R语言获取优化的k均值聚类
k均值算法效率快也易于实现,但在算法开始要求提前规定好簇K的数目,因此我们可以使用距离的平方和确定那个K值能够得到最好的k均值聚类效果。
操作
执行以下操作为K均值算法找到最合适的聚类个数
nk = 2:10
set.seed(22)
WSS = sapply(nk, function(nk){
kmeans(customer,centers = nk)$tot.withinss
})
WSS
[1] 123.49224 88.07028 61.34890 48.76431 47.20813 45.48114 29.58014 28.87519 23.21331
调用plot绘制不同的k值下距离平方和的线图:
plot(nk,WSS,type = "l",xlab = "number of k",ylab = "within sum of squares")
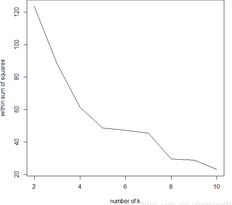
不同k值下距离平方和线图
计算不同聚类结果的平均轮廓值(avg.silwidth)
SW =sapply(nk, function(k){
cluster.stats(dist(customer),kmeans(customer,centers = k)$cluster)$avg.silwidth
})
SW
[1] 0.4203896 0.4092890 0.4640587 0.4308448 0.4160309 0.4241364 0.3637102 0.3540200 0.3436709
不同k值的平均轮廓线
plot(nk,SW,type = "l",xlab = "number of clusers",ylab = "average silhouette width")
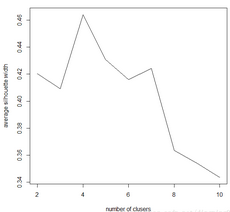
得到最大的簇个数:
nk[which.max(SW)]
原理
通过迭代生成簇的距离平方和以及平均轮廓值来寻找最优的簇数值,其中,距离平方和越小,聚簇的效果越佳,通过不同的K值下距离平方和图,可以得到最适合样例的k值为4。我们还使用cluster.stats函数来计算不同的聚类结果的平均轮廓值图,并绘制了相应的线图,从结果可以知道当k=4时,平均轮廓值最大。还可以用which.max函数得到最大平均轮廓值对应的k值。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330