1.统计学简介
听说你已经被统计学劝退,被Python唬住……先别着急划走,看完这篇再说!
先说结论,大多数情况下的学不会都不是知识本身难,而是被知识的传播者劝退的。
比如大佬们授课,虽逻辑严谨、思维缜密,但你只能望其项背,因为大佬们往往无法体会菜鸟的痛苦。再比如一些照本宣科的老师,他们没有深入研究这些知识,无法用通俗的语言帮你解释,只能貌似努力地帮你认真地读完所有PPT……
究其本质而言,这种情况多半是按 “是什么、有什么用,怎么用” 的方式在学,而对在大多数人而言,第一步就学懂“是什么”,或许难度有点大,因为得从定义出发,了解性质,推导出原理,一套流程下来直接劝退了,反而最关心的有什么用、怎么用的问题没有解决。
所以接下来的内容我将用“MVP(最小可行化产品)” 的思路来筛选重点内容,帮你厘清哪些内容是不可或缺及必须要学的。然后以 “有什么用,怎么用,是什么” 的顺序展开,快速提升当你急需Get某个技能时候的学习效率。
另外教程的标题既然含有“极简入门”,那么至少有2个原则:
说“尽量”是因为有些时候,不得不说些废话才能引起你的注意,比如以上内容…
好,我们正式开始!首先来看第一个问题:
1. 数据的种类
我们都知道,一般数据可以分为两类,即定性数据(类别型数据)和定量数据(数值型数据)
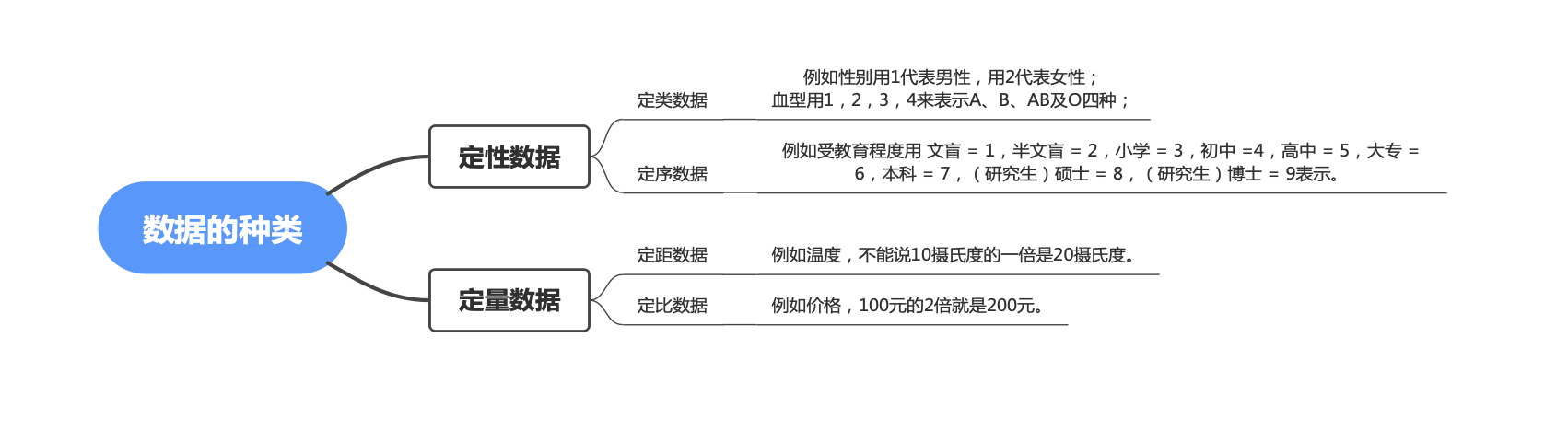
(1). 定性数据, 表示研究对象的类别。很好理解,这里的表示类别用的数字没有大小之分,不能进行算术四则运算。
定性数据可以分为:
① 定类数据
表现为类别,但不区分顺序,是由定类尺度计量形成的。一般可以从非数值型数据中编码转换而来,数值本身没有意义,只是为了区分类别做出的数值型标识
例如性别用1代表男性,用2代表女性;血型用1,2,3,4来表示A、B、AB及O四种;
② 定序数据
表现为类别,但有顺序,是由定序尺度计量形成的。运算符也没有意义,
例如受教育程度用 文盲 = 1,半文盲 = 2,小学 = 3,初中 =4,高中 = 5,大专 = 6,本科 = 7,(研究生)硕士 = 8,(研究生)博士 = 9表示。
(2). 定量数据, 表示的是研究对象的数量特征,如人群中人的身高、体重等。
定量数据可以分为以下几种:
① 定距数据
表现为数值,可进行加、减运算,是由定距尺度计量形成的。定距数据的特征是没有绝对的零点,例如温度,不能说10摄氏度的一倍是20摄氏度。因此乘、除法对于定距数据来说也是没有意义的。
② 定比数据
表现为数值,可进行加、减、乘、除运算,是由定比尺度计量形成的。定比数据存在绝对的零点。例如价格,100元的2倍就是200元。
2. 什么是统计学
先看一个例子,这里有一组数据 2,23,4,17,12,12,13,16,请思考你要怎么描述它?
你可能会说他们的平均数是12.375,中位数是12.5,最大值是23,最小值是2,等等。
没错,这里其实你已经在用平均数、中位数、最大值、最小值的来描述这组数据。
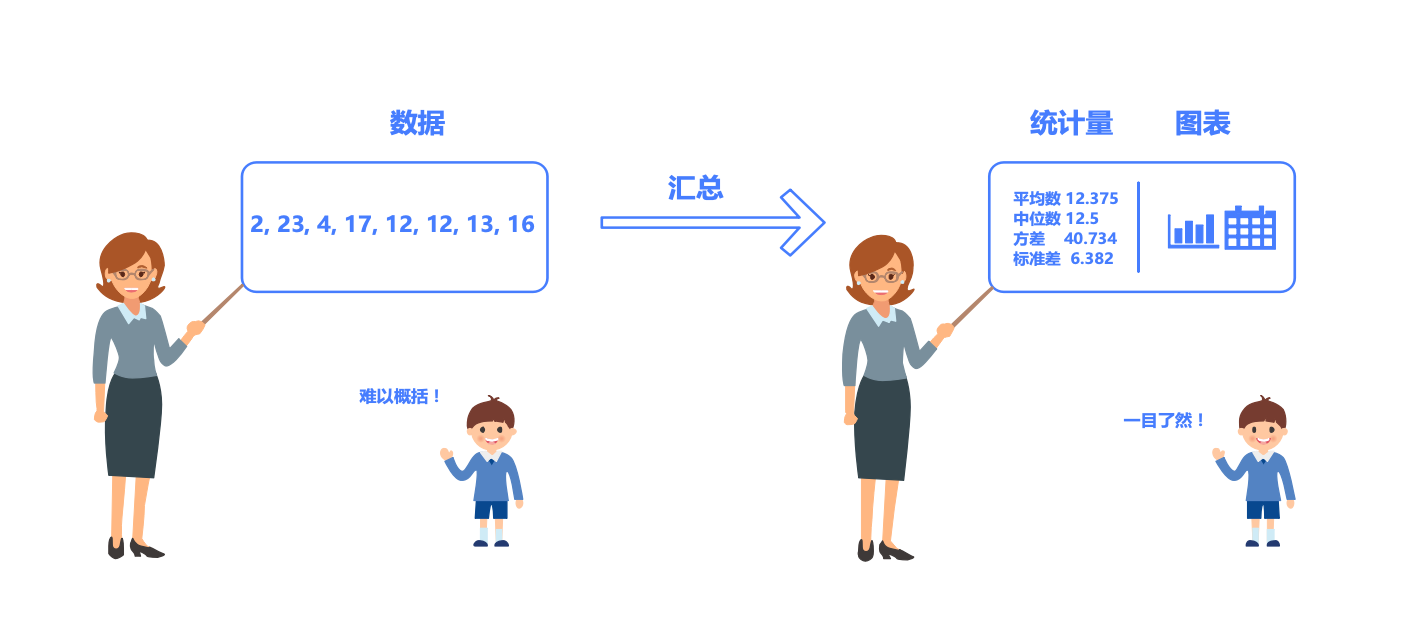
那么用几个数来描述一堆数就是统计学的基本概念:统计学是一门将 数据汇总为统计量或图表的学问。
Tips:通俗来说就是,数据太多记不住且不好描述,需要简化为更少的数字或图表,于是有了统计学和统计图表
知道了统计学的定义再接着看:
3. 统计学的知识体系是什么样的?
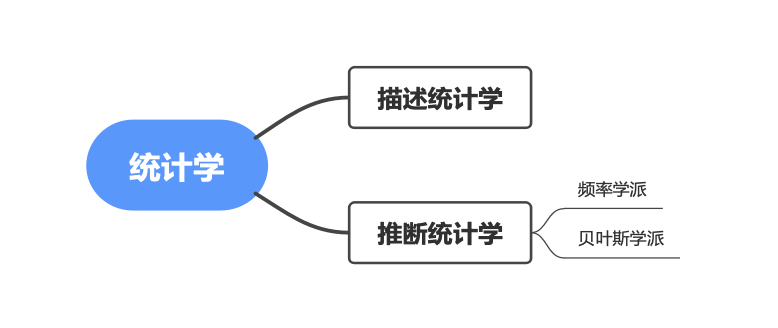
通常我们把统计学分为两大方向,通过计算出来的统计量来概括已有数据叫做描述统计学,通过样本获取总体特征的叫做推断统计学
Tips:“算”出来的统计量,比如 中位数、平均值、众数 这些;“猜”出来的叫推断统计学,比如通过样本数据来推断总体的数字特征。
下面这张图展示了统计学两大分支:描述统计与推断统计。其中推断统计又分两大学派,频率学派与贝叶斯学派。这些内容大家先知道就行,后面再展开。
下期预告:《Python统计学极简入门》第2节 描述性统计
这里分享一个你一定用得到的小程序——CDA数据分析师考试小程序。
它是专为CDA数据分析认证考试报考打造的一款小程序。可以帮你快速报名考试、查成绩、查证书、查积分,通过该小程序,考生可以享受更便捷的服务。
扫码加入CDA小程序,与圈内考生一同学习、交流、进步!












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330