前面在假设检验的部分经学过t检验、F检验、检验,之所以再看,是想通过纵向对比这几个检验统计量以加深理解:
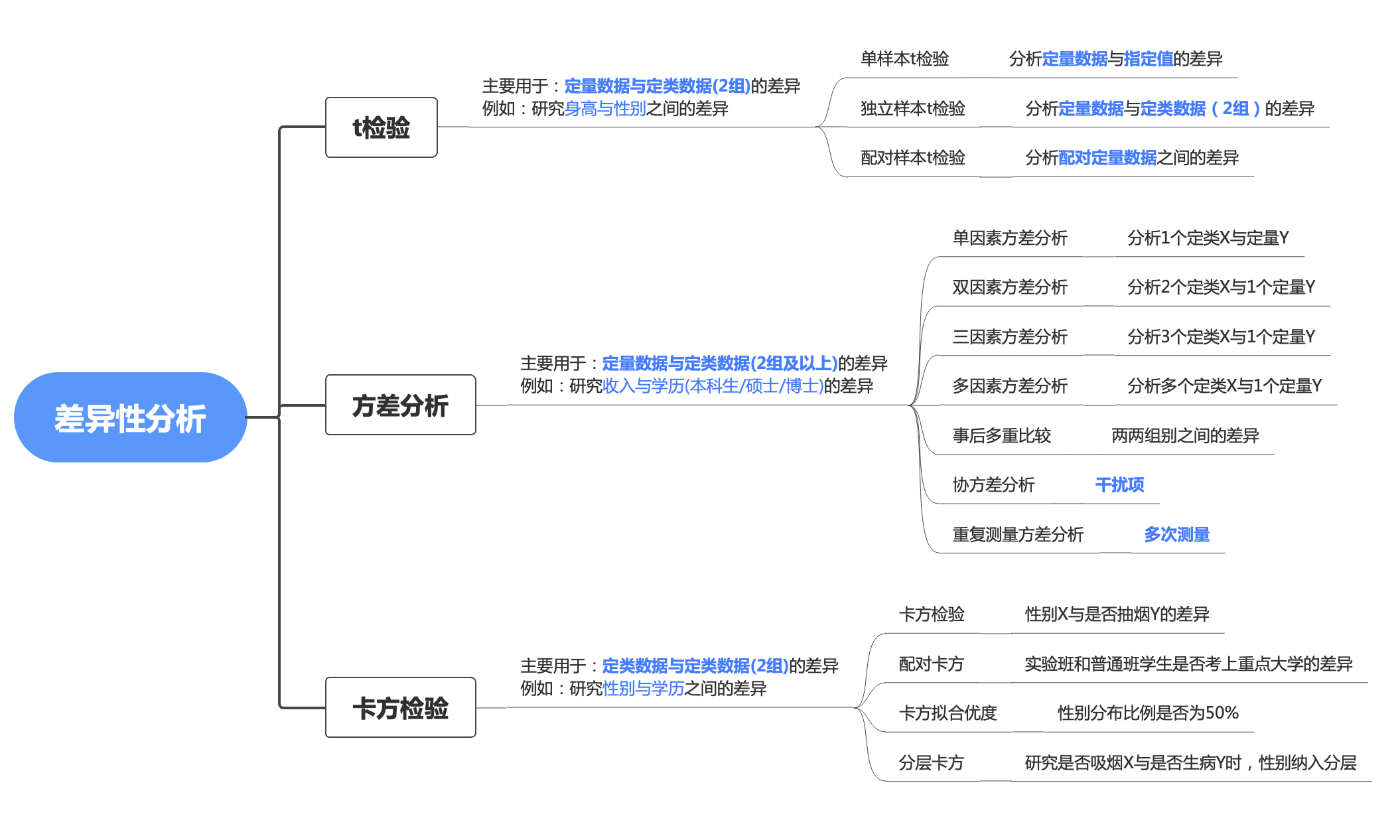
针对不同的场景,主要分为单样本T检验、独立样本T检验、配对样本T检验:
主要用于分析 一组定量数据 与 指定值的差异,例如检验食盐的实际称重是否不够标重的份量。
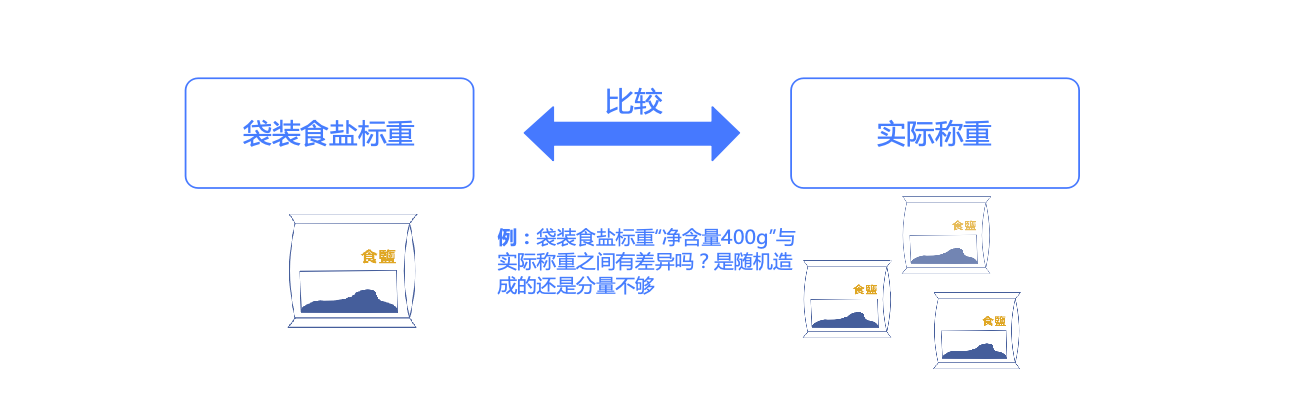
单样本T检验需要满足正态分布的假设,若不满足可采用单样本Wilcoxon检验。
例5.2 检验汽车实际排放是否低于其声称的排放标准
汽车厂商声称其发动机排放标准的一个指标平均低于20个单位。在抽查了10台发动机之后,得到下面的排放数据:
17.0 21.7 17.9 22.9 20.7 22.4 17.3 21.8 24.2 25.4
该样本均值为21.13.究竟能否由此认为该指标均值超过20?
分析过程: 由于厂家声称指标平均低于20个单位,因此原假设为总体均值等于20个单位(被怀疑对象总是放在零假设)。而且由于样本均值大于20(这是怀疑的根据),把备择假设设定为总体均值大于20个单位
于是我们有了原假设和备择假设
:
读取数据如下
data = [17.0, 21.7, 17.9, 22.9, 20.7, 22.4, 17.3, 21.8, 24.2, 25.4]
分步骤计算过程如下:
步骤一:计算样本均值 =(17+21.7+...+25.4)/10=21.13
用Python:
x_bar = np.array(data).mean()
x_bar
# 21.13
步骤二:计算样本标准差
用Python计算:
s = np.sqrt(((data-x_bar)**2).sum()/len(data))
s
# 2.7481084403640255
步骤三:计算统计量
,其中 为整体均值20,自由度n-1为9
t = (x_bar - 20)/(s/np.sqrt(len(data)-1))
t
# 1.2335757753252794
步骤四:查表或用软件查询p值与
p_value = scipy.stats.t.sf(t,len(data)-1 )
p_value
# 0.1243024777589817
结论: 选择显著性水平 0.01 的话,P=0.1243 > 0.05, 故无法拒绝原假设。具体来说就是该结果无法支持指标均值超过20的备则假设。说明发动机排放指标是不合格的。
对于以上过程,我们也可以用scipy.stats.ttest_1samp函数,一步到位进行t检验,直接返回的就是t统计量和p值:
import scipy.stats
t, pval = scipy.stats.ttest_1samp(a = data, popmean=20,alternative = 'greater')
# 说明
# 单一样本的t检验,检验单一样本是否与给定的均值popmean差异显著的函数,第一个参数为给定的样本,第二个函数为给定的均值popmean,可以以列表的形式传输多个单一样本和均值。
# a 为给定的样本数据
# popmean 为给定的总体均值
# alternative 定义备择假设。以下选项可用(默认为“two-sided”):
# ‘two-sided’:样本均值与给定的总体均值(popmean)不同
# ‘less’:样本均值小于给定总体均值(popmean)
# ‘greater’:样本均值大于给定总体均值(popmean)
print(t, pval)
# '''
# P= 0.004793 < 5%, 拒绝原假设,接受备择假设样本
# '''
结论: 选择显著性水平 0.01 的话,P=0.1243 > 0.05, 故无法拒绝原假设。具体来说就是该结果无法支持指标均值超过20的备则假设。
主要用于分析定量数据和**定类数据(2组)**的差异。原理是推论差异发生的概率,从而比较两个平均数的差异是否显著。通俗的说就是用样本均数和已知总体均数进行比较,来观察此组样本与总体的差异性。
例如有一个班的学生身高数据,如果学生的身高服从正态分布,想要研究身高和性别的关系,这个时候就相当于是两个独立样本。
独立样本的T检验也需要满足正态分布的假设,如果不满足可采用 Wilcoxon检验(也称MannWhitney检验); 如果满足但方差不等可采用 Welch T检验
计算公式如下:
、 代表两组数据的均值,
、 代表样本数,
、 代表两组数组的方差。
从计算公式能看出来,t越小则两组数据差异性越小。具体多小就根据置信度和自由度查表对比理论统计量的大小得出两组数据差异性是否显著。
例5.6(数据:drug.txt) 检验某药物在实验组的指标是否低于对照组
为检测某种药物对情绪的影响,对实验组的100名服药者和对照组的150名非服药者进行心理测试,得到相应的某指标。需要检验实验组指标的总体均值是否大于对照组的指标的总体均值。这里假定两个总体独立地服从正态分布。相应的假设检验问题为:
分析过程:由于目标是检验实验组指标的总体均值是否大于对照组的指标的总体均值,因此选择上侧检验
于是我们有了原假设和备择假设
:
data = pd.read_table("./t-data/drug.txt",sep = ' ')
data.sample(5)
| ah | id |
|---|---|
| 4.4 | 2 |
| 6.8 | 2 |
| 9.6 | 2 |
| 4.8 | 2 |
| 13.2 | 1 |
a = data[data['id']==1]['ah']
b = data[data['id']==2]['ah']
'''
H0: 实验组的均值等于对照组
H1: 实验组的均值大于对照组
'''
t, pval = scipy.stats.ttest_ind(a,b,alternative = 'greater')
# 独立样本的T检验,检验两个样本的均值差异,该检验方法假定了样本的通过了F检验,即两个独立样本的方差相同
# 另一个方法是:
# stats.ttest_ind_from_stats(mean1, std1, nobs1, mean2, std2, nobs2, equal_var=True)
# 检验两个样本的均值差异(同上),输出的参数两个样本的统计量,包括均值,标准差,和样本大小:直接输入样本的描述统计量(均值,标准差,样本数)即可
print(t,pval)
# 0.9109168350628888 0.18161186154576608
结论: 选择显著性水平 0.05 的话,p = 0.1816 > 0.05,无法拒绝H0,具体来说就是该结果无法支持实验组均值大于对照组的备则假设。
主要用于分析配对定量数据的差异。
常见的使用场景有:
①同一对象处理前后的对比(同一组人员采用同一种减肥方法前后的效果对比);
②同一对象采用两种方法检验的结果的对比(同一组人员分别服用两种减肥药后的效果对比);
③配对的两个对象分别接受两种处理后的结果对比(两组人员,按照体重进行配对,服用不同的减肥药,对比服药后的两组人员的体重)。
例如,假设一个班上男女生的成绩不存在差异,显著性水平为0.05,可理解为只有5%的概率会出现“男女生成绩差异显著”的情况,若计算出的检验p值若小于0.05,则可以拒绝原假设。反之不能拒绝原假设。
此外,t检验注意事项
①无论哪种t检验、都要数据服从正态或者近似正态分布。正态性的检验方法有:正态图、正态性检验、P-P图/Q-Q图等。
②两个独立样本的t检验,通常需要先进行F检验(方差齐次检验),检验两个独立样本的方差是否相同,若两总体方差相等,则直接用t检验,若不等,可采用t’检验或变量变换或秩和检验等方法。
例5.7(数据: diet.txt) 检验减肥前后的重量是否有显著性差异(是否有减肥效果)
这里有两列50对减肥数据。其中一列数据(变量名before)是减肥前的重量,另一列(变量名after)是减肥后的重量(单位: 公斤),人们希望比较50个人在减肥前和减肥后的重量。
分析过程:这里不能用前面的独立样本均值差的检验,这是因为两个样本并不独立。每一个人减肥后的重量都和自己减肥前的重量有关,但不同人之间却是独立的,所以应该用配对样本检验。同时,由于研究的是减肥前后的重量变化,期望减肥前的重量大于减肥后的重量,所以备择假设是期望减肥前的重量大于减肥后的重量
于是我们有了原假设和备择假设:
:
步骤一、计算两组样本数据差值d,即58-50,76-71,69-65,68-76,81-75
d = data['before'] - data['after']
步骤二、计算差值d的平均值 ,即(-1+0+1+0)/4=0
d_bar = ( d).sum()/len(data)
步骤三、计算差值d的标准差 ,计算公式为
s_d = np.sqrt(((d -d_bar)**2).sum()/(len(data)-1))
s_d
步骤四、计算统计量t,计算公式为
t = (d_bar)/(s_d/np.sqrt(len(data))) # 这里mu是0
t
#
计算p值
p_value = scipy.stats.t.sf(t, len(data)-1)
p_value
# 0.0007694243254842176
其中 为理论总体差值均值0,n为样本数。
结论 选择显著性水平 0.05 的话,p = 0.0007 < 0.05,故应该拒绝原假设。具体来说就是该结果倾向支持减肥前后的重量之差大于零(即减肥前重量大于减肥后,也就是有减肥效果)的备则假设。
同样的,我们用现成的函数 stats.ttest_rel,一步到位进行t检验,直接返回的就是t统计量和p值:
data = pd.read_table("./t-data/diet.txt",sep = ' ')
data.sample(5)
| before | after |
|---|---|
| 58 | 50 |
| 76 | 71 |
| 69 | 65 |
| 68 | 76 |
| 81 | 75 |
a = data['before']
b = data['after']
stats.ttest_rel(a, b,alternative = 'greater')
# #配对T检验,检测两个样本的均值差异,输入的参数是样本的向量
# Ttest_relResult(statistic=3.3550474801424173, pvalue=0.000769424325484219)
结论 选择显著性水平 0.05 的话,p = 0.0007 < 0.05,故应该拒绝原假设。具体来说就是该结果倾向支持减肥前后的重量之差大于零(即减肥前重量大于减肥后,也就是有减肥效果)的备则假设。
F检验(F-test),最常用的别名叫做联合假设检验(英语:joint hypotheses test),此外也称方差比率检验、方差齐性检验。
用于: 判断两组数据方差是否存在显著差异。
步骤一:分别计算两组样本数据的均值
步骤二:分别计算两组样本数据的标准方差的平方
,把平方大的作为分子,小的作为分母。
得到F值后根据两组数据的自由度和置信度查表对比,同样的,F值也是越小越说明差异性不显著。
stats模块中虽然没有f检验的函数,但是却有着f分布的生成函数,可以利用其进行f检验:
import numpy as np
from scipy.stats import f_oneway
# 创建两个样本
sample1 = np.array([1, 2, 3, 4, 5])
sample2 = np.array([2, 4, 6, 8, 10])
# 使用 f_oneway 函数进行 F 检验
f_statistic, p_value = f_oneway(sample1, sample2)
# 打印检验结果
print("F statistic:", f_statistic)
print("p-value:", p_value)
#在上述示例中,我们创建了两个样本 sample1 和 sample2,每个样本包含五个观测值。然后,我们使用 f_oneway 函数对这两个样本进行 F 检验。
#f_oneway 函数返回两个值,第一个是 F 统计量,第二个是对应的 p 值。我们可以根据 p 值来判断样本方差是否有显著差异。如果 p 值小于设定的显著性水平(通常为 0.05),则可以拒绝原假设,认为样本方差存在显著差异。
#在上述示例中,我们可以得到 F 统计量为 4.0,p 值为 0.078。由于 p 值大于 0.05,我们不能拒绝原假设,即无法认为这两个样本的方差存在显著差异。
#需要注意的是,在使用 f_oneway 函数进行 F 检验时,输入的样本应该是一维数组或列表形式。如果有多个样本,可以将它们作为函数的参数传入。
也可以引入sklearn进行f检验
# 例子1
from sklearn.datasets import make_classification
from sklearn.feature_selection import f_classif
# 生成样本数据集
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=42)
# F检验
F, pval = f_classif(X, y)
# 输出结果
print(F)
print(pval)
# 特征排序(如果不做机器学习可以忽略这一步)
indices = np.argsort(F)[-10:]
print(indices)
#这里我们生成了一个包含10个特征的样本分类数据集,其中5个特征包含区分两类信息,5个特征冗余。
#使用f_classif函数可以计算每个特征的F-score和p值,F-score越高表示该特征越重要。
#最后通过argsort排序,输出最重要的特征索引。
#F检验通过计算每个特征对目标类别的区分能力,来对特征重要性进行评估和排序,是一种常用的过滤式特征选择方法。
# 例子2
import numpy as np
from sklearn.feature_selection import f_regression
# 创建特征矩阵 X 和目标向量 y
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
y = np.array([1, 2, 3])
# 使用 f_regression 函数进行 F 检验
f_values, p_values = f_regression(X, y)
# 打印 F 统计量和 p 值
print("F values:", f_values)
print("p-values:", p_values)
例5.10(两总体方差之比的假设检验) 检验修完Python课程的学生是否比修完数据库课程的学生考CDA的成绩方差更大
某高校数据科学专业的学生,修完一门数据库课程的41名学生考CDA的方差,修完Python课程的31名学生考CDA的方差是,这些数据是否表明,修完数据库的学生要比修完Python的学生CDA成绩的方差更大?
分析过程:由于目标是希望修完Python的学生CDA成绩的方差更大,因此选择上侧检验。两总体方差之比用F检验,将方差较大的数据库课程的考试成绩视为总体1
于是我们有了原假设和备择假设
:
import numpy as np
from scipy import stats
def f_test_by_s_square(n1, n2, s1_square,s2_square, side ='two-sided'):
"""
参数
n1 :样本1的数量
n2 :样本2的数量
s1_square:样本1的方差
s2_square:样本2的方差
#
# F_value :F统计量的值
# p_value :对应的p值
"""
F_value = s1_square/s2_square
F = stats.f(dfn = n1-1, dfd = n2-1)
if side=='two-sided':
print("two-sided")
p_value = 2*min(F.cdf(F_value), 1-F.cdf(F_value))
return F_value,p_value
elif side=='greater':
print("greater")
p_value = 1-F.cdf(F_value)
return F_value,p_value
f_statistic , p_value= f_test_by_s_square(n1=41, n2=31,s1_square=120,s2_square=80,side='greater')# 打印检验结果
# 选择上侧检验所以side='greater'
print("F statistic:", f_statistic)
print("p-value:", p_value)
结论 选择显著性水平 0.05 的话,p = 0.1256 > 0.05,故无法原假设。结果无法支持修完数据库的学生要比修完Python的学生CDA成绩的方差更大的备则假设。
卡方检验(chi-square test),也就是χ2检验,是以 分布为基础的一种用途广泛的分析定性数据差异性的方法,通过频数进行检验。
之前假设检验一节中,我们知道卡方检验可以做指定方差和样本方差是否有差异
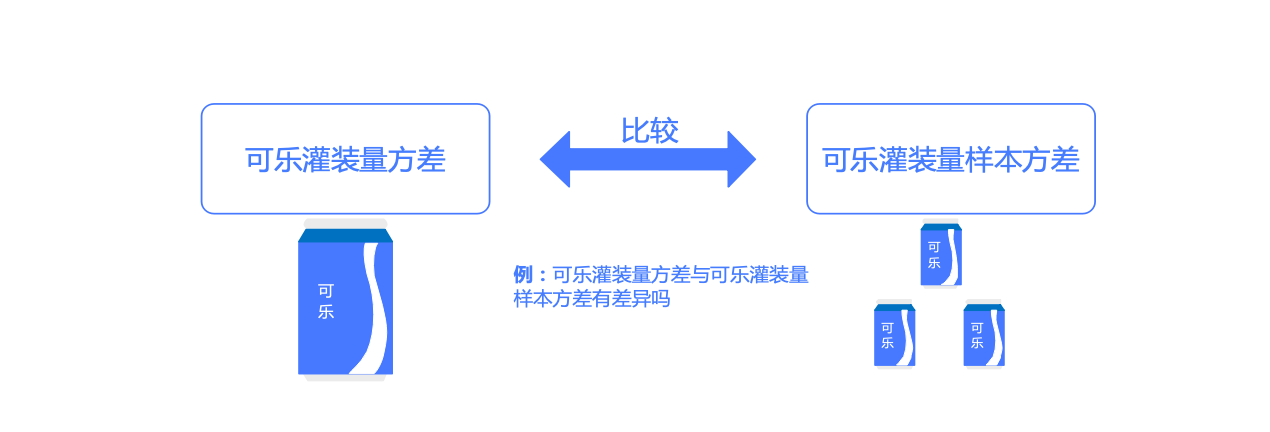
例5.5 检验某考试中心升级题库后考生分数的方差是否有显著变化
某数据分析师认证考试机构CDA考试中心,历史上的持证人考试分数的方差为 ,现在升级了题库,该考试中心希望新型考题的方差保持在原有水平上,为了研究该问题,收集到了30份新考题的考分组成的样本,样本方差是,在 的显著性水平下进行假设检验。
分析过程:由于目标是希望考试分数的方差保持原有水平,因此选择双侧检验
于是我们有了原假设和备择假设
:
import numpy as np
from scipy import stats
def chi2test(sample_var, sample_num,sigma_square,side, alpha=0.05):
'''
参数:
sample_var--样本方差
sample_num--样本容量
sigma_square--H0方差
返回值:
pval
'''
chi_square =((sample_num-1)*sample_var)/(sigma_square)
p_value = None
if side == 'two-sided':
p = stats.chi2(df=sample_num-1).cdf(chi_square)
p_value = 2*np.min([p, 1-p])
elif side == 'less':
p_value = stats.chi2(df=sample_num-1).cdf(chi_square)
elif side == 'greater':
p_value = stats.chi2(df=sample_num-1).sf(chi_square)
return chi_square,p_value
p_value = chi2test(sample_var = 162, sample_num = 30, sigma_square = 100,side='two-sided')
print("p值:", p_value)
# p值: 0.07213100536907469
结论: 选择显著性水平 0.05 的话,P=0.0721 > 0.05, 故无法拒绝原假设。具体来说就是不支持方差发生了变化的备则假设。换句话说新题型的方差依然保持在原有水平上
那么,卡方检验还有什么应用呢?
统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。
卡方值计算公式:
①卡方优度检验 对一列数据进行统计检验,分析单个分类变量实际观测的比例与期望的比例是否一致。
②配对卡方 研究实验过程中,用不同方法检测同一批人,看两个方法的效果是否有显著差异。
③ 交叉表卡方
研究两组分类变量的关系:如性别与看不看直播是否有关系。
例7.5(交叉表卡方):性别与对待吸烟的态度之间的相关性 一项研究调查了不同性别的成年人对在公众场合吸烟的态度,结果如表所示。那么,性别与对待吸烟的态度之间的相关程度
| - | 赞同 | 反对 |
|---|---|---|
| 男 | 15 | 10 |
| 女 | 10 | 26 |
python中stats模块,同样有卡方检验的计算函数
from scipy.stats import chi2_contingency
import numpy as np
data = np.array([[15,10], [10,26]])
chi2, p, dof, expected = chi2_contingency(data,correction =False)
print(f'卡方值={chi2}, p值={p}, 自由度={dof}')
# 卡方值=6.3334567901234555, p值=0.011848116168529757, 自由度=1
结论:p = 0.0118<0.05,拒绝原假设,表明两变量之间的正向关系很显著。
sklearn中的特征选择中也可以进行卡方检验。
from sklearn.feature_selection import chi2
import numpy as np
# 假设我们有一个包含100个样本和5个特征的数据集
X = np.random.randint(0, 10, (40, 5))
y = np.random.randint(0, 2, 40)
# 使用chi2函数计算特征变量与目标变量之间的卡方统计量和p值
chi2_stats, p_values = chi2(X, y)
# 打印每个特征的卡方统计量和p值
for i in range(len(chi2_stats)):
print(f"Feature {i+1}: chi2_stat = {chi2_stats[i]}, p_value = {p_values[i]}")
#在上面的例子中,我们生成了一个包含100个样本和5个特征的随机数据集。然后,我们使用chi2函数计算每个特征与目标变量之间的卡方统计量和p值。最后,我们打印出每个特征的卡方统计量和p值。
#根据卡方统计量和p值,我们可以判断每个特征与目标变量之间的关联程度。如果卡方统计量较大且p值较小,则说明特征与目标变量之间存在显著关联,可以考虑选择该特征作为重要的特征进行建模。
至此,统计学的描述性统计、推断统计基本告一段落,剩下的贝叶斯、线性回归、逻辑回归请读者自行查阅资料进行学习,我们下个系列见!
(PS:可以在评价中写下你想学的系列,包括不限于SQL、Pandas、Julia、机器学习、数学建模、数据治理)
《统计学极简入门》图文系列教程的写作过程中参考了诸多经典书籍,包括:
人大统计学教授吴喜之老师的 《统计学:从数据到结论》;
辛辛那提大学 David R. Anderson的 《商务经济与统计》;
北海道大学的马场真哉的 《用Python动手学统计学》 ;
千叶大学研究院教授栗原伸一的《统计学图鉴》;
前阿里巴巴产品专家徐小磊的知乎:磊叔-数据化运营;
知乎旧梦的文章T检验、F检验、卡方检验详细分析及应用场景总结;
csdn文章T检验、卡方检验、F检验;
以及CDA认证考试中心 提供的部分案例数据集
在此一并感谢以上内容的作者!
一死生为虚诞,齐彭殇为妄作。各位加油!
这里分享一个你一定用得到的小程序——CDA数据分析师考试小程序。
它是专为CDA数据分析认证考试报考打造的一款小程序。可以帮你快速报名考试、查成绩、查证书、查积分,通过该小程序,考生可以享受更便捷的服务。
扫码加入CDA小程序,与圈内考生一同学习、交流、进步!


数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
持证人简介: CDA持证人刘凌峰,CDA L1持证人,微软认证讲师(MCT)金山办公最有价值专家(KVP),工信部高级项目管理师,拥有 ...
2025-04-15持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。在实际生活中,我们可能会 ...
2025-04-14在 Python 编程学习与实践中,Anaconda 是一款极为重要的工具。它作为一个开源的 Python 发行版本,集成了众多常用的科学计算库 ...
2025-04-14随着大数据时代的深入发展,数据运营成为企业不可或缺的岗位之一。这个职位的核心是通过收集、整理和分析数据,帮助企业做出科 ...
2025-04-11持证人简介:CDA持证人黄葛英,ICF国际教练联盟认证教练,前字节跳动销售主管,拥有丰富的行业经验。 本次分享我将以教培行业为 ...
2025-04-11近日《2025中国城市长租市场发展蓝皮书》(下称《蓝皮书》)正式发布。《蓝皮书》指出,当前我国城市住房正经历从“增量扩张”向 ...
2025-04-10在数字化时代的浪潮中,数据已经成为企业决策和运营的核心。每一位客户,每一次交易,都承载着丰富的信息和价值。 如何在海量客 ...
2025-04-09数据是数字化的基础。随着工业4.0的推进,企业生产运作过程中的在线数据变得更加丰富;而互联网、新零售等C端应用的丰富多彩,产 ...
2025-04-094月7日,美国关税政策对全球金融市场的冲击仍在肆虐,周一亚市早盘,美股股指、原油期货、加密货币、贵金属等资产齐齐重挫,市场 ...
2025-04-08背景 3月26日,科技圈迎来一则重磅消息,苹果公司宣布向浙江大学捐赠 3000 万元人民币,用于支持编程教育。 这一举措并非偶然, ...
2025-04-07在当今数据驱动的时代,数据分析能力备受青睐,数据分析能力频繁出现在岗位需求的描述中,不分岗位的任职要求中,会特意标出“熟 ...
2025-04-03在当今数字化时代,数据分析师的重要性与日俱增。但许多人在踏上这条职业道路时,往往充满疑惑: 如何成为一名数据分析师?成为 ...
2025-04-02最近我发现一个绝招,用DeepSeek AI处理Excel数据简直太爽了!处理速度嘎嘎快! 平常一整天的表格处理工作,现在只要三步就能搞 ...
2025-04-01你是否被统计学复杂的理论和晦涩的公式劝退过?别担心,“山有木兮:统计学极简入门(Python)” 将为你一一化解这些难题。课程 ...
2025-03-31在电商、零售、甚至内容付费业务中,你真的了解你的客户吗? 有些客户下了一两次单就消失了,有些人每个月都回购,有些人曾经是 ...
2025-03-31在数字化浪潮中,数据驱动决策已成为企业发展的核心竞争力,数据分析人才的需求持续飙升。世界经济论坛发布的《未来就业报告》, ...
2025-03-28你有没有遇到过这样的情况?流量进来了,转化率却不高,辛辛苦苦拉来的用户,最后大部分都悄无声息地离开了,这时候漏斗分析就非 ...
2025-03-27TensorFlow Datasets(TFDS)是一个用于下载、管理和预处理机器学习数据集的库。它提供了易于使用的API,允许用户从现有集合中 ...
2025-03-26"不谋全局者,不足谋一域。"在数据驱动的商业时代,战略级数据分析能力已成为职场核心竞争力。《CDA二级教材:商业策略数据分析 ...
2025-03-26当你在某宝刷到【猜你喜欢】时,当抖音精准推来你的梦中情猫时,当美团外卖弹窗刚好是你想吃的火锅店…… 恭喜你,你正在被用户 ...
2025-03-26






