概括地说,泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据对背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
在机器学习方法中,泛化能力通俗来讲就是指学习到的模型对未知数据的预测能力。在实际情况中,我们通常通过测试误差来评价学习方法的泛化能力。如果在不考虑数据量不足的情况下出现模型的泛化能力差,那么其原因基本为对损失函数的优化没有达到全局最优。
1.泛化能力
在机器学习方法中,泛化能力通俗来讲就是指学习到的模型对未知数据的预测能力。在实际情况中,我们通常通过测试误差来评价学习方法的泛化能力。如果在不考虑数据量不足的情况下出现模型的泛化能力差,那么其原因基本为对损失函数的优化没有达到全局最优。
2.泛化误差
首先给出泛化误差的定义, 如果学到的模型是 f^ , 那么用这个模型对未知数据预测的误差即为泛化误差
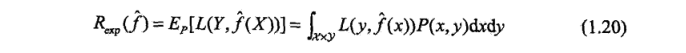
泛化误差反映了学习方法的泛化能力,如果一种方法学习的模型比另一种方法学习的模型具有更小的泛化误差,那么这种方法就更有效, 事实上,泛化误差就是所学到的模型的期望误差。
3.提高泛化能力
提高泛化能力的方式大致有三种:1.增加数据量。2.正则化。3.凸优化。
4.L1正则化,L2正则化
L1正则化的几何解释如图:

L1正则化给出的最优解w∗是使解更加靠近某些轴,而其它的轴则为0.所以L1正则化能使得到的参数稀疏化。
L1正则化的参数先验是服从拉布拉斯分布的,拉布拉斯的概率密度分布函数为:

L2正则化的解释如图:

L2 正则化给出的最优解w∗是使解更加靠近原点,也就是说L2正则化能降低参数范数的总和。
L2正则化的参数先验服从高斯分布,高斯分布的概率密度分布函数为:


数据分析咨询请扫描二维码
若不方便扫码,搜微信号:CDAshujufenxi
在数据科学的广阔领域中,统计分析与数据挖掘占据了重要位置。尽管它们常常被视为有关联的领域,但两者在理论基础、目标、方法及 ...
2025-02-05在数据分析的世界里,“对比”是一种简单且有效的方法。这就像两个女孩子穿同一款式的衣服,效果不一样。 很多人都听过“货比三 ...
2025-02-05当我们只有非常少量的已标记数据,同时有大量未标记数据点时,可以使用半监督学习算法来处理。在sklearn中,基于图算法的半监督 ...
2025-02-05考虑一种棘手的情况:训练数据中大部分样本没有标签。此时,我们可以考虑使用半监督学习方法来处理。半监督学习能够利用这些额 ...
2025-02-04一、数学函数 1、取整 =INT(数字) 2、求余数 =MOD(除数,被除数) 3、四舍五入 =ROUND(数字,保留小数位数) 4、取绝对值 =AB ...
2025-02-03作者:CDA持证人 余治国 一般各平台出薪资报告,都会哀嚎遍野。举个例子,去年某招聘平台发布《中国女性职场现状调查报告》, ...
2025-02-02真正的数据分析大神是什么样的呢?有人认为他们能轻松驾驭各种分析工具,能够从海量数据中找到潜在关联,或者一眼识别报告中的数 ...
2025-02-01现今社会,“转行”似乎成无数职场人无法回避的话题。但行业就像座围城:外行人看光鲜,内行人看心酸。数据分析这个行业,近几年 ...
2025-01-31本人基本情况: 学校及专业:厦门大学经济学院应用统计 实习经历:快手数据分析、字节数据分析、百度数据分析 Offer情况:北京 ...
2025-01-3001专家简介 徐杨老师,CDA数据科学研究院教研副总监,主要负责CDA认证项目以及机器学习/人工智能类课程的研发与授课,负责过中 ...
2025-01-29持证人简介 郭畅,CDA数据分析师二级持证人,安徽大学毕业,目前就职于徽商银行总行大数据部,两年工作经验,主要参与两项跨部 ...
2025-01-282025年刚开启,知乎上就出现了一个热帖: 2024年突然出现的经济下行,使各行各业都感觉到压力山大。有人说,大环境越来越不好了 ...
2025-01-27在数据分析的世界里,“对比”是一种简单且有效的方法。这就像两个女孩子穿同一款式的衣服,效果不一样。 很多人都听过“货比三 ...
2025-01-26数据指标体系 “数据为王”相信大家都听说过。当前,数据信息不再仅仅是传递的媒介,它成为了驱动经济发展的新燃料。对于企业而 ...
2025-01-26在职场中,当你遇到问题的时候,如果感到无从下手,或者抓不到重点,可能是因为你掌握的思维模型不够多。 一个好用的思维模型, ...
2025-01-25俗话说的好“文不如表,表不如图”,图的信息传达效率很高,是数据汇报、数据展示的重要手段。好的数据展示不仅需要有图,还要选 ...
2025-01-24数据分析报告至关重要 一份高质量的数据分析报告不仅能够揭示数据背后的真相,还能为企业决策者提供有价值的洞察和建议。 年薪70 ...
2025-01-24又到一年年终时,各位打工人也迎来了展示成果的关键时刻 —— 年终述职。一份出色的年终述职报告,不仅能全面呈现你的工作价值, ...
2025-01-23“用户旅程分析”概念 用户旅程图又叫做用户体验地图,它是用于描述用户在与产品或服务互动的过程中所经历的各个阶段、触点和情 ...
2025-01-22在竞争激烈的商业世界中,竞品分析对于企业的发展至关重要。今天,我们就来详细聊聊数据分析师写竞品分析的那些事儿。 一、明确 ...
2025-01-22






