8. 再看t检验、F检验、 前面在假设检验 的部分经学过t检验、F检验、
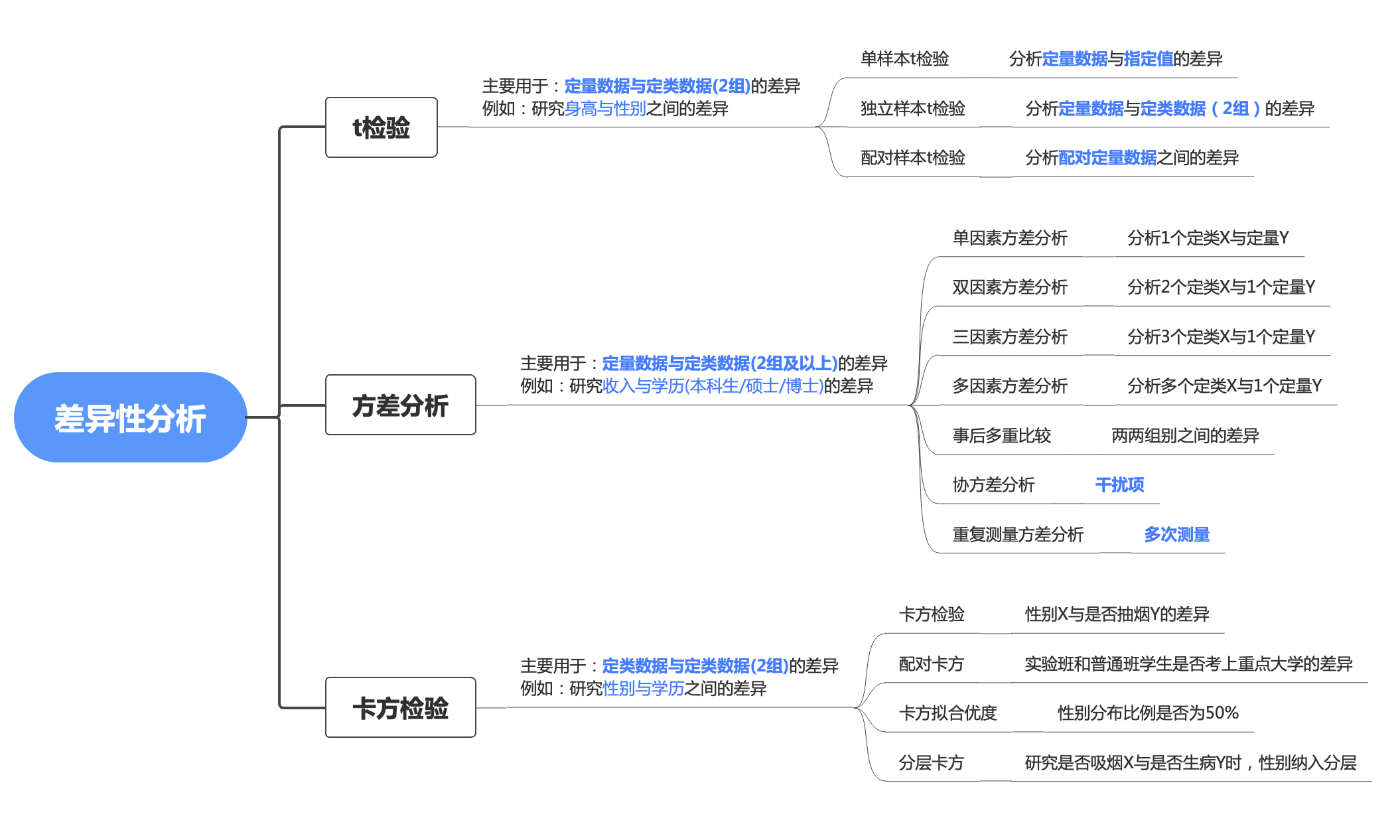
t检验 针对不同的场景,主要分为单样本T检验、独立样本T检验、配对样本T检验:
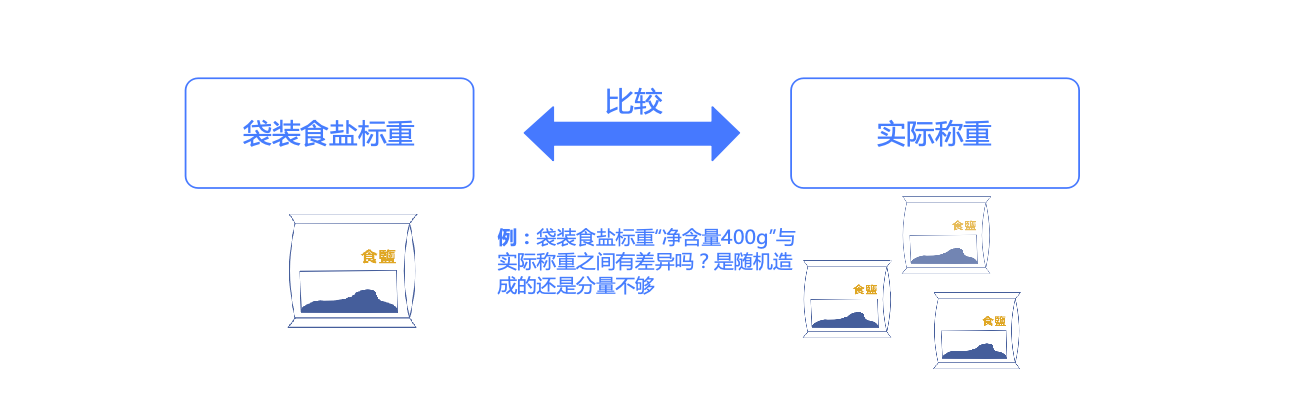
单样本的t检验 主要用于分析 一组定量数据 与 指定值 的差异,例如检验食盐的实际称重是否不够标重的份量。
单样本T检验需要满足正态分布 的假设,若不满足可采用单样本Wilcoxon检验 。
例5.2 检验汽车实际排放是否低于其声称的排放标准
汽车厂商声称其发动机排放标准的一个指标平均低于20个单位。在抽查了10台发动机之后,得到下面的排放数据:
17.0 21.7 17.9 22.9 20.7 22.4 17.3 21.8 24.2 25.4
该样本均值为21.13.究竟能否由此认为该指标均值超过20?
分析过程: 由于厂家声称指标平均低于20个单位,因此原假设为总体均值等于20个单位(被怀疑对象总是放在零假设)。而且由于样本均值大于20(这是怀疑的根据),把备择假设设定为总体均值大于20个单位
于是我们有了原假设和备择假设
:
读取数据如下
data = [17.0 , 21.7 , 17.9 , 22.9 , 20.7 , 22.4 , 17.3 , 21.8 , 24.2 , 25.4 ]分步骤计算过程如下:
步骤一 :计算样本均值
用Python:
x_bar = np.array(data).mean()步骤二 :计算样本标准差
用Python计算:
s = np.sqrt(((data-x_bar)**2).sum()/len(data))步骤三 :计算统计量
t = (x_bar - 20)/(s/np.sqrt(len(data)-1))步骤四 :查表或用软件查询p值与
p_value = scipy.stats.t.sf(t,len(data)-1 )结论: 选择显著性水平 0.01 的话,P=0.1243 > 0.05, 故无法拒绝原假设。具体来说就是该结果无法支持指标均值超过20的备则假设。说明发动机排放指标是不合格的。
对于以上过程,我们也可以用scipy.stats.ttest_1samp函数,一步到位进行t检验,直接返回的就是t统计量和p值:
import scipy.stats'greater' )print (t, pval)结论: 选择显著性水平 0.01 的话,P=0.1243 > 0.05, 故无法拒绝原假设。具体来说就是该结果无法支持指标均值超过20的备则假设。
独立样本的t检验 主要用于分析定量数据 和**定类数据(2组)**的差异。原理是推论差异发生的概率,从而比较两个平均数的差异是否显著。通俗的说就是用样本均数和已知总体均数进行比较,来观察此组样本与总体的差异性。
例如有一个班的学生身高数据,如果学生的身高服从正态分布 ,想要研究身高和性别的关系,这个时候就相当于是两个独立样本。
独立样本的T检验也需要满足正态分布 Wilcoxon检验(也称MannWhitney检验); 如果满足但方差 不等可采用 Welch T检验
计算公式如下:
方差 。
从计算公式能看出来,t越小则两组数据差异性越小。具体多小就根据置信度和自由度查表对比理论统计量的大小得出两组数据差异性是否显著。
例5.6(数据:drug.txt) 检验某药物在实验组的指标是否低于对照组
为检测某种药物对情绪的影响,对实验组的100名服药者和对照组的150名非服药者进行心理测试,得到相应的某指标。需要检验实验组指标的总体均值正态分布 。相应的假设检验 问题为:
分析过程:由于目标是检验实验组指标的总体均值
于是我们有了原假设和备择假设
:
data = pd.read_table("./t-data/drug.txt" ,sep = ' ' )5 )
ah
id
4.4
2
6.8
2
9.6
2
4.8
2
13.2
1
a = data[data['id' ]==1 ]['ah' ]'id' ]==2 ]['ah' ]''' 'greater' )结论: 选择显著性水平 0.05 的话,p = 0.1816 > 0.05,无法拒绝H0,具体来说就是该结果无法支持实验组均值大于对照组的备则假设。
配对样本t检验 主要用于分析配对定量数据 的差异。
常见的使用场景有:
①同一对象处理前后的对比(同一组人员采用同一种减肥方法前后的效果对比);
②同一对象采用两种方法检验的结果的对比(同一组人员分别服用两种减肥药后的效果对比);
③配对的两个对象分别接受两种处理后的结果对比(两组人员,按照体重进行配对,服用不同的减肥药,对比服药后的两组人员的体重)。
例如,假设一个班上男女生的成绩不存在差异,显著性水平为0.05,可理解为只有5%的概率会出现“男女生成绩差异显著”的情况,若计算出的检验p值若小于0.05,则可以拒绝原假设。反之不能拒绝原假设。
此外,t检验注意事项
①无论哪种t检验、都要数据服从正态或者近似正态分布 。正态性的检验方法有:正态图、正态性检验、P-P图/Q-Q图等。
②两个独立样本的t检验,通常需要先进行F检验(方差 齐次检验),检验两个独立样本的方差 是否相同,若两总体方差 相等,则直接用t检验,若不等,可采用t’检验或变量变换或秩和检验等方法。
例5.7(数据: diet.txt) 检验减肥前后的重量是否有显著性差异(是否有减肥效果)
这里有两列50对减肥数据。其中一列数据(变量名before)是减肥前的重量,另一列(变量名after)是减肥后的重量(单位: 公斤),人们希望比较50个人在减肥前和减肥后的重量。
分析过程:这里不能用前面的独立样本均值差的检验,这是因为两个样本并不独立。每一个人减肥后的重量都和自己减肥前的重量有关,但不同人之间却是独立的,所以应该用配对样本检验。同时,由于研究的是减肥前后的重量变化,期望减肥前的重量大于减肥后的重量,所以备择假设是期望减肥前的重量大于减肥后的重量
于是我们有了原假设和备择假设:
:
步骤一 、计算两组样本数据差值d,即58-50,76-71,69-65,68-76,81-75
d = data['before' ] - data['after' ]步骤二 、计算差值d的平均值
d_bar = ( d).sum()/len(data)步骤三 、计算差值d的标准差
s_d = np.sqrt(((d -d_bar)**2).sum()/(len(data)-1))步骤四 、计算统计量t,计算公式为
t = (d_bar)/(s_d/np.sqrt(len(data))) 计算p值
p_value = scipy.stats.t.sf(t, len(data)-1)其中
结论 选择显著性水平 0.05 的话,p = 0.0007 < 0.05,故应该拒绝原假设。具体来说就是该结果倾向支持减肥前后的重量之差大于零(即减肥前重量大于减肥后,也就是有减肥效果)的备则假设。
同样的,我们用现成的函数 stats.ttest_rel,一步到位进行t检验,直接返回的就是t统计量和p值:
data = pd.read_table("./t-data/diet.txt" ,sep = ' ' )5 )
before
after
58
50
76
71
69
65
68
76
81
75
a = data['before' ]'after' ]'greater' )结论 选择显著性水平 0.05 的话,p = 0.0007 < 0.05,故应该拒绝原假设。具体来说就是该结果倾向支持减肥前后的重量之差大于零(即减肥前重量大于减肥后,也就是有减肥效果)的备则假设。
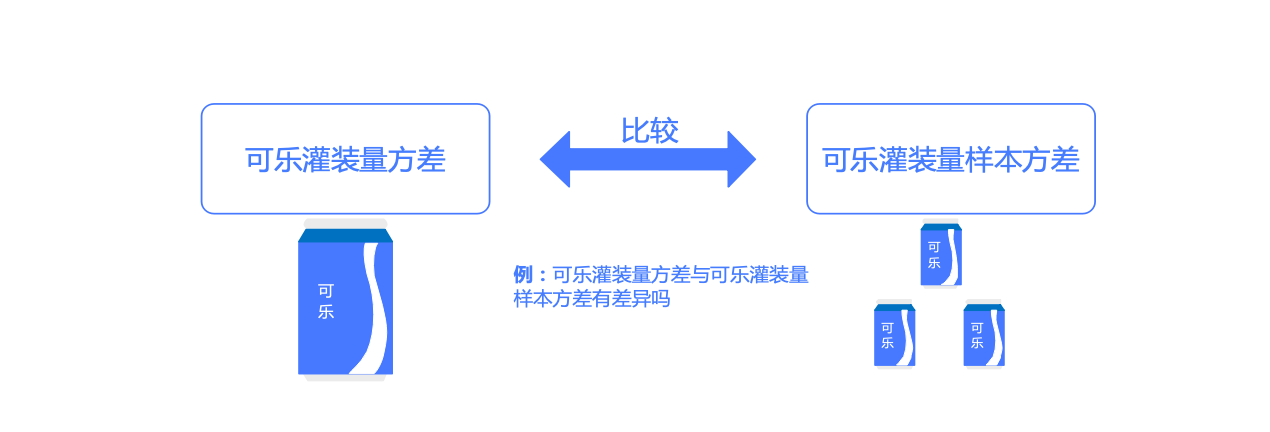
F检验 F检验(F-test),最常用的别名叫做联合假设检验 (英语:joint hypotheses test),此外也称方差 比率检验、方差 齐性检验。
用于: 判断两组数据方差 是否存在显著差异。
步骤一:分别计算两组样本数据的均值
步骤二:分别计算两组样本数据的标准方差 的平方
步骤三:计算两组样本数据标准 方差 的平方比
得到F值后根据两组数据的自由度和置信度查表对比,同样的,F值也是越小越说明差异性不显著。
stats模块中虽然没有f检验的函数,但是却有着f分布的生成函数,可以利用其进行f检验:
import numpy as npprint ("F statistic:" , f_statistic)print ("p-value:" , p_value)也可以引入sklearn进行f检验
print (F) print (pval)print (indices)numpy as npprint ("F values:" , f_values)print ("p-values:" , p_values)例5.10(两总体方差 之比的假设检验 ) 检验修完Python课程的学生是否比修完数据库课程的学生考CDA的成绩方差 更大
某高校数据科学专业的学生,修完一门数据库课程的41名学生考CDA的方差 方差 是方差 更大?
分析过程:由于目标是希望修完Python的学生CDA成绩的方差 更大,因此选择上侧检验。两总体方差 之比用F检验,将方差 较大的数据库课程的考试成绩视为总体1
于是我们有了原假设和备择假设
:
numpy as np'two-sided' ):"" "方差 方差 "" if side=='two-sided' :print ("two-sided" )return F_value,p_valueelif side=='greater' :print ("greater" )return F_value,p_value'greater' )print ("F statistic:" , f_statistic)print ("p-value:" , p_value)结论 选择显著性水平 0.05 的话,p = 0.1256 > 0.05,故无法原假设。结果无法支持修完数据库的学生要比修完Python的学生CDA成绩的方差 更大的备则假设。
卡方检验(chi-square test),也就是χ2检验,是以
之前假设检验 一节中,我们知道卡方检验可以做指定方差 和样本方差 是否有差异
例5.5 检验某考试中心升级题库后考生分数的方差 是否有显著变化
某数据分析师认证考试机构CDA考试中心,历史上的持证人考试分数的方差 为 方差 保持在原有水平上,为了研究该问题,收集到了30份新考题的考分组成的样本,样本方差 是假设检验 。
分析过程:由于目标是希望考试分数的方差 保持原有水平,因此选择双侧检验
于是我们有了原假设和备择假设
:
import numpy as np'' '方差 方差 '' if side == 'two-sided' :elif side == 'less' :elif side == 'greater' :return chi_square,p_value'two-sided' )print ("p值:" , p_value)结论: 选择显著性水平 0.05 的话,P=0.0721 > 0.05, 故无法拒绝原假设。具体来说就是不支持方差 发生了变化的备则假设。换句话说新题型的方差 依然保持在原有水平上
那么,卡方检验还有什么应用呢?
统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差 程度越大;反之,二者偏差 越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。
卡方值计算公式:
①卡方优度检验
对一列数据进行统计检验,分析单个分类变量实际观测的比例与期望的比例是否一致。
②配对卡方
研究实验过程中,用不同方法检测同一批人,看两个方法的效果是否有显著差异。
③ 交叉表 卡方
研究两组分类变量的关系:如性别与看不看直播是否有关系。
例7.5(交叉表 卡方):性别与对待吸烟的态度之间的相关性
一项研究调查了不同性别的成年人对在公众场合吸烟的态度,结果如表所示。那么,性别与对待吸烟的态度之间的相关程度
python 中stats模块,同样有卡方检验的计算函数
from scipy.stats import chi2_contingencynumpy as npprint (f'卡方值={chi2}, p值={p}, 自由度={dof}' )结论 :p = 0.0118<0.05,拒绝原假设,表明两变量之间的正向关系很显著。
sklearn中的特征 选择中也可以进行卡方检验。
from sklearn.feature_selection import chi2numpy as npfor i in range(len(chi2_stats)):print (f"Feature {i+1}: chi2_stat = {chi2_stats[i]}, p_value = {p_values[i]}" )至此,统计学的描述性统计、推断统计基本告一段落,剩下的贝叶斯、线性回归 、逻辑回归 请读者自行查阅资料进行学习,我们下个系列见!
(PS:可以在评价中写下你想学的系列,包括不限于SQL 、Pandas、Julia、机器学习 、数学建模、数据治理 )
致谢 《统计学极简入门》图文系列教程的写作过程中参考了诸多经典书籍,包括:
人大统计学教授吴喜之老师的 《统计学:从数据到结论》 ;
浙大盛骤教授的 《 概率论 与数理统计》;
辛辛那提大学 David R. Anderson的 《商务经济与统计》 ;
北海道大学的马场真哉的 《用Python动手学统计学》 ;
千叶大学研究院教授栗原伸一的《统计学图鉴》 ;
前阿里巴巴产品专家徐小磊的知乎:磊叔-数据化运营 ;
知乎旧梦的文章T检验、F检验、卡方检验详细分析及应用场景总结 ;
csdn文章T检验、卡方检验、F检验 ;
以及CDA认证考试中心 提供的部分案例数据集
在此一并感谢以上内容的作者!
一死生为虚诞,齐彭殇为妄作。各位加油!
这里分享一个你一定用得到的小程序——CDA数据分析师考试小程序。
它是专为CDA数据分析认证考试报考打造的一款小程序。可以帮你快速报名考试、查成绩、查证书、查积分,通过该小程序,考生可以享受更便捷的服务。
扫码加入CDA小程序,与圈内考生一同学习、交流、进步!












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330