作者 | Jason Brownlee
编译 | CDA数据分析师
特征选择是在开发预测模型时减少输入变量数量的过程。
希望减少输入变量的数量,以减少建模的计算成本,并且在某些情况下,还需要改善模型的性能。
基于特征的特征选择方法包括使用统计信息评估每个输入变量和目标变量之间的关系,并选择与目标变量关系最密切的那些输入变量。尽管统计方法的选择取决于输入和输出变量的数据类型,但是这些方法可以快速有效。
这样,当执行基于过滤器的特征选择时,对于机器学习从业者来说,为数据集选择适当的统计量度可能是具有挑战性的。
在本文中,您将发现如何为统计数据和分类数据选择统计度量,以进行基于过滤器的特征选择。
阅读这篇文章后,您将知道:
-
特征选择技术主要有两种类型:包装器和过滤器方法。
-
基于过滤器的特征选择方法使用统计量度对可以过滤以选择最相关特征的输入变量之间的相关性或依赖性进行评分。
-
必须根据输入变量和输出或响应变量的数据类型仔细选择用于特征选择的统计量度。
总览
本教程分为三个部分:他们是:
-
特征选择方法
-
筛选器特征选择方法的统计信息
-
功能选择提示和技巧
特征选择方法旨在将输入变量的数量减少到被认为对模型最有用的那些变量,以预测目标变量。
一些预测性建模问题包含大量变量,这些变量可能会减慢模型的开发和训练速度,并需要大量的系统内存。此外,当包含与目标变量无关的输入变量时,某些模型的性能可能会降低。
特征选择算法有两种主要类型:包装器方法和过滤器方法。
包装器特征选择方法会创建许多具有不同输入特征子集的模型,并根据性能指标选择那些导致最佳性能模型的特征。这些方法与变量类型无关,尽管它们在计算上可能很昂贵。RFE是包装功能选择方法的一个很好的例子。
包装器方法使用添加和/或删除预测变量的过程来评估多个模型,以找到使模型性能最大化的最佳组合。
—第490页,应用预测建模,2013年。
过滤器特征选择方法使用统计技术来评估每个输入变量和目标变量之间的关系,这些分数将用作选择(过滤)将在模型中使用的那些输入变量的基础。
过滤器方法在预测模型之外评估预测变量的相关性,然后仅对通过某些标准的预测变量进行建模。
—第490页,应用预测建模,2013年。
通常在输入和输出变量之间使用相关类型统计量度作为过滤器特征选择的基础。这样,统计量度的选择高度依赖于可变数据类型。
常见的数据类型包括数字(例如高度)和类别(例如标签),但是每种数据类型都可以进一步细分,例如数字变量的整数和浮点数,类别变量的布尔值,有序数或标称值。
常见的输入变量数据类型:
-
数值变量
-
整数变量。
-
浮点变量。
-
分类变量
-
布尔变量(二分法)。
-
序数变量。
-
标称变量。
对变量的数据类型了解得越多,就越容易为基于过滤器的特征选择方法选择适当的统计量度。
在下一部分中,我们将回顾一些统计量度,这些统计量度可用于具有不同输入和输出变量数据类型的基于过滤器的特征选择。
基于过滤器的特征选择方法的统计信息
在本节中,我们将考虑两大类变量类型:数字和类别;同样,要考虑的两个主要变量组:输入和输出。
输入变量是作为模型输入提供的变量。在特征选择中,我们希望减小这些变量的大小。输出变量是模型要预测的变量,通常称为响应变量。
响应变量的类型通常指示正在执行的预测建模问题的类型。例如,数字输出变量指示回归预测建模问题,而分类输出变量指示分类预测建模问题。
-
数值输出:回归预测建模问题。
-
分类输出:分类预测建模问题。
通常在基于过滤器的特征选择中使用的统计量度是与目标变量一次计算一个输入变量。因此,它们被称为单变量统计量度。这可能意味着在过滤过程中不会考虑输入变量之间的任何交互。
这些技术大多数都是单变量的,这意味着它们独立地评估每个预测变量。在这种情况下,相关预测变量的存在使选择重要但多余的预测变量成为可能。此问题的明显后果是选择了太多的预测变量,结果出现了共线性问题。
—第499页,应用预测建模,2013年。
使用此框架,让我们回顾一些可用于基于过滤器的特征选择的单变量统计量度。
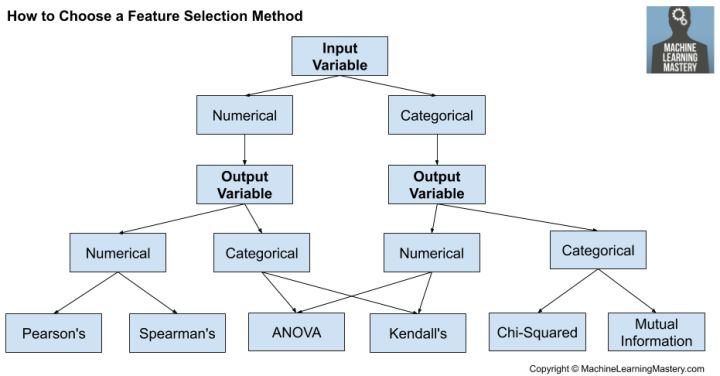
如何选择机器学习的特征选择方法
数值输入,数值输出
这是带有数字输入变量的回归预测建模问题。
最常见的技术是使用相关系数,例如使用Pearson进行线性相关,或使用基于秩的方法进行非线性相关。
-
皮尔逊相关系数(线性)。
-
Spearman的秩系数(非线性)
数值输入,分类输出
这是带有数字输入变量的分类预测建模问题。
这可能是最常见的分类问题示例,
同样,最常见的技术是基于相关的,尽管在这种情况下,它们必须考虑分类目标。
-
方差分析相关系数(线性)。
-
肯德尔的秩系数(非线性)。
Kendall确实假定类别变量为序数。
分类输入,数值输出
这是带有分类输入变量的回归预测建模问题。
这是回归问题的一个奇怪示例(例如,您不会经常遇到它)。
不过,您可以使用相同的“ 数值输入,分类输出 ”方法(如上所述),但要相反。
分类输入,分类输出
这是带有分类输入变量的分类预测建模问题。
分类数据最常见的相关度量是卡方检验。您还可以使用信息论领域的互信息(信息获取)。
实际上,互信息是一种强大的方法,可能对分类数据和数字数据都有用,例如,与数据类型无关。
功能选择提示和技巧
使用基于过滤器的功能选择时,本节提供了一些其他注意事项。
相关统计
scikit-learn库提供了大多数有用的统计度量的实现。
例如:
-
皮尔逊相关系数:f_regression()
-
方差分析:f_classif()
-
Chi-Squared:chi2()
-
共同信息:Mutual_info_classif()和Mutual_info_regression()
此外,SciPy库提供了更多统计信息的实现,例如Kendall的tau(kendalltau)和Spearman的排名相关性(spearmanr)。
选择方式
一旦针对具有目标的每个输入变量计算出统计信息,scikit-learn库还将提供许多不同的过滤方法。
两种比较流行的方法包括:
-
选择前k个变量:SelectKBest
-
选择顶部的百分位数变量:SelectPercentile
我经常自己使用SelectKBest。
转换变量
考虑转换变量以访问不同的统计方法。
例如,您可以将分类变量转换为序数(即使不是序数),然后查看是否有任何有趣的结果。
您还可以使数值变量离散(例如,箱);尝试基于分类的度量。
一些统计度量假设变量的属性,例如Pearson假设假定观测值具有高斯概率分布并具有线性关系。您可以转换数据以满足测试的期望,然后不管期望如何都可以尝试测试并比较结果。
最好的方法是什么?
没有最佳功能选择方法。
就像没有最佳的输入变量集或最佳的机器学习算法一样。至少不是普遍的。
相反,您必须使用认真的系统实验来发现最适合您的特定问题的方法。
尝试通过不同的统计量度来选择适合不同特征子集的各种不同模型,并找出最适合您的特定问题的模型。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;















 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330