数据挖掘案例—药物选择决策支持
【案例简要描述】
针对病人的病情和体质情况,医生往往需要采用不同的用药。本案例通过数据挖掘,对医院积累的历史数据进行分析,确定病人选择何种药物对治疗疾病最为有效。并开发了相应的药物选择决策支持系统的应用系统。
【背景介绍】
XX病是一种常见的疾病,目前有5种药物可以对其治疗,分别是——A、B、C、X、Y。不同的药物对病人有不同的疗效。历史上,医院往往根据医生的经验去判断针对特定的病人应该选择何种药物。但是由于新医生的加入,这种仅仅靠经验判断的做法造成了很多误诊。
该医院有比较完善的病例留存,为了改变以上局面,也为了更好的利用历史数据和专家经验,该医院决定通过数据挖掘技术对历史数据进行分析研究,并期望能够建立一套有效的药物选择决策支持系统。
【数据说明】
目前有历史病例数据1200条,咨询专家意见,我们提取了其中影响选择药物的若干个变量记入数据库,它们是年龄、性别、血压、胆固醇含量、钠含量、钾含量,最后一个变量是我们需要确定的选择药物,数据存贮在Microsoft Access数据库中。
【数据挖掘过程】
1、 商业理解
在这个阶段我们主要需要描述清楚业务问题,并对我们手头拥有的资源有一个非常清晰的认识。在这个案例中,我们需要根据病人的个人情况和身体特征来确定何种药物对它最为合适。由于问题比较简单,我们的商业理解也比较简单。
2、 数据理解
数据理解阶段用来完成对数据质量、数据之间的基本关系进行探索性分析等项工作。在这个阶段,我们对历史数据中的1200条数据进行图形观察,初步观察病人的情况和身体特征是否与选择药物关系明显。数据流图见图1。
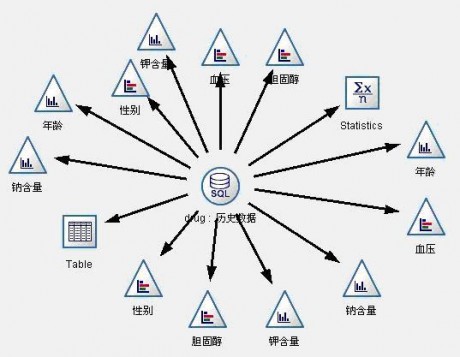
图1:数据理解
下面是产生的一些典型图形,图形解释略。

图2:对数据的初步探索性分析
3、 数据准备
数据准备主要完成对不同的数据源的整合,并且对数据进行适当的变换,使之适合数据挖掘的需要,对于特定的模型,需要把原始数据集合拆分成训练数据集和检验数据集也在这个步骤中完成。
对于本案例来说,由于数据源只有一个,并且数据格式也相对单一简单,我们在数据准备中主要完成对原始数据集的拆分,从而用训练数据集建立模型,用检验数据集对模型的效果进行评估。
在Clementine中,对数据集的拆分,是通过引入一个中间变量来完成的。在本案例中,我们把全部1200条数据中的2/3左右(800左右)作为训练数据集,把1/3左右(400左右)作为检验数据集。我们引入了一个二分变量——拆分变量,这个二分变量对应1200条原始数据有2/3左右为“真”(T),1/3左右为“假”(F)。我们挑出那些拆分变量值取“真”(T)的记录作为训练数据集,那些拆分变量值取“假”(F)的记录作为检验数据集。实现该过程的数据流见图3。
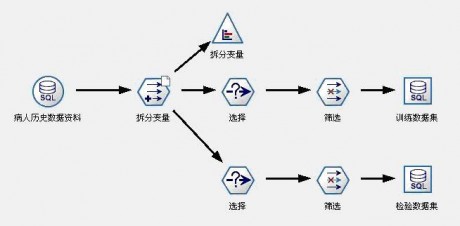
图3:数据准备
4、 模型建立和评估
在模型建立阶段,我们将逐步建立和调整模型,并对如何提高模型的预测效果进行尝试。
(1) 建立最简单的模型。对于训练数据集,我们首先把病人的年龄、性别、血压、胆固醇含量、钠含量、钾含量等不经过任何处理,全部作为预测选择药物的输入变量,而把选择药物作为待预测变量(输出变量)。数据流图见图4,我们建立了神经网络、C5.0和Logistic回归三个模型。
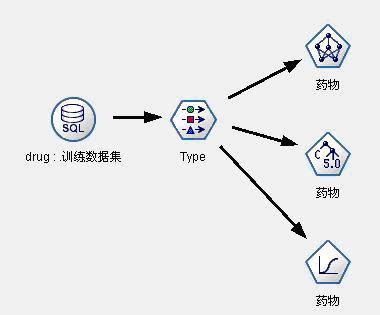
图4:药物选择决策支持模型1
接下来我们用检验数据集对模型进行检验,数据流图见图5。模型检验结果见图6。从检验结果我们可以看出,Logistic模型的评估效果最好,达到了96.21%。
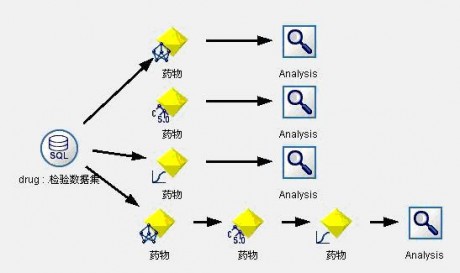
图5:药物选择决策支持模型1检验
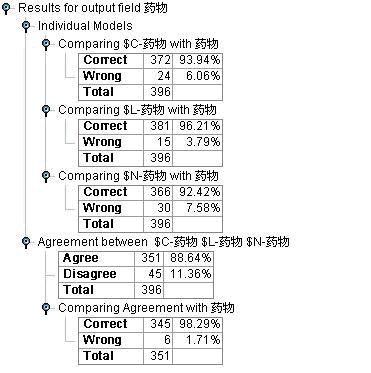
图6:药物选择决策支持模型1检验结果
讨论——如何提高模型的效果:从模型检验中我们可以看出,三个模型中可能有不一致的情况,这就使得我们有一种思路,即我们在发布模型的时候,可以考虑把那些三个模型预测一致的才作为预测,而把三者预测不一致的作为待判记录随后进行深入的分析,这样我们就使得模型的精度提高到了98.29%,但是作为牺牲,我们也会约有12%左右的病人是无法判断的,需要我们对记录做进一步的研究。
(2)为了更好的建立和调整模型,我们对业务进行深入了解,引入医生的业务经验。根据医生对医学理论的讨论和过去实践经验的积累,他们认为人体中的钠含量和钾含量对病人选择何种药物的作用并不是特别明显,但是他们的比例却是影响选择何种药物的一个关键因素,所以在我们下面建立的模型中,我们生成新变量——钠钾比例,而剔除钠含量和钾含量两个变量。数据流图见图7,模型我们仍旧采用神经网络,C5.0和Logistic回归三种模型。
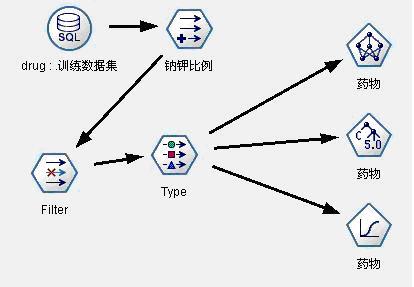
图7:药物选择决策支持模型2
类似(1),我们对模型效果进行检验,检验数据流和检验结果分别如图8和图9所示。
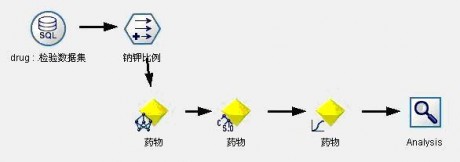
图8:药物选择决策支持模型2检验
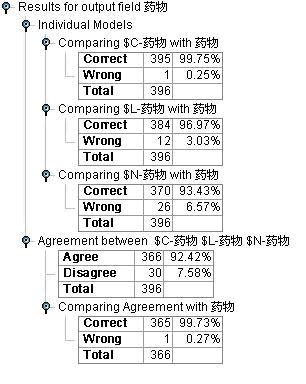
图9:药物选择决策支持模型2检验结果
从结果中,我们可以看出,随着我们业务经验的引入,我们的模型效果有了显著的提高,并且我们选择模型也发生了变化。精度由原来的Logistic回归最优96.21%提高到了C5.0最优99.75%。
5、 模型发布
模型建立是为了应用,我们前面的全部工作都在于我们建立的模型能够被最终的业务人员所使用,假设我们由以下10个病人的资料数据,需要根据他们的情况判断使用什么药物最好。
表1:病人资料
| 年龄 | 性别 | 血压 | 胆固醇 | 钠含量 | 钾含量 |
|
25 |
F | HIGH | HIGH |
0.675996 |
0.074834 |
|
17 |
F | HIGH | HIGH |
0.539756 |
0.030081 |
|
23 |
M | LOW | NORMAL |
0.556453 |
0.03618 |
|
24 |
M | NORMAL | NORMAL |
0.845236 |
0.055498 |
|
74 |
F | LOW | HIGH |
0.849624 |
0.076902 |
|
40 |
F | NORMAL | HIGH |
0.67683 |
0.049634 |
|
32 |
F | HIGH | HIGH |
0.581664 |
0.024803 |
|
70 |
M | LOW | HIGH |
0.716359 |
0.036936 |
|
64 |
M | HIGH | NORMAL |
0.640789 |
0.078302 |
|
45 |
M | HIGH | HIGH |
0.664105 |
0.047819 |
该病人资料也被我们存放在Access数据库中。我们可以考虑以下三种方式对我们的模型进行发布供业务人员(医生)使用。
(1) 直接写报告的方式,通过HTML展示。数据流图10,结果展示实际效果如图11。
图10:模型发布数据流1
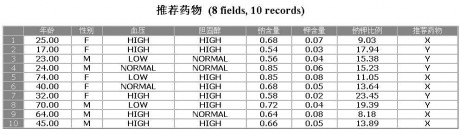
图11:报告方式发布结果示例
(2) 把选择药物直接写回数据库。数据流如图12,结果大致情形如图13。
图12:模型发布数据流2
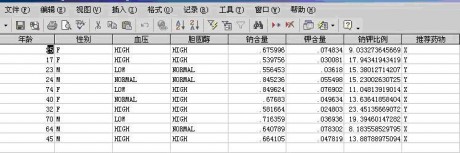
图13:模型发布—把结果写回数据库
(3) 通过Clementine Solution Publisher结合Visual C++开发应用系统界面,业务人员(医生)可以直接输入病人资料,实时的得到药物推荐。发布数据流见图14,系统界面如图15。
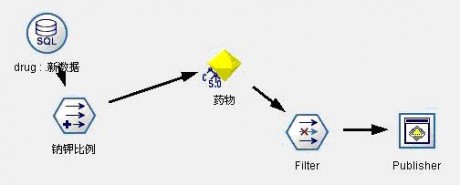
图14:模型发布数据流3
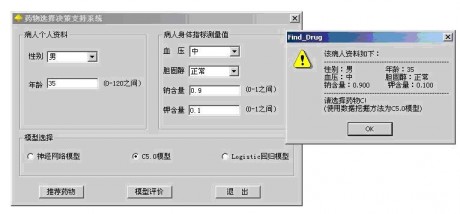
图15:模型发布——开发应用系统

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27TensorFlow Datasets(TFDS)是一个用于下载、管理和预处理机器学习数据集的库。它提供了易于使用的API,允许用户从现有集合中 ...
2025-03-26"不谋全局者,不足谋一域。"在数据驱动的商业时代,战略级数据分析能力已成为职场核心竞争力。《CDA二级教材:商业策略数据分析 ...
2025-03-26当你在某宝刷到【猜你喜欢】时,当抖音精准推来你的梦中情猫时,当美团外卖弹窗刚好是你想吃的火锅店…… 恭喜你,你正在被用户 ...
2025-03-26当面试官问起随机森林时,他到底在考察什么? ""请解释随机森林的原理""——这是数据分析岗位面试中的经典问题。但你可能不知道 ...
2025-03-25在数字化浪潮席卷的当下,数据俨然成为企业的命脉,贯穿于业务运作的各个环节。从线上到线下,从平台的交易数据,到门店的运营 ...
2025-03-25在互联网和移动应用领域,DAU(日活跃用户数)是一个耳熟能详的指标。无论是产品经理、运营,还是数据分析师,DAU都是衡量产品 ...
2025-03-24ABtest做的好,产品优化效果差不了!可见ABtest在评估优化策略的效果方面地位还是很高的,那么如何在业务中应用ABtest? 结合企业 ...
2025-03-21在企业数据分析中,指标体系是至关重要的工具。不仅帮助企业统一数据标准、提升数据质量,还能为业务决策提供有力支持。本文将围 ...
2025-03-20解锁数据分析师高薪密码,CDA 脱产就业班助你逆袭! 在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的 ...
2025-03-19在 MySQL 数据库中,查询一张表但是不包含某个字段可以通过以下两种方法实现:使用 SELECT 子句以明确指定想要的字段,或者使 ...
2025-03-17在当今数字化时代,数据成为企业发展的关键驱动力,而用户画像作为数据分析的重要成果,改变了企业理解用户、开展业务的方式。无 ...
2025-03-172025年是智能体(AI Agent)的元年,大模型和智能体的发展比较迅猛。感觉年初的deepseek刚火没多久,这几天Manus又成为媒体头条 ...
2025-03-14以下的文章内容来源于柯家媛老师的专栏,如果您想阅读专栏《小白必备的数据思维课》,点击下方链接 https://edu.cda.cn/goods/sh ...
2025-03-13






