本文实例讲述了朴素贝叶斯算法的python实现方法。分享给大家供大家参考。具体实现方法如下:
朴素贝叶斯算法优缺点
优点:在数据较少的情况下依然有效,可以处理多类别问题
缺点:对输入数据的准备方式敏感
适用数据类型:标称型数据
算法思想:
比如我们想判断一个邮件是不是垃圾邮件,那么我们知道的是这个邮件中的词的分布,那么我们还要知道:垃圾邮件中某些词的出现是多少,就可以利用贝叶斯定理得到。
函数
loadDataSet()
创建数据集,这里的数据集是已经拆分好的单词组成的句子,表示的是某论坛的用户评论,标签1表示这个是骂人的
createVocabList(dataSet)
找出这些句子中总共有多少单词,以确定我们词向量的大小
setOfWords2Vec(vocabList, inputSet)
将句子根据其中的单词转成向量,这里用的是伯努利模型,即只考虑这个单词是否存在
bagOfWords2VecMN(vocabList, inputSet)
这个是将句子转成向量的另一种模型,多项式模型,考虑某个词的出现次数
trainNB0(trainMatrix,trainCatergory)
计算P(i)和P(w[i]|C[1])和P(w[i]|C[0]),这里有两个技巧,一个是开始的分子分母没有全部初始化为0是为了防止其中一个的概率为0导致整体为0,另一个是后面乘用对数防止因为精度问题结果为0
classifyNB(vec2Classify, p0Vec, p1Vec, pClass1)
根据贝叶斯公式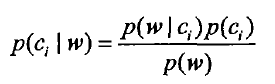 计算这个向量属于两个集合中哪个的概率高
计算这个向量属于两个集合中哪个的概率高
代码如下:
#coding=utf-8
from numpy import *
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec
#创建一个带有所有单词的列表
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document)
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
retVocabList = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
retVocabList[vocabList.index(word)] = 1
else:
print 'word ',word ,'not in dict'
return retVocabList
#另一种模型
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
def trainNB0(trainMatrix,trainCatergory):
numTrainDoc = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCatergory)/float(numTrainDoc)
#防止多个概率的成绩当中的一个为0
p0Num = ones(numWords)
p1Num = ones(numWords)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDoc):
if trainCatergory[i] == 1:
p1Num +=trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num +=trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom)#处于精度的考虑,否则很可能到限归零
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
def main():
testingNB()
if __name__ == '__main__':
main()
希望本文所述对大家的Python程序设计有所帮助。

数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27TensorFlow Datasets(TFDS)是一个用于下载、管理和预处理机器学习数据集的库。它提供了易于使用的API,允许用户从现有集合中 ...
2025-03-26"不谋全局者,不足谋一域。"在数据驱动的商业时代,战略级数据分析能力已成为职场核心竞争力。《CDA二级教材:商业策略数据分析 ...
2025-03-26当你在某宝刷到【猜你喜欢】时,当抖音精准推来你的梦中情猫时,当美团外卖弹窗刚好是你想吃的火锅店…… 恭喜你,你正在被用户 ...
2025-03-26






