度的过程,从数据收集到分析结果应用,每一步都是对信息的提炼与升华。可视化分析结果,以图表的形式展 ...
2025-01-02在当今的数字化时代,数据分析师扮演着一个至关重要的角色。他们如同现代企业的“解密专家”,通过解析数据为企业提供决策支持。 ...
2025-01-02数据分析报告至关重要 一份高质量的数据分析报告不仅能够揭示数据背后的真相,还能为企业决策者提供有价值的洞察和建议。 年薪 ...
2024-12-31数据分析,听起来好像是技术大咖的专属技能,但其实是一项人人都能学会的职场硬核能力!今天,我们来聊聊数据分析的核心流程,拆 ...
2024-12-31提到数据分析,你脑海里可能会浮现出一群“数字控”抱着电脑,在海量数据里疯狂敲代码的画面。但事实是,数据分析并没有你想象的 ...
2024-12-31关于数据分析师是否会成为失业高危职业,近年来的讨论层出不穷。在这个快速变化的时代,技术进步让人既兴奋又不安。今天,我们从 ...
2024-12-30






