久经考场的你肯定对于很多概念类题目里问到的 “区别和联系” 不陌生,与之类似,在统计领域要研究的是数据之间的区别和联系 ,也就是差异性分析 和相关性分析 。本节我们重点关注数据的差异性分析 。
我们知道,比较两个数之间的大小,要么前后两者求差,要么求比。差值大于零说明前者大于后者。比值大于1说明分子大于分母。
那么如何比较两组数据的差异性呢?大道至简,其实和上面原理类似
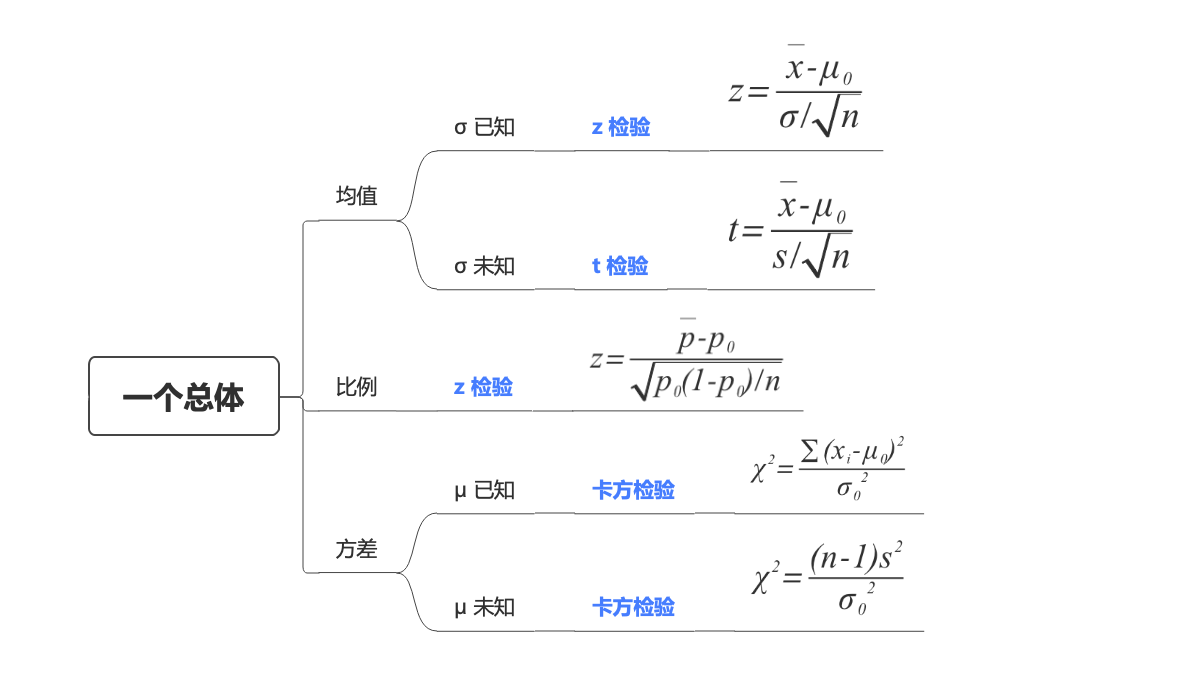
我们先从简单的看起,先比较一组数和一个给定数的差异,即,单个总体的差异性分析:
常见的单个总体差异性的假设检验 分为3个类型:均值、比例、方差
一个总体均值的假设检验 (指定值和样本均值) 顾名思义,就是检验指定值与样本均值的差异,按
① 接下来我们用代码举例实现一下你就明白怎么用了:
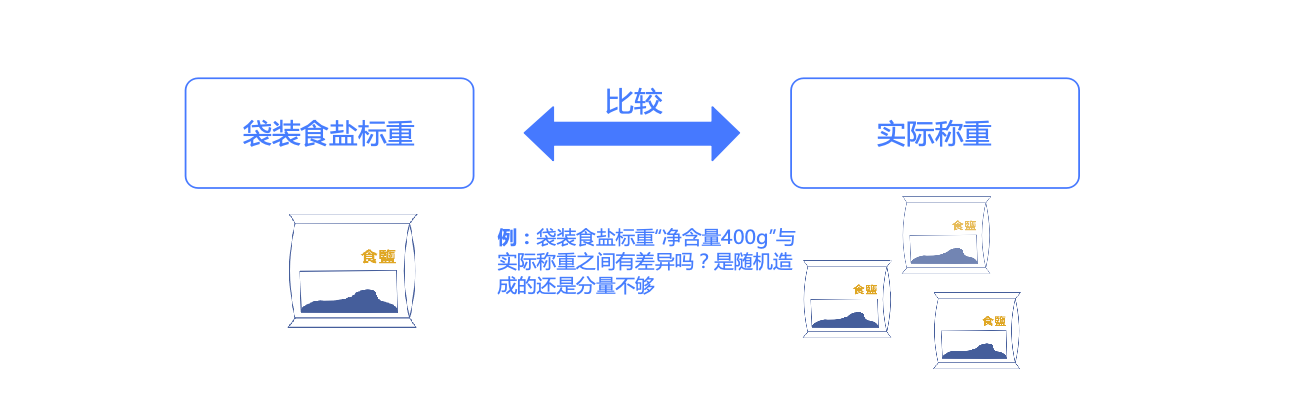
例5.1 检验一批厂家生产的红糖是否够标重
监督部门称了50包标重500g的红糖,均值是498.35g,少于所标的500g。对于厂家生产的这批红糖平均起来是否够份量,需要统计检验。
分析过程:
由于厂家声称每袋500g,因此原假设为总体均值等于500g(被怀疑对象总是放在零假设)。而且由于样本均值少于500g(这是怀疑的根据),把备择假设设定为总体均值少于500g (上面这种备选假设为单向不等式的检验称为单侧检验,而备选假设为不等号“
于是我们有了原假设和备择假设
:
引入相关库、读取数据如下
from scipy import statsimport scipy.statsimport numpy as npimport pandas as pdimport statsmodels.stats.weightstats493.01 ,498.83 ,494.16 ,500.39 ,497.63 ,499.72 ,493.41 ,498.97 ,501.94 ,503.45 ,497.47 ,494.19 ,500.99 ,495.81 ,499.63 ,494.91 ,498.90 ,502.43 ,491.34 ,497.50 ,505.95 ,496.56 ,501.66 ,492.02 ,497.68 ,493.48 ,505.40 ,499.21 ,505.84 ,499.41 ,505.65 ,500.51 ,489.53 ,496.55 ,492.26 ,498.91 ,496.65 ,496.38 ,497.16 ,498.91 ,490.98 ,499.97 ,501.21 ,502.85 ,494.35 ,502.96 ,506.21 ,497.66 ,504.66 ,492.11 ]进行z检验:
z, pval = statsmodels.stats.weightstats.ztest(data, value=500,alternative = 'smaller' )print (z,pval)结论: 选择显著性水平 0.05 的话,P=0.0035 < 0.05, 故应该拒绝原假设。具体来说就是该结果倾向于支持平均重量小于500g的备则假设。
② 例5.2 检验汽车实际排放是否低于其声称的排放标准
汽车厂商声称其发动机排放标准的一个指标平均低于20个单位。在抽查了10台发动机之后,得到下面的排放数据:
17.0 21.7 17.9 22.9 20.7 22.4 17.3 21.8 24.2 25.4
该样本均值为21.13.究竟能否由此认为该指标均值超过20?
分析过程: 由于厂家声称指标平均低于20个单位,因此原假设为总体均值等于20个单位(被怀疑对象总是放在零假设)。而且由于样本均值大于20(这是怀疑的根据),把备择假设设定为总体均值大于20个单位
于是我们有了原假设和备择假设
:
读取数据如下
data = [17.0 , 21.7 , 17.9 , 22.9 , 20.7 , 22.4 , 17.3 , 21.8 , 24.2 , 25.4 ]进行t检验如下:
import scipy.stats'greater' )print (t, pval)结论: 选择显著性水平 0.01 的话,P=0.1243 > 0.05, 故无法拒绝原假设。具体来说就是该结果无法支持指标均值超过20的备则假设。
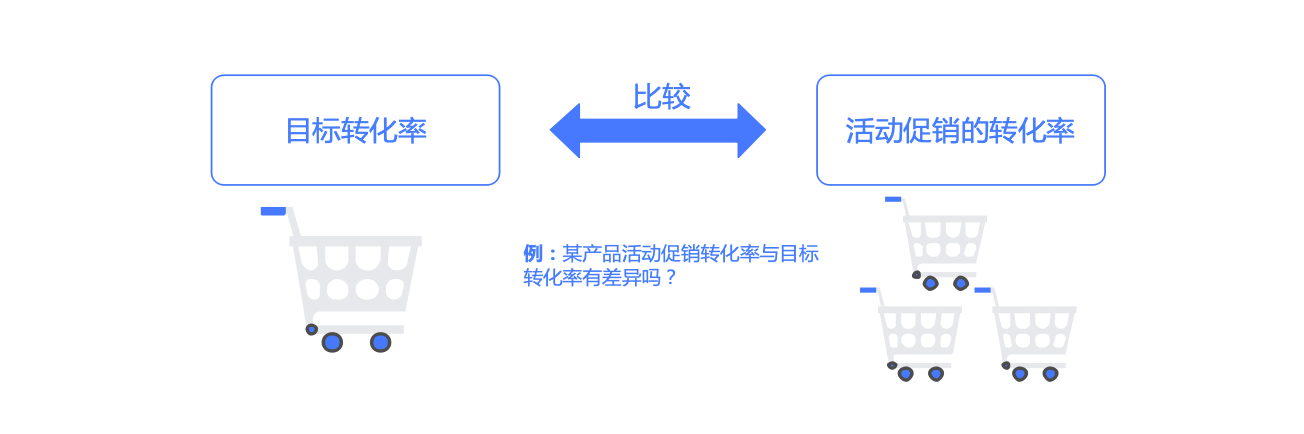
一个总体比例的假设检验 (指定比例和样本比例) 例5.3 检验高尔夫球场女性球员比例是否因促销活动而升高
某高尔夫球场去年打球????????的人当中有20%是女性,为了增加女性球员的比例,该球场推出了一项促销活动来吸引更多的女性参加高尔夫运动,在活动实施了1个月后,球场的研究者想通过统计分析 研究确定高尔夫球场的女性球员比例是否上升,收集到了400个随机样本,其中有100是女性
分析过程: 由于研究的是女性球员所占的比例是否上升,因此选择上侧检验比较合适,备择假设是比例大于20%
:
方法1:用statsmodels.stats.proportion里面的proportions_ztest函数计算(推荐) import numpy as npfrom statsmodels.stats.proportion import proportions_ztest100 400 0.2 0.2 400 'larger' ,prop_var = value)"z统计量:" , z_statistic)"p值:" , p_value)方法2 用手动方式计算 count = 100 400 0.2 0.2 400 def calc_z_score (p_bar, p_0, n) :1 - p_0) / n)**0.5 return z"z统计量:" , z)"p值:" , p)结论: 选择显著性水平 0.05 的话,P=0.0062 < 0.05, 拒绝原假设。具体来说就是该结果支持特定的促销活动能够提升该球场女性运动员比例的备则假设。
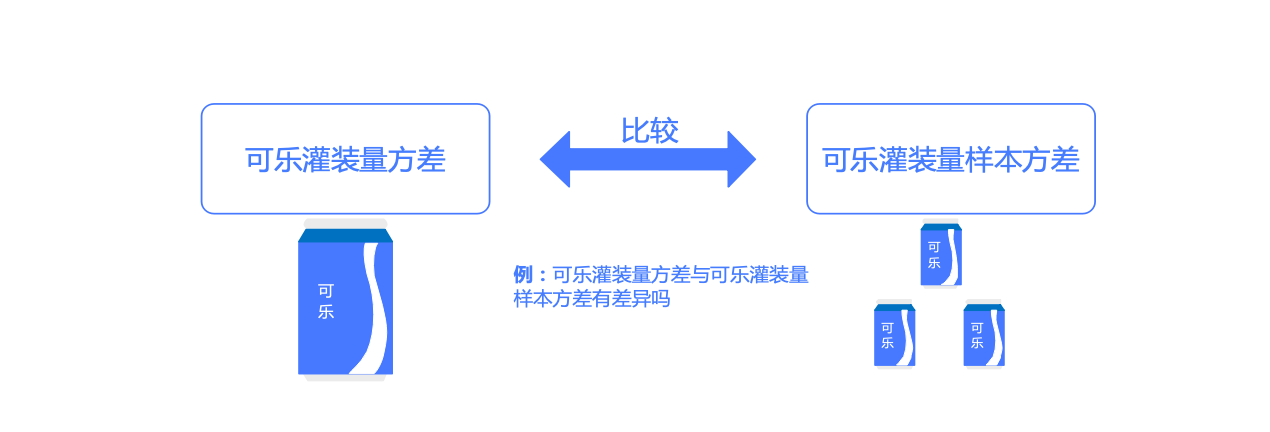
import numpy as np'' '方差 方差 '' if side == 'two-sided' :elif side == 'less' :elif side == 'greater' :return chi_square,p_value例5.4 检验公交车到站时间的方差 是否比规定标准大
某市中心车站为规范化提升市民对于公交车到站时间的满意度,对于公交车的到站时间管理做了规定,标准是到站时间的方差 不超过4。为了检验时间的到站时间的方差 是否过大,随机抽取了24辆公交车的到站时间组成一个样本,得到的样本方差 是 正态分布 ,请分析总体方差 是否过大。
分析过程: 由于研究的是方差 是否过大,因此选择上侧检验比较合适,备择假设是方差 大于4
于是我们有了原假设和备择假设
:
chi_square,p_value = chi2test(sample_var = 4.9, sample_num = 24, sigma_square = 4,side='greater' )print ("p值:" , p_value)结论: 选择显著性水平 0.05 的话,P=0.2092 > 0.05, 无法拒绝原假设。具体来说就是该结果不支持方差 变大的备则假设。
例5.5 检验某考试中心升级题库后考生分数的方差 是否有显著变化
某数据分析师认证考试机构CDA考试中心,历史上的持证人考试分数的方差 为 方差 保持在原有水平上,为了研究该问题,收集到了30份新考题的考分组成的样本,样本方差 是假设检验 。
分析过程:由于目标是希望考试分数的方差 保持原有水平,因此选择双侧检验
于是我们有了原假设和备择假设
:
p_value = chi2test(sample_var = 162, sample_num = 30, sigma_square = 100,side='two-sided' )print ("p值:" , p_value)结论: 选择显著性水平 0.05 的话,P=0.0721 > 0.05, 故无法拒绝原假设。具体来说就是不支持方差 发生了变化的备则假设。
常见的两总体差异性的假设检验 也分3个类型:均值、比例、方差
两总体均值之差的假设检验 (独立样本) 例5.6(数据:drug.txt) 检验某药物在实验组的指标是否低于对照组
为检测某种药物对情绪的影响,对实验组的100名服药者和对照组的150名非服药者进行心理测试,得到相应的某指标。需要检验实验组指标的总体均值正态分布 。相应的假设检验 问题为:
分析过程:由于目标是检验实验组指标的总体均值
于是我们有了原假设和备择假设
:
data = pd.read_table("./t-data/drug.txt" ,sep = ' ' )5 )
ah
id
4.4
2
6.8
2
9.6
2
4.8
2
13.2
1
a = data[data['id' ]==1 ]['ah' ]'id' ]==2 ]['ah' ]''' 'greater' )结论: 选择显著性水平 0.05 的话,p = 0.1816 > 0.05,无法拒绝H0,具体来说就是该结果无法支持实验组均值大于对照组的备则假设。
两总体均值之差的假设检验 (配对样本) 例5.7(数据: diet.txt) 检验减肥前后的重量是否有显著性差异(是否有减肥效果)
这里有两列50对减肥数据。其中一列数据(变量名before)是减肥前的重量,另一列(变量名after)是减肥后的重量(单位: 公斤),人们希望比较50个人在减肥前和减肥后的重量。
分析过程:这里不能用前面的独立样本均值差的检验,这是因为两个样本并不独立。每一个人减肥后的重量都和自己减肥前的重量有关,但不同人之间却是独立的,所以应该用配对样本检验。同时,由于研究的是减肥前后的重量变化,期望减肥前的重量大于减肥后的重量,所以备择假设是期望减肥前的重量大于减肥后的重量
于是我们有了原假设和备择假设:
:
data = pd.read_table("./t-data/diet.txt" ,sep = ' ' )5 )
before
after
58
50
76
71
69
65
68
76
81
75
a = data['before' ]'after' ]'greater' )结论 选择显著性水平 0.05 的话,p = 0.0007 < 0.05,故应该拒绝原假设。具体来说就是该结果倾向支持减肥前后的重量之差大于零(即减肥前重量大于减肥后,也就是有减肥效果)的备则假设。
import numpy as np'two-sided' ):"" "假设检验 的方向,可选'two-sided'(双侧检验,默认), 'greater'(右侧检验), 'less'(左侧检验) "" if side == 'two-sided' :elif side == 'greater' :elif side == 'less' :else :"Invalid side value. Must be 'two-sided', 'greater', or 'less'." )return z_value, p_value例5.8 检验不同保险客户的索赔率是否存在差异
某保险公司抽取了单身与已婚客户的样本,记录了他们在一段数据内的索赔次数,计算了索赔率,现在需要检验两种保险客户的索赔率是否存在差异
分析过程:由于目标比例是否有差异,因此选择比例之差的双侧检验
于是我们有了原假设和备择假设
:
p1 = 0.14 0.09 250 300 'two-sided' )"Z_value:" , z_value)"p_value:" , p_value)结论 选择显著性水平 0.05 的话,p = 0.0648 > 0.05,故应该拒绝原假设。具体来说就是该结果倾向支持两种保险客户的索赔率存在差异的备则假设。
import numpy as np'two-sided' ):"" "方差 ;s2_square:样本2的方差 "" if side=='two-sided' :print ("two-sided" )return F_value,p_valueelif side=='greater' :print ("greater" )return F_value,p_value例5.9 检验不同公交公司的校车到达时间的方差 是否有差异
某学校的校车合同到期,先需要在A、B两个校车供应公司中选择一个,才有到达时间的方差 作为衡量服务质量的标准,较低方差 说明服务质量稳定且水平较高,如果方差 相等,则会选择价格更低的公司,,如果方差 不等,则优先考虑方差 更低的公司。
现收集到了A公司的26次到达时间组成一个样本,方差 68,B公司16次到达时间组成一个样本,方差 是30,请检验AB两个公司的到达时间方差 。
分析过程:由于目标是希望的方差 保持原有水平,因此选择双侧检验。两总体方差 之比用F检验,将方差 较大的A视为总体1
于是我们有了原假设和备择假设
:
f_statistic , p_value= f_test_by_s_square(n1=26 , n2=16 ,s1_square=78 ,s2_square=20 ,side='two-sided' )"F statistic:" , f_statistic)"p-value:" , p_value)结论 选择显著性水平 0.05 的话,p = 0.0083 < 0.05,故拒绝原假设。结果倾向支持AB两个公司的到达时间方差 存在差异的备则假设。
例5.10 检验修完Python课程的学生是否比修完数据库课程的学生考CDA的成绩方差 更大
某高校数据科学专业的学生,修完一门数据库课程的41名学生考CDA的方差 方差 是方差 更大?
分析过程:由于目标是希望修完Python的学生CDA成绩的方差 更大,因此选择上侧检验。两总体方差 之比用F检验,将方差 较大的数据库课程的考试成绩视为总体1,另一个视为总体2,于是我们有了原假设和备择假设
:
f_statistic , p_value= f_test_by_s_square(n1=41, n2=31,s1_square=120,s2_square=80,side='greater' )print ("F statistic:" , f_statistic)print ("p-value:" , p_value)结论 选择显著性水平 0.05 的话,p = 0.1256 > 0.05,故无法原假设。结果无法支持修完数据库的学生要比修完Python的学生CDA成绩的方差 更大的备则假设。
关于知识的学习,你会发现有很多相似的逻辑,抓住问题的本质去理解的话就没那么复杂了,比如概念题里面的 区别和联系 延伸到数据分析里的差异性和相关性 ;再比如计算机数据结构 里的 树、森林、网络 到机器学习 里面的决策树 、随机森林 、神经网络 互联网、区块链到元宇宙 ,都是想通过技术的手段去刻画客观世界;算法应用里面的图像识别 、语音识别,替代人的眼耳鼻舌身意 中的前二者去感知世界。抓住了问题的本质不仅可以帮助我们理解知识,还可以将一个领域的知识或模型迁移到另一个领域加以创新和应用。
假设检验 背后的故事:统计学史上最著名的女士品茶
下期将为大家带来《统计学极简入门》之 方差 分析
这里分享一个你一定用得到的小程序——CDA数据分析师考试小程序。
它是专为CDA数据分析认证考试报考打造的一款小程序。可以帮你快速报名考试、查成绩、查证书、查积分,通过该小程序,考生可以享受更便捷的服务。
扫码加入CDA小程序,与圈内考生一同学习、交流、进步!













 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330