3. 数据分布
t分布、F分布和卡方分布是统计学中常用的三种概率分布,它们分别用于样本均值的推断、方差的比较和数据的拟合优度检验。
总之这3个分布很有用,首次接触你可能理解不了,但没关系你知道很重要就行了,接着往下看,我们在介绍三大分布之前,先看一下正态分布和标准正态分布:
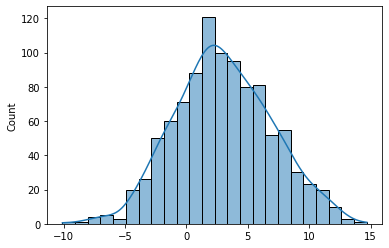
正态分布(Normal Distribution)
正态分布也被称为高斯分布,是统计学中最常见的概率分布之一。
正态分布具有钟形曲线的特征,均值和标准差是其两个重要的参数。
import numpy as np
import seaborn as sns
mean = 3
std = 4
size = 1000
data = np.random.normal(mean, std, size=size)
sns.histplot(data, kde=True)
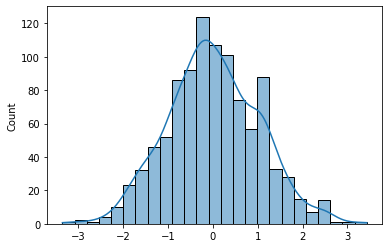
标准正态分布(Standard Normal Distribution)
标准正态分布是一种特殊的正态分布,其均值为0,标准差为1。在统计学中,标准正态分布经常用于标准化数据或进行假设检验。
import numpy as np
import seaborn as sns
size = 1000
data = np.random.standard_normal(size=size)
sns.histplot(data, kde=True)
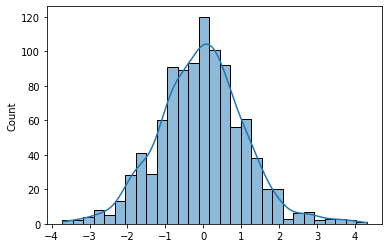
t分布(t Distribution)
t分布是一种概率分布,用于小样本情况下对总体均值的推断。当样本容量较小或总体方差未知时,使用T分布进行推断更准确。T分布的形状类似于正态分布,但尾部较宽。T分布的自由度(degrees of freedom)决定了其形状。
import numpy as np
import seaborn as sns
df = 10
size = 1000
data = np.random.standard_t(df, size=size)
sns.histplot(data, kde=True)
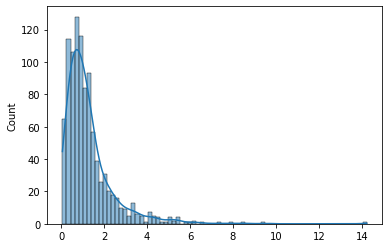
F分布(F Distribution)
F分布是一种概率分布,用于比较两个样本方差的差异。F分布常用于方差分析和回归分析中。F分布的形状取决于两个自由度参数,分子自由度和分母自由度。
import numpy as np
import seaborn as sns
dfn = 5
dfd = 10
size = 1000
data = np.random.f(dfn, dfd, size=size)
sns.histplot(data, kde=True)
卡方分布(Chi-Square Distribution)
卡方分布是一种概率分布,用于检验观察值与理论值之间的拟合优度。卡方分布常用于拟合优度检验、独立性检验中。卡方分布的自由度参数决定了其形状。
import numpy as np
import seaborn as sns
df = 5
size = 1000
data = np.random.chisquare(df, size)
sns.histplot(data, kde=True)
番外篇:三大分布互相推导
注:本节作为延伸阅读,初学者简单了解即可
十九世纪中叶至二十世纪初,有三位统计学届杰出代表: 皮尔逊( Pearson) 、戈塞特( Gosset) 、费希尔( Fisher) 表,他们是统计学三大分布的始创者。
皮尔逊(Pearson) 在创立拟合优度理论的过程中发现了 分布;
戈塞特( Gosset) 发现 分布的过程正是 小样本理论 创立的过程;
费希尔( Fisher) 在创立 方差分析 理论的过程中发现了 分布。
这便是著名的三大抽样分布包括: 分布、 分布和 分布
分布是由个相互独立的标准正态分布 的平方和确定的分布,记作
~ ,即
分布的分子是一个 ,分母是自由度为 的 分布与自由度 的比值再开方确定的分布,记作 ~ ,即
分布是由两个 分布与其自由度比值的比值确定的分布 ,记 作 ~ ,即
三大分布的推导

三大分布的推导例题


下期预告:《Python统计学极简入门》第4节 区间估计
这里分享一个你一定用得到的小程序——CDA数据分析师考试小程序。
它是专为CDA数据分析认证考试报考打造的一款小程序。可以帮你快速报名考试、查成绩、查证书、查积分,通过该小程序,考生可以享受更便捷的服务。
扫码加入CDA小程序,与圈内考生一同学习、交流、进步!

CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330